-
Story
-
Resolution: Done
-
 Major
Major
-
None
-
None
-
5
-
False
-
-
False
-
-
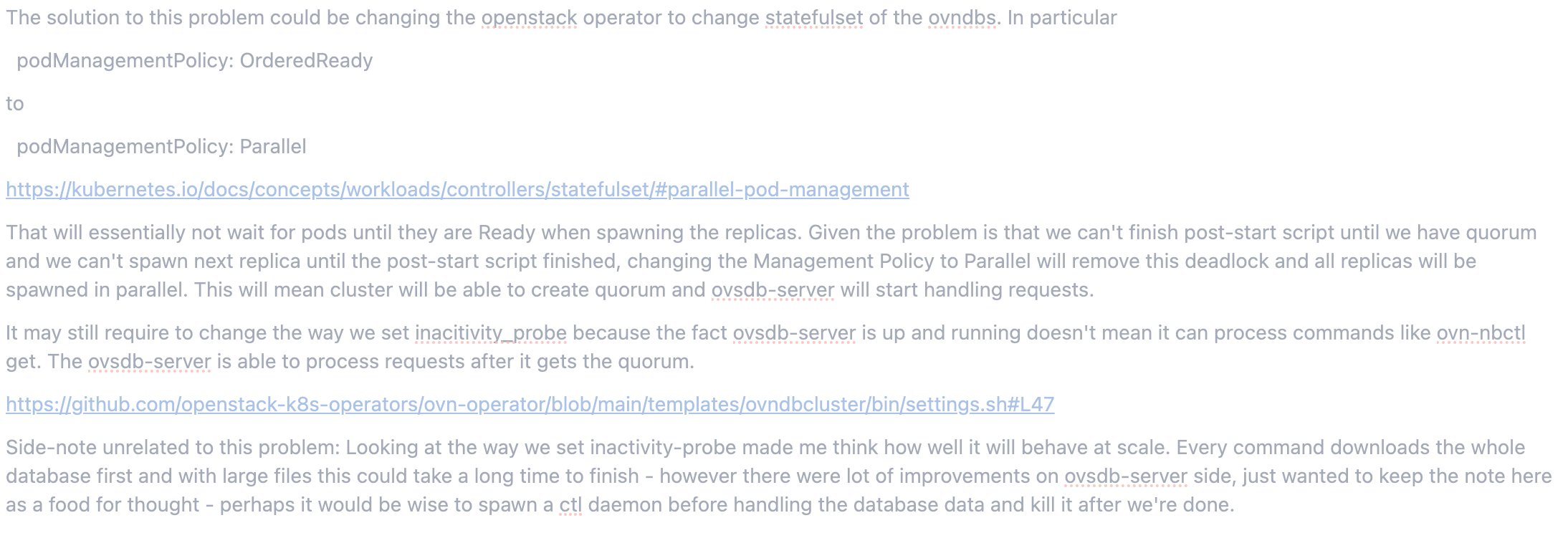
We are using cluster/leave[1] in post script of the dbcluster pods which would not work with pods non-graceful stop or worker node crash. We would need to handle this or atleast add a way to recover from such situations. It shouldn't be an issue with single pod db cluster(replicas: 1) but could be when there are more replicase(like 3+) and more than half(like 2+) of them crash.

{kind=link}