-
Feature Request
-
Resolution: Unresolved
-
 Normal
Normal
-
None
-
None
-
None
-
Product / Portfolio Work
-
None
-
False
-
-
None
-
None
-
-
-
None
-
-
None
-
None
-
None
1. Proposed title of this feature request
machine-config ClusterOperator stays Upgradeable=True as new nodes are added
2. What is the nature and description of the request?
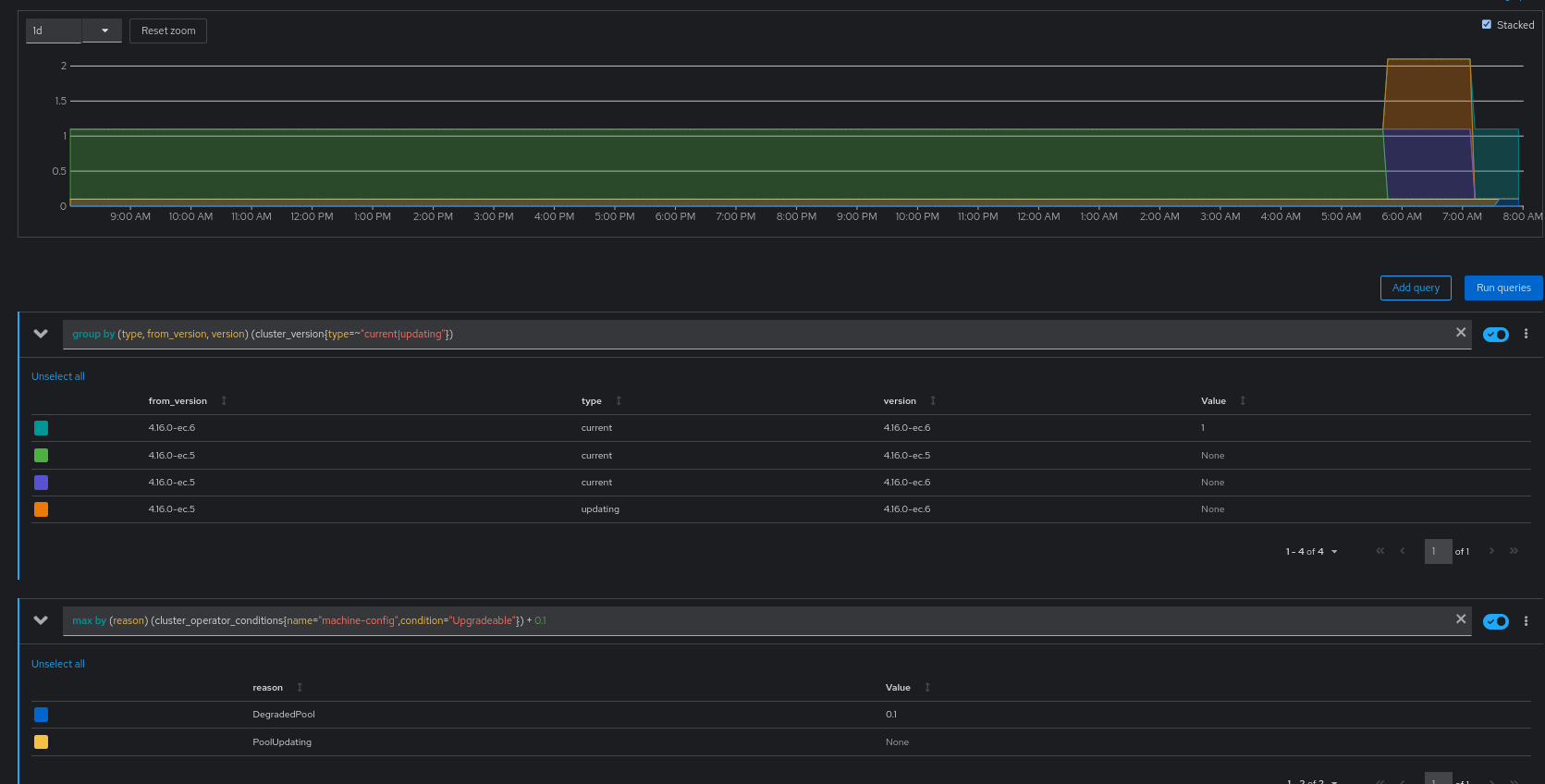
Autoscaled clusters may add and remove new nodes. At least in cases where the incoming/outgoing nodes match the current target MachineConfig, the machine-config ClusterOperator should stay Upgradeable=True so customers know that updates to 4.(y+1) are not at risk.
3. Why does the customer need this? (List the business requirements here)
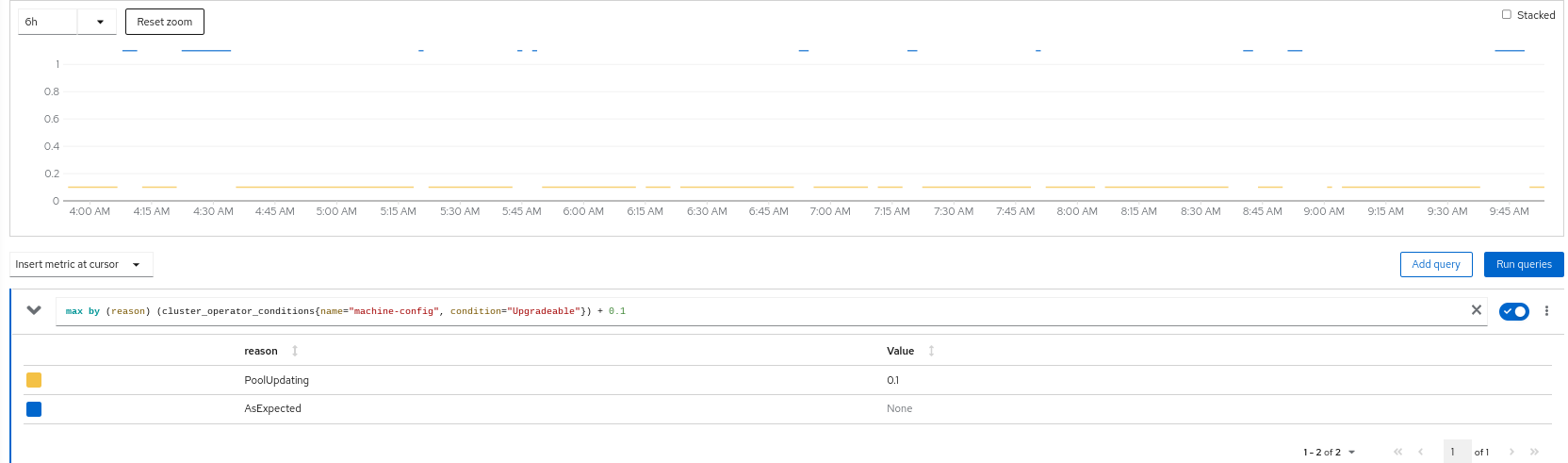
Today, the machine-config ClusterOperator goes Upgradeable=False when new nodes are added, with reason=PoolUpdating. However, in aggressively autoscaled clusters, this can make for very small windows of Upgradeable=True. There is no convenient knob for overriding Upgradeable=False guards when requesting minor updates from 4.y to 4.(y+1), aside from --force, which overrides other guards to (such as failed release signature checks). Delivering this RFE would reduce the barrier for minor updates for these bursty autoscaled clusters.
4. List any affected packages or components.
MCO.
Also, depending on how big a shift folks are willing to pick up, the main purpose of the PoolUpdating Upgradeable guard was to reduce excessive skew between compute nodes and the ClusterVersion target release. However, that skew is also addressed by kube-apiserver guards in 4.9, backported through 4.7.41. There is still a benefit to alerting for "hey, I'm really having trouble with this degraded pool", but the MCO may be able to get out of the Upgradeable side of this altogether.
- is related to
-
MCO-1482 machine-config ClusterOperator stays Upgradeable=True as new nodes are added
-
- Closed
-
-
OCPBUGS-56516 machine-config ClusterOperator stays Upgradeable=True as new nodes are added
-
- Closed
-
- relates to
-
-
- Closed
-