-
Bug
-
Resolution: Unresolved
-
 Normal
Normal
-
None
-
quay-v3.8.8
-
False
-
-
False
-
Quay Enterprise
-
-
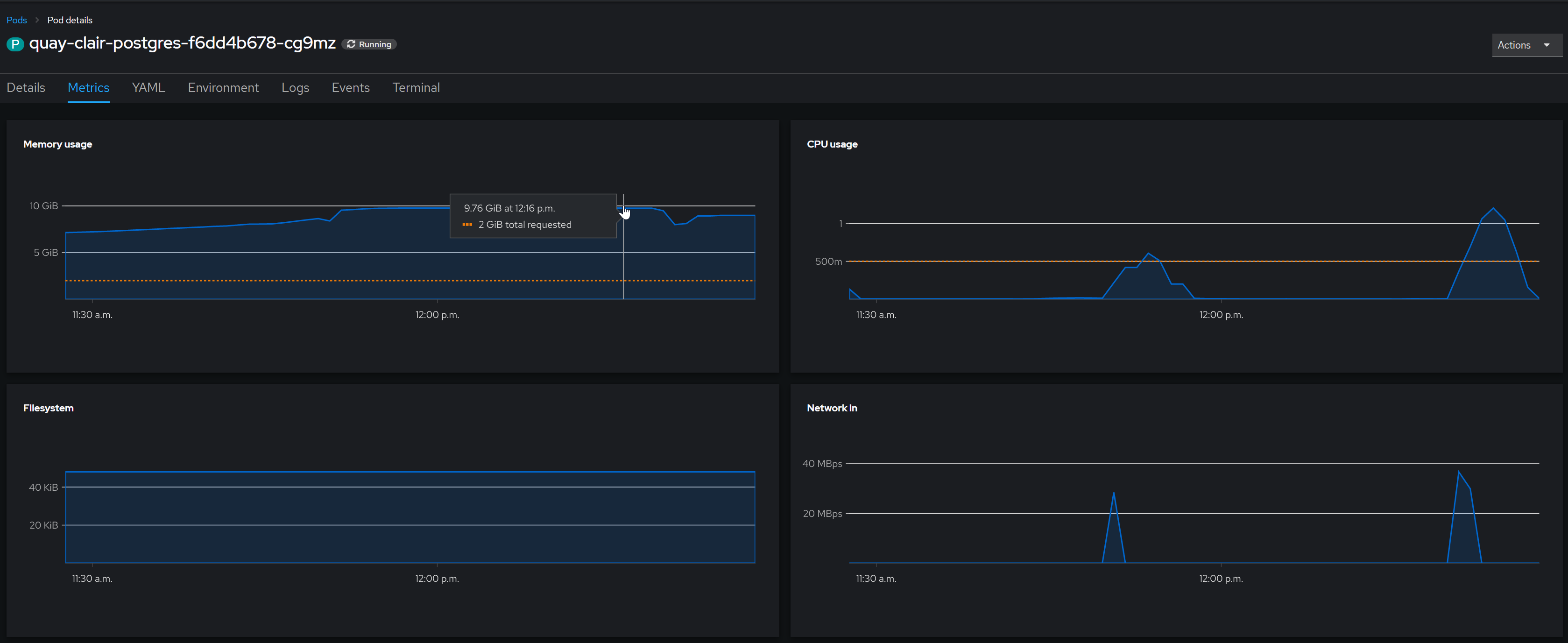
When Quay is deployed with default options, the operator also deploys Clair's PostgreSQL database. This database experiences a very high memory consumption after a while, even when running on a completely new cluster, with 0 images stored in Quay. These are the recorded PostgreSQL metrics for Clair's database after approximately 2 hours of running:
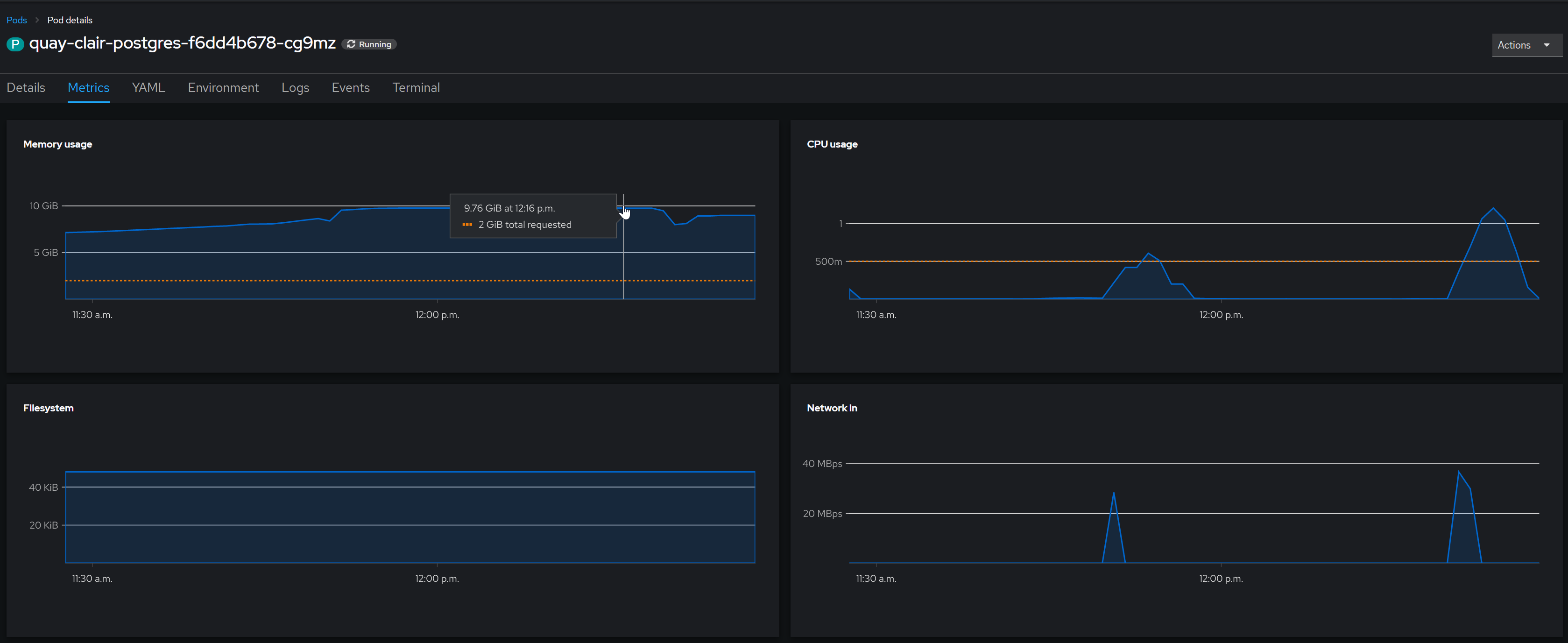
Database memory consumption peaked at around 10 GB, and has stabilized at around 9 GB afterwards. The drops in memory consumption seem to correlate with the upgrade operations done on the CVE database. Even after scaling Clair pods down to 0, the memory consumption still stays high, presumably due to caching.
Clair configuration is completely vanilla:
auth: psk: iss: - quay - clairctl key: YlB0enJIdUl6UkJWNFhJeXBqUDhvSmFHRElGNkpNN0M= http_listen_addr: :8080 indexer: connstring: host=quay-clair-postgres port=5432 dbname=postgres user=postgres password=postgres sslmode=disable pool_max_conns=10 layer_scan_concurrency: 5 migrations: true scanlock_retry: 10 log_level: info matcher: connstring: host=quay-clair-postgres port=5432 dbname=postgres user=postgres password=postgres sslmode=disable pool_max_conns=10 migrations: true metrics: name: prometheus notifier: connstring: host=quay-clair-postgres port=5432 dbname=postgres user=postgres password=postgres sslmode=disable pool_max_conns=10 delivery_interval: 1m0s migrations: true poll_interval: 5m0s webhook: callback: http://quay-clair-app/notifier/api/v1/notifications target: https://quay-quay-quay-enterprise.apps.quay-reproducer.emea.aws.cee.support/secscan/notification
The database memory consumption is substantially lower after pod restart, which again points to caching of very large data pools being the primary culprit. Unfortunately, we cannot modify the PostgreSQL configuration as it's deployed by the operator. We also had several clients having the same issue, with one client seeing frequent PostgreSQL database pod evictions due to memory consumption.
❯ oc get events --sort-by='.lastTimestamp' | grep memory
136m Warning Evicted pod/quay-clair-postgres-848cc8669-jtfnk The node was low on resource: memory. Container postgres was using 8050612Ki, which exceeds its request of 2Gi.
135m Warning Evicted pod/quay-clair-postgres-848cc8669-jtfnk The node was low on resource: memory. Container postgres was using 7954716Ki, which exceeds its request of 2Gi.
134m Warning Evicted pod/quay-clair-postgres-848cc8669-jtfnk The node was low on resource: memory. Container postgres was using 7615348Ki, which exceeds its request of 2Gi.
48m Warning Evicted pod/quay-clair-postgres-848cc8669-9zqg2 The node was low on resource: memory. Container postgres was using 8585172Ki, which exceeds its request of 2Gi.
48m Warning Evicted pod/quay-clair-postgres-848cc8669-9zqg2 The node was low on resource: memory. Container postgres was using 8050704Ki, which exceeds its request of 2Gi.
47m Warning Evicted pod/quay-clair-postgres-848cc8669-9zqg2 The node was low on resource: memory. Container postgres was using 8048204Ki, which exceeds its request of 2Gi.
46m Warning Evicted pod/quay-clair-postgres-848cc8669-9zqg2 The node was low on resource: memory. Container postgres was using 8046660Ki, which exceeds its request of 2Gi.
46m Warning Evicted pod/quay-clair-postgres-848cc8669-9zqg2 The node was low on resource: memory. Container postgres was using 8046664Ki, which exceeds its request of 2Gi.
The issue has already been reported in another JIRA.
Please check, thank you!