Details
-
Enhancement
-
Resolution: Unresolved
-
 Major
Major
-
7.0.0.CR3
-
NEW
-
NEW
Description
The slow solution cloning that is happening after every "new best score" made me think how to possibly improve it. I raised this question on StackOverflow for a possible improvement of the solution cloning. The first step that i took was implementing custom cloning, it was better than the default cloning but again for a large entity count it was really slow, taking up 99% of the time taken for a step (when a "new best score" occurs). As the problem gets bigger the "new best score" steps are a lot more frequent at the beginning (at least in the problem that i'm solving), so speeding this up became a must.
As described in the StackOverflow question one of the ideas was to do solution cloning in an incremental way, where only the entities that get changed by the step moves between two "new best score" steps would be cloned and updated in the best solution which would do a full clone only at the beginning (inspired by incremental score calculation).
Having a look at the core code for doing solution cloning i instantly realized that cloning would be needed once (only the full clone at the beginning) and than during the solving process it can just be *bestSolutionEntity.setPlanningVariable(workingSolutionEntity.getPlanningVariable()); *
The point here is that the entity objects in the working and best solution need to be different (clones) so that the error "The entity was never added to this score director" would not occur, the planning and shadow variables (the things that change during solving in the planning entities) don't need to be cloned, they are treated as planning facts and a reference both in the working and best solution is pointing to the exact same object.
So with full cloning the solution only once (talking about local search after the first step) and than doing this "get-set" logic i managed to achieve a tremendous difference in speed, even without having to edit the core. Below is the explanation how i implemented it:
- Adding a variable called "stepMove" as part of the solution class
- In the "doMoveOnGenuineVariables" method through the score director accessing the solution and updating this variable. We know that in a step there are a bunch of do and than undo moves that call this method but at the end of the step the step move gets played out. The reference to this move is remembered with using the special Java keyword "this" ("setStepMove(this);").
- By implementing a "PhaseLifecycleListenerAdapter" (not public API , used by the benchmarker) i was able to get access to the "stepEnded" method.This method is called after solution cloning is done so that is why the "stepMove" variable is updated all the time from the "doMoveOnGenuine" variables all the time. Here i first check is the best solution improved. If it is not improved than the "stepMove" is added to a so called "stepList" (which holds the "stepMoves" between two "new best score" steps), if the score is improved than solution cloning would be done and the value of the "stepMove" variable will be taken there (in the "planningClone" method of the solution class).
- Pseudo code for "planningClone" method
public Solution planningClone() { if(existsFullyClonedBestSolution() == false){ bestSolution = doFullClone(); return bestSolution; } else { /* incremental cloning comes into play when there is an already cloned best solution, which is after the first step in local search */ return updateOnlyVariablesThatAreAffectedByStepMoves(); } } /** Loops through all the step moves that happened between two "new best score" steps and for every move loops through all the planning entities it has changed and updates the planning and shadow variables that are part of them.*/ public Solution updateOnlyVariablesThatAreAffectedByStepMoves(){ /* In the logic below maybe the planning variable of a given entity would be set twice because it can be part of multiple moves from the "stepList" but that is not that worrying because a set operation is really quick and takes up basically really little time */ stepList.add(stepMove);// the move from the current step for(Move move : stepList){ for(Entity entity : move.getPlanningEntities()){ /*entity is referencing to an object from the working solution, the value that is set to any planning or shadow variables also needs to be updated in the best solution*/ bestSolutionEntityList = bestSolution.getEntityList(); int entityIndexInList = entity.getIndexInEntityList(); Entity bestSolutionCloneOfCurrentEntity = bestSolutionEntityList.get(entityIndexInList); bestSolutionCloneOfCurrentEntity.setPlanningVariableValue(entity.getPlanningVariableValue()); } } }
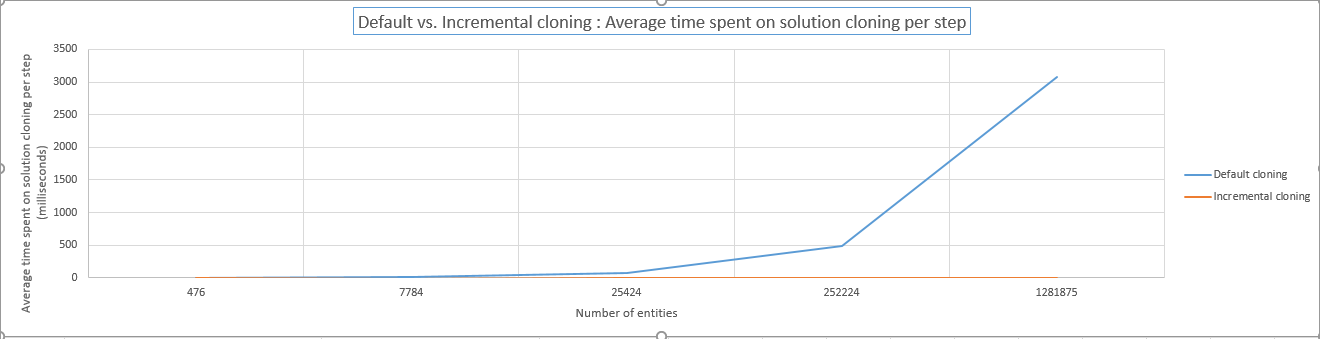
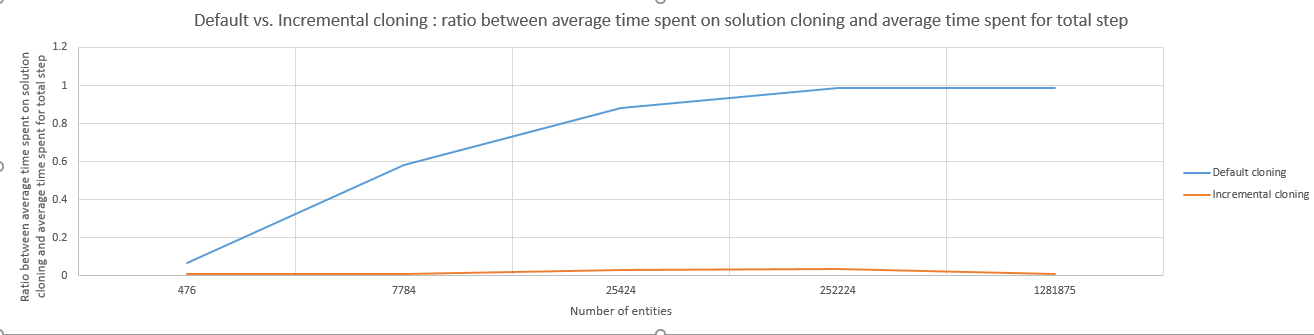
Attached are two graphs that compare the solution cloning speed in the two different implementations. As we can see from the "Average time spent on solution cloning" graph the average time spent on solution cloning in the default implementation increases as the number of entities increases but in the incremental implementation basically remains the same. Also from the "Ratio between average time spent on solution cloning and average time spent for total step" graph we can see that in the larger cases most of the time from a "new best score" step is taken up by the solution cloning process (in the default case).
Maybe the entity counts from the attached graphs are not something that has occurred to anyone until now and the solution cloning process was not a bottleneck and a point to search for an optimization but it was definitely somewhat of a problem for me. Nevertheless i guess there would be no harm in doing this improvement in a future version and make the default cloning process do a similar logic.
Attachments
Issue Links
- is duplicated by
-
PLANNER-2398 Incremental SolutionCloner
-
- Closed
-
