Description of problem:
When create a auto-pruning policy with pattern character "\b" or "\B", the tags matched the pattern can't be pruned.
Version-Release number of selected component (if applicable):
//quay-operator-bundle-container-v3.13.0-42 ------------------------------ registry.redhat.io/quay/quay-operator-rhel8@sha256:3994cb70eadb21acb43489055b53a4281d01f3be9c08db9b21d1f29e8317862c ------------------------------ registry.redhat.io/quay/quay-rhel8@sha256:f76f8a6aed66adc1327f5365250d47d811f844e628e0d1f876d6bbf93c4b23dd
Steps to reproduce:
1 deployed quay with below configuration
FEATURE_AUTO_PRUNE: true AUTOPRUNE_TASK_RUN_MINIMUM_INTERVAL_MINUTES: 1 CREATE_NAMESPACE_ON_PUSH: true FEATURE_USERNAME_CONFIRMATION: false FEATURE_UI_V2: true
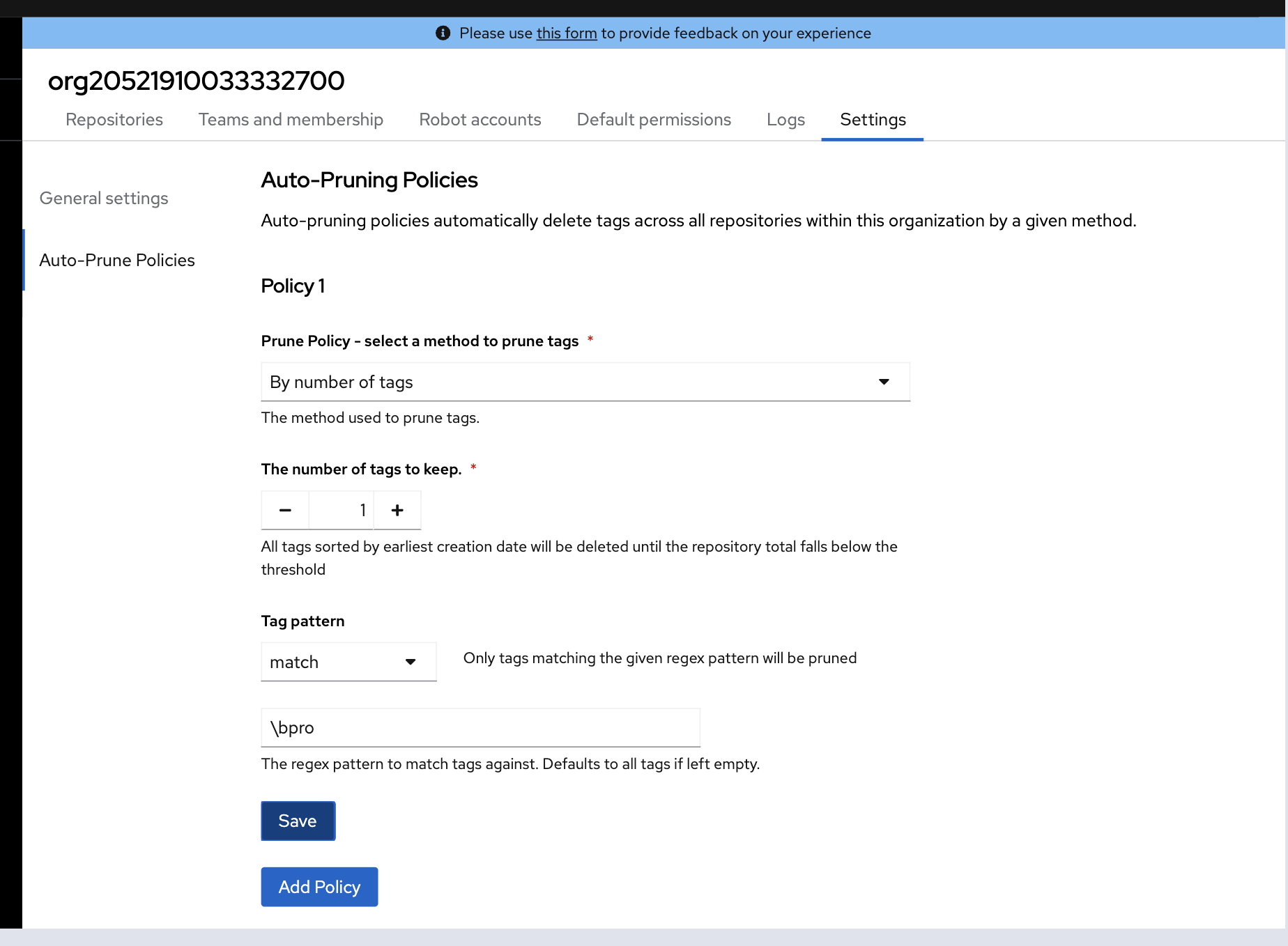
2 Create a repository and create auto-pruning policy in organization setting
The auto-pruning policy
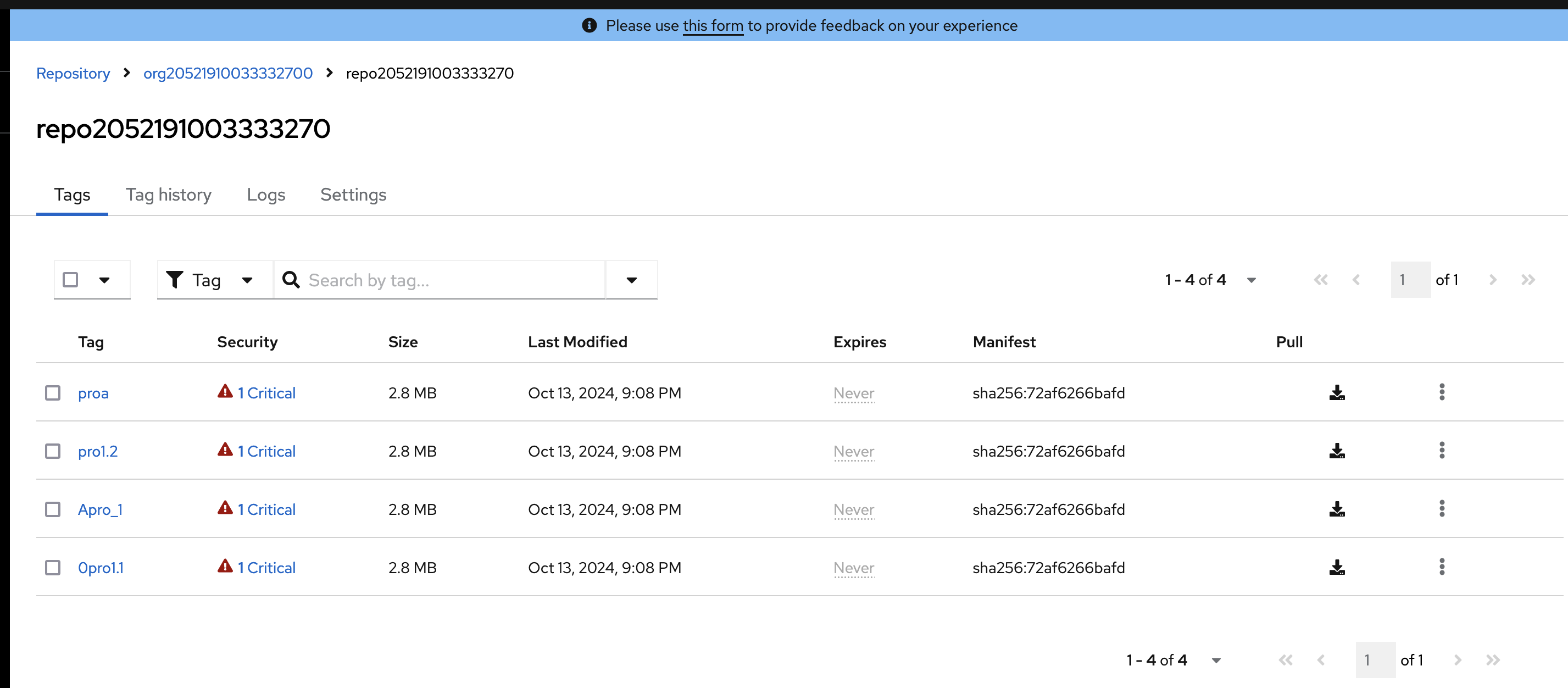
2 Push images to this repository with tags "0pro1.1","Apro_1","pro1.2","proa" one by one.
The original tags

3. wait for a while and check the tags remained.
Actual results:
There is no any tag be pruned.
The tags after 5 minutes
Expected results
The tag "pro1.2" should be pruned.
Additional information:
The regex pattern "\B" has the same problem.
Depending on Regular expression operations document, '\b' and '\B' are described like
\b Matches the empty string, but only at the beginning or end of a word. A word is defined as a sequence of word characters. Note that formally, \b is defined as the boundary between a \w and a \W character (or vice versa), or between \w and the beginning or end of the string. This means that r'\bat\b' matches 'at', 'at.', '(at)', and 'as at ay' but not 'attempt' or 'atlas'. \B Matches the empty string, but only when it is not at the beginning or end of a word. This means that r'at\B' matches 'athens', 'atom', 'attorney', but not 'at', 'at.', or 'at!'.
Check the pattern with python code
#!/usr/bin/python3 import re def check_pattern(tags, pattern): print("\n------------------------") print(tags) print("pattern: "+ pattern) print(".............") for tag in tags: print(tag) matchObj = re.search(pattern , tag) if matchObj: print (" match: " + matchObj.group()) else: print (" No match!!") check_pattern(["0pro1.1","Apro_1","pro1.2","proa"], r'\bpro') check_pattern(["Apro","1pro","pro1.1","pro_1"], r'pro\B')
Get the results
------------------------ ['0pro1.1', 'Apro_1', 'pro1.2', 'proa'] pattern: \bpro ............. 0pro1.1 No match!! Apro_1 No match!! pro1.2 match: pro proa match: pro ------------------------ ['Apro', '1pro', 'pro1.1', 'pro_1'] pattern: pro\B ............. Apro No match!! 1pro No match!! pro1.1 match: pro pro_1 match: pro