-
Feature Request
-
Resolution: Done
-
 Minor
Minor
-
None
-
None
-
Product / Portfolio Work
-
None
-
False
-
-
None
-
None
-
-
-
None
-
-
None
-
None
-
None
Proposed title of this feature request:
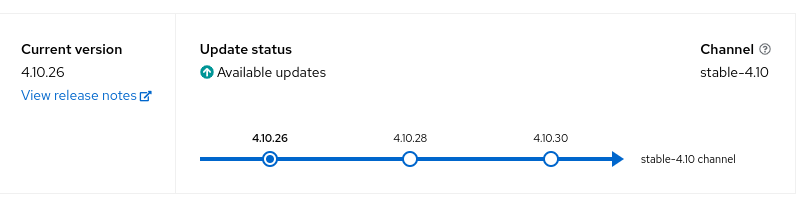
--> Intimate OCP users that the cluster in currently upgrading via a notification banner on the UI or an alert firing for the during of the upgrade.
What is the nature and description of the request?
--> Display a notification/banner throughout OCP web UI saying that the cluster is currently under upgrade.
--> Or have an alert firing for all the users of OCP stating the cluster is undergoing an upgrade.
Why does the customer need this? (List the business requirements here)
--> When cluster administrators perform an upgrade of the cluster this can have impact on the teams using the cluster. For example maven pods can be evicted from the node being upgraded leading to a failed build, causing teams to waste time investigating why their build failed. Applications will be restarted unexpectedly when they are evicted from the node being upgraded, causing teams to waste time investigating why their application restarted. Applications may experience issues after the upgrade was finished because of incompatibility
--> When cluster administrators perform an upgrade of the cluster this can have impact on the teams using the cluster. For example maven pods can be evicted from the node being upgraded leading to a failed build, causing teams to waste time investigating why their build failed. Applications will be restarted unexpectedly when they are evicted from the node being upgraded, causing teams to waste time investigating why their application restarted. Applications may experience issues after the upgrade was finished because of incompatibility
List any affected packages or components.
--> None, UX of developers working on the cluster when it undergoes an upgrade.

- is blocked by
-
OTA-768 Notify users when platform is undergoing upgrade
-
- Closed
-
-
CONSOLE-3252 Inform OCP users that the platform is performing an upgrade
-

- Closed
-