-
Bug
-
Resolution: Unresolved
-
 Major
Major
-
None
-
5.0.7.Final
-
None
-
AsyncBufferedMessageBodyWriter class creates ByteArrayOutputStream object with a byte[] array named buf in it. This byte[] is initialized with 32 size i.e, byte[32].
The UTF8JsonGenerator flushes the data in parts/chunks of 8000 bytes into the OutputStream which is the bos object. The byte array buf’s total capacity is only 32, the buf array grows itself to accommodate the 8000 bytes capacity.How does the buf byte array grows:
Below are the two variables of the ByteArrayOutputStream class.public class ByteArrayOutputStream extends OutputStream { /** * The buffer where data is stored. */ protected byte buf[]; /** * The number of valid bytes in the buffer. */ protected int count; . . . }
Condition for the buf byte[] to grow:
It doubles its original capacity, still if it can’t accommodate the data, then a new byte[] initialized with the size = count + data to be written as its capacity.Let’s see an example of how a 100kb data is processed using Async write. (sizes shown here are approximate but almost equal to the actual processing)
Total data to be written : 100000 bytes (100kb)Heading 1 Heading 2 Col A1 Col A2 bos variables outputBuffer
data capacitypseudo code for buf byte[] growth Garbage count = 0
byte[32]7011
(Initial flush from
UTF8Generator
will write 7011 bytes,
post which
all the flush
will write 8000 bytes )capacity required = 7011
if (buf has capacity):
writes the data in buf
else:
#Calculate new capacity
newCapacity = 32 * 2 = 64
#Check if newCapacity is less than 7011
if newCapacity < 7011:
newCapacity = 7011
#Resize the buf array
buf = Arrays.copyOf(buf,newCapacity)#Update count
count = 7011|byte[32]|count = 7011
byte[7011]8000 capacity required = 7011 + 8000 = 15011
newCapacity = 7011 * 2 = 14022
if newCapacity < 15011:
newCapacity = 15011
buf = Arrays.copyOf(buf, newCapacity)
count = 15011byte[7011] count = 15011
byte[15011]8000 capacity required = 23011
newCapacity = 15011 * 2
newCapacity = 30022
buf = Arrays.copyOf(buf, newCapacity)
count = 23011byte[15011] count = 23011
byte[30022]8000 capacity required = 31022
newCapacity = 30022 * 2
newCapacity = 60044
buf = Arrays.copyOf(buf, newCapacity)
count = 31022byte[30022] count = 31022
byte[60044]8000 capacity required = 39022
#writes the data in buf
buf = Arrays.copyOf(buf, newCapacity)
count = 39022count = 39022
byte[60044]8000 capacity required = 47022
#writes the data in buf
count = 47022count = 47022
byte[60044]8000 capacity required = 55022
#writes the data in buf
count = 55022count = 55022
byte[60044]8000 capacity required = 63022
newCapacity = 60044 * 2
newCapacity = 120088
buf = Arrays.copyOf(buf, newCapacity)
count = 63022byte[60044] count = 63022
byte[120088]8000 capacity required = 71022
newCapacity = 64000 * 2
newCapacity = 128000
buf = Arrays.copyOf(buf, newCapacity)
count = 71022byte[120088] Process continues until all the response data has been transferred to byte[] array(buf)
Buffer growth is not required anymore as it can accommodate up to 120kb.Total Garbage generated is ~112120 bytes (112 kb).
The above process writes the entire data bytes which is 80kb in the ByteArrayOutputStreambos object’s buf byte[] array.
Currently, ByteArrayOutputStream bos object’s buf byte[120088] array has 120088 capacity but the actual data in it is only 100000 bytes.
Hence a copy/slice of the buf array from 0 to 100000 bytes is taken and the newly created byte[100000] with capacity 100000 is sent to the Tomcat server to write the data in the socket.
In order to write a 100kb response data,
- Garbage create while writing buf array - 112kb
- Final buf array capacity - 120kb
- copy of the byte array sent to Tomcat - 100kb
Totally 332 kb of garbage is created in order to write 80kb data. This is the main cause of memory increase when Async writer is used.
Whereas in Sync writer, there is no additional garbage created, the BufferRecycler from the UTF8JsonGenerator takes care of writing the response data in chunks of 8000 bytes almost to the very end in the Tomcat server until it writes to the DirectByteBuffer which then transfer the data to the socket.
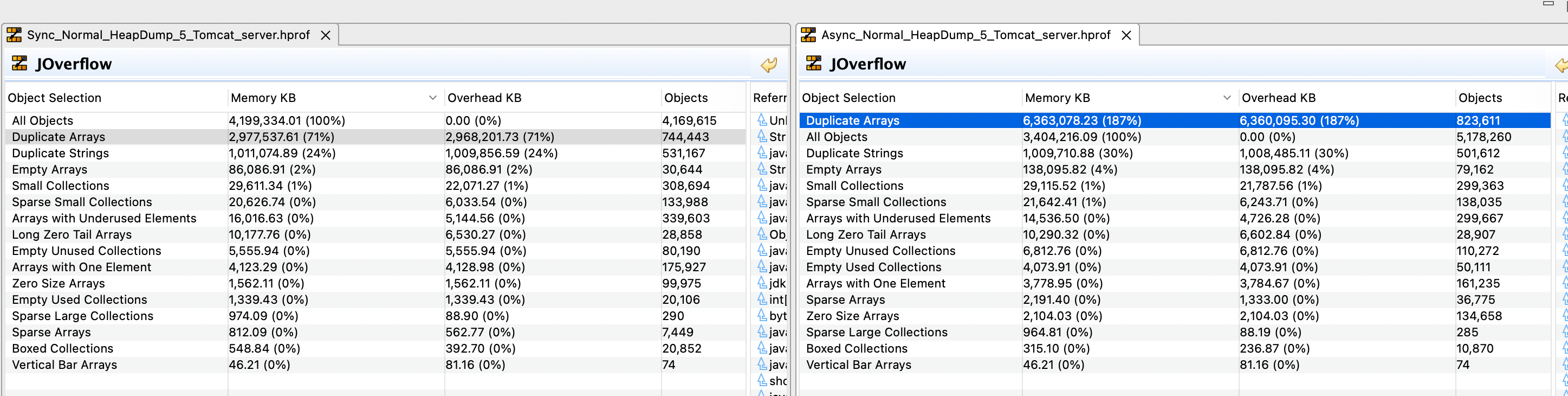
In the below screenshot, we can see that a large memory is occupied in the form of duplicated arrays when using Async writers.

On examining the duplicated arrays present, we can see byte[32], byte[7011], byte[15011], byte[30022], byte[60044], byte[120088], byte[100013] arrays are additionally present when using the Async write(right side in the screenshot).
Objects count represented in the screenshot is 10000, since 10000 requests are made and captured the heap dump.
 AsyncBufferedMessageBodyWriter class creates ByteArrayOutputStream object with a byte[] array named buf in it. This byte[] is initialized with 32 size i.e, byte [32] . The UTF8JsonGenerator flushes the data in parts/chunks of 8000 bytes into the OutputStream which is the bos object. The byte array buf’s total capacity is only 32, the buf array grows itself to accommodate the 8000 bytes capacity. How does the buf byte array grows: Below are the two variables of the ByteArrayOutputStream class. public class ByteArrayOutputStream extends OutputStream { /** * The buffer where data is stored. */ protected byte buf[]; /** * The number of valid bytes in the buffer. */ protected int count; . . . } Condition for the buf byte[] to grow: It doubles its original capacity, still if it can’t accommodate the data, then a new byte[] initialized with the size = count + data to be written as its capacity. Let’s see an example of how a 100kb data is processed using Async write. (sizes shown here are approximate but almost equal to the actual processing) Total data to be written : 100000 bytes (100kb) Heading 1 Heading 2 Col A1 Col A2 bos variables outputBuffer data capacity pseudo code for buf byte[] growth Garbage count = 0 byte [32] 7011 (Initial flush from UTF8Generator will write 7011 bytes, post which all the flush will write 8000 bytes ) capacity required = 7011 if (buf has capacity): writes the data in buf else: #Calculate new capacity newCapacity = 32 * 2 = 64 #Check if newCapacity is less than 7011 if newCapacity < 7011: newCapacity = 7011 #Resize the buf array buf = Arrays.copyOf(buf,newCapacity) #Update count count = 7011|byte [32] | count = 7011 byte [7011] 8000 capacity required = 7011 + 8000 = 15011 newCapacity = 7011 * 2 = 14022 if newCapacity < 15011: newCapacity = 15011 buf = Arrays.copyOf(buf, newCapacity) count = 15011 byte [7011] count = 15011 byte [15011] 8000 capacity required = 23011 newCapacity = 15011 * 2 newCapacity = 30022 buf = Arrays.copyOf(buf, newCapacity) count = 23011 byte [15011] count = 23011 byte [30022] 8000 capacity required = 31022 newCapacity = 30022 * 2 newCapacity = 60044 buf = Arrays.copyOf(buf, newCapacity) count = 31022 byte [30022] count = 31022 byte [60044] 8000 capacity required = 39022 #writes the data in buf buf = Arrays.copyOf(buf, newCapacity) count = 39022 count = 39022 byte [60044] 8000 capacity required = 47022 #writes the data in buf count = 47022 count = 47022 byte [60044] 8000 capacity required = 55022 #writes the data in buf count = 55022 count = 55022 byte [60044] 8000 capacity required = 63022 newCapacity = 60044 * 2 newCapacity = 120088 buf = Arrays.copyOf(buf, newCapacity) count = 63022 byte [60044] count = 63022 byte [120088] 8000 capacity required = 71022 newCapacity = 64000 * 2 newCapacity = 128000 buf = Arrays.copyOf(buf, newCapacity) count = 71022 byte [120088] Process continues until all the response data has been transferred to byte[] array(buf) Buffer growth is not required anymore as it can accommodate up to 120kb. Total Garbage generated is ~112120 bytes (112 kb). The above process writes the entire data bytes which is 80kb in the ByteArrayOutputStream bos object’s buf byte[] array. Currently, ByteArrayOutputStream bos object’s buf byte [120088] array has 120088 capacity but the actual data in it is only 100000 bytes. Hence a copy/slice of the buf array from 0 to 100000 bytes is taken and the newly created byte [100000] with capacity 100000 is sent to the Tomcat server to write the data in the socket. In order to write a 100kb response data, Garbage create while writing buf array - 112kb Final buf array capacity - 120kb copy of the byte array sent to Tomcat - 100kb Totally 332 kb of garbage is created in order to write 80kb data. This is the main cause of memory increase when Async writer is used. Whereas in Sync writer, there is no additional garbage created, the BufferRecycler from the UTF8JsonGenerator takes care of writing the response data in chunks of 8000 bytes almost to the very end in the Tomcat server until it writes to the DirectByteBuffer which then transfer the data to the socket. In the below screenshot, we can see that a large memory is occupied in the form of duplicated arrays when using Async writers. On examining the duplicated arrays present, we can see byte [32] , byte [7011] , byte [15011] , byte [30022] , byte [60044] , byte [120088] , byte [100013] arrays are additionally present when using the Async write(right side in the screenshot). Objects count represented in the screenshot is 10000, since 10000 requests are made and captured the heap dump.
AsyncBufferedMessageBodyWriter class creates ByteArrayOutputStream object with a byte[] array named buf in it. This byte[] is initialized with 32 size i.e, byte [32] . The UTF8JsonGenerator flushes the data in parts/chunks of 8000 bytes into the OutputStream which is the bos object. The byte array buf’s total capacity is only 32, the buf array grows itself to accommodate the 8000 bytes capacity. How does the buf byte array grows: Below are the two variables of the ByteArrayOutputStream class. public class ByteArrayOutputStream extends OutputStream { /** * The buffer where data is stored. */ protected byte buf[]; /** * The number of valid bytes in the buffer. */ protected int count; . . . } Condition for the buf byte[] to grow: It doubles its original capacity, still if it can’t accommodate the data, then a new byte[] initialized with the size = count + data to be written as its capacity. Let’s see an example of how a 100kb data is processed using Async write. (sizes shown here are approximate but almost equal to the actual processing) Total data to be written : 100000 bytes (100kb) Heading 1 Heading 2 Col A1 Col A2 bos variables outputBuffer data capacity pseudo code for buf byte[] growth Garbage count = 0 byte [32] 7011 (Initial flush from UTF8Generator will write 7011 bytes, post which all the flush will write 8000 bytes ) capacity required = 7011 if (buf has capacity): writes the data in buf else: #Calculate new capacity newCapacity = 32 * 2 = 64 #Check if newCapacity is less than 7011 if newCapacity < 7011: newCapacity = 7011 #Resize the buf array buf = Arrays.copyOf(buf,newCapacity) #Update count count = 7011|byte [32] | count = 7011 byte [7011] 8000 capacity required = 7011 + 8000 = 15011 newCapacity = 7011 * 2 = 14022 if newCapacity < 15011: newCapacity = 15011 buf = Arrays.copyOf(buf, newCapacity) count = 15011 byte [7011] count = 15011 byte [15011] 8000 capacity required = 23011 newCapacity = 15011 * 2 newCapacity = 30022 buf = Arrays.copyOf(buf, newCapacity) count = 23011 byte [15011] count = 23011 byte [30022] 8000 capacity required = 31022 newCapacity = 30022 * 2 newCapacity = 60044 buf = Arrays.copyOf(buf, newCapacity) count = 31022 byte [30022] count = 31022 byte [60044] 8000 capacity required = 39022 #writes the data in buf buf = Arrays.copyOf(buf, newCapacity) count = 39022 count = 39022 byte [60044] 8000 capacity required = 47022 #writes the data in buf count = 47022 count = 47022 byte [60044] 8000 capacity required = 55022 #writes the data in buf count = 55022 count = 55022 byte [60044] 8000 capacity required = 63022 newCapacity = 60044 * 2 newCapacity = 120088 buf = Arrays.copyOf(buf, newCapacity) count = 63022 byte [60044] count = 63022 byte [120088] 8000 capacity required = 71022 newCapacity = 64000 * 2 newCapacity = 128000 buf = Arrays.copyOf(buf, newCapacity) count = 71022 byte [120088] Process continues until all the response data has been transferred to byte[] array(buf) Buffer growth is not required anymore as it can accommodate up to 120kb. Total Garbage generated is ~112120 bytes (112 kb). The above process writes the entire data bytes which is 80kb in the ByteArrayOutputStream bos object’s buf byte[] array. Currently, ByteArrayOutputStream bos object’s buf byte [120088] array has 120088 capacity but the actual data in it is only 100000 bytes. Hence a copy/slice of the buf array from 0 to 100000 bytes is taken and the newly created byte [100000] with capacity 100000 is sent to the Tomcat server to write the data in the socket. In order to write a 100kb response data, Garbage create while writing buf array - 112kb Final buf array capacity - 120kb copy of the byte array sent to Tomcat - 100kb Totally 332 kb of garbage is created in order to write 80kb data. This is the main cause of memory increase when Async writer is used. Whereas in Sync writer, there is no additional garbage created, the BufferRecycler from the UTF8JsonGenerator takes care of writing the response data in chunks of 8000 bytes almost to the very end in the Tomcat server until it writes to the DirectByteBuffer which then transfer the data to the socket. In the below screenshot, we can see that a large memory is occupied in the form of duplicated arrays when using Async writers. On examining the duplicated arrays present, we can see byte [32] , byte [7011] , byte [15011] , byte [30022] , byte [60044] , byte [120088] , byte [100013] arrays are additionally present when using the Async write(right side in the screenshot). Objects count represented in the screenshot is 10000, since 10000 requests are made and captured the heap dump.

AsyncBufferedMessageBodyWriter is used by default in RestEasy for performing async response write. AsyncBufferedMessageBodyWriter has ByteArrayOutputStream as the OutputStream, which consumes more garbage and, in turn, increases the number of GCs occurring in the application.
For a 80KB response data, the {{ByteArrayOutputStream }}alone generates around 330kb of garbage.
ByteArrayOutputStream continuously grows the byte[] array (buf) in it to accommodate the space for the response data. This continuous growth creates around 120kb of garbage to write a 80kb response data.
Once all the data has been saved in ByteArrayOutputStream's byte[] array(buf)
a copy/slice of the byte[] array(buf) is made to select the valid data from the byte[] array(buf). The original byte[] array(buf) will be around 120kb in size and the sliced new byte[] will be 80kb (valid response data). The valid response data byte[] is only passed on to the Tomcat server for writing the data in the socket and at the end discarded.
So a total of 330kb garbage is generated in the async write process.