-
Bug
-
Resolution: Done
-
 Critical
Critical
-
rhos-18.0.10 FR 3
-
None
-
3
-
False
-
-
False
-
?
-
openstack-ceilometer-20.0.1-18.0.20251013174703.a0385d3.el9osttrunk
-
rhos-observability-telemetry
-
None
-
-
Release Note Not Required
-
-
-
-
Bug Delivery Tracker
-
1
-
Critical
To Reproduce Steps to reproduce the behavior:
- Create an openstack instance and wait for some minutes to start getting ceilometer metrics.
- Live-migrate the instance to a different node and make some activity.
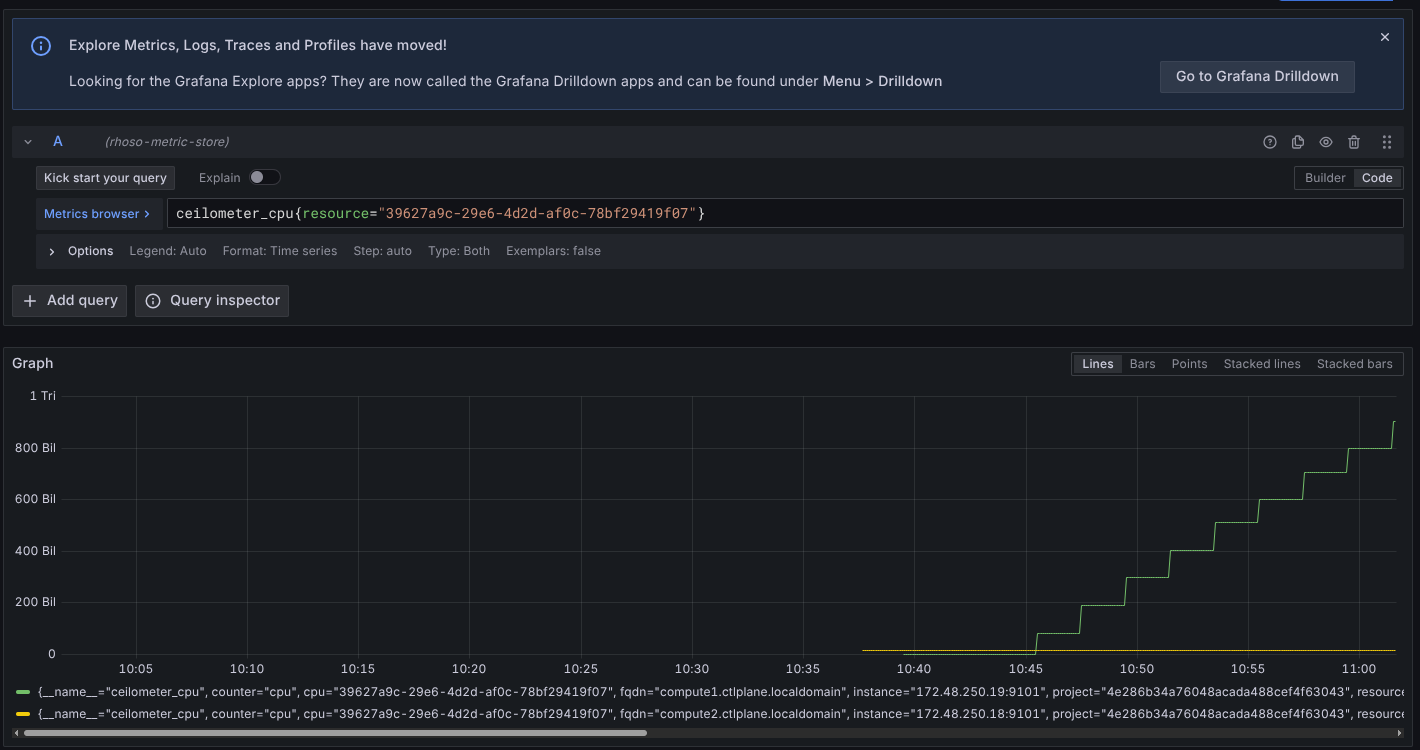
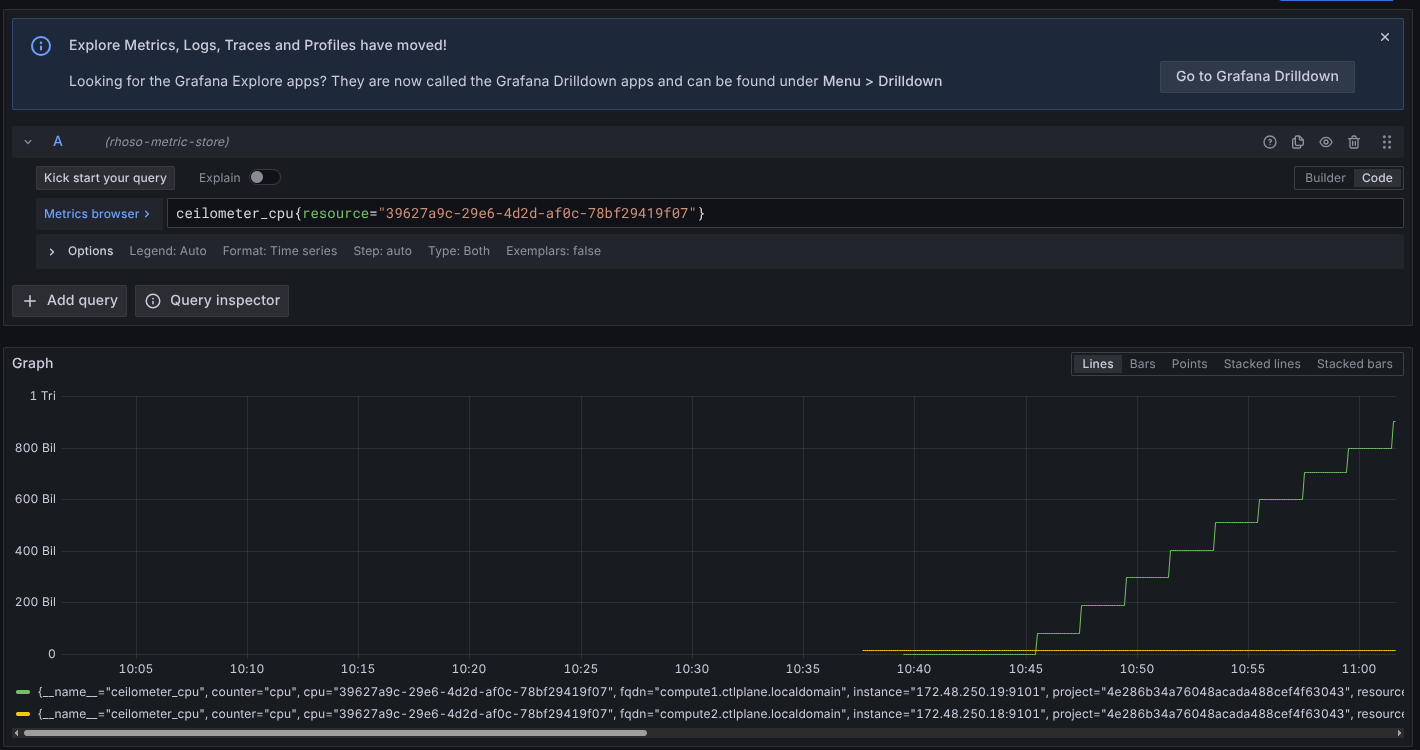
- Check ceilometer metrics for the instance, i.e. ceilometer_cpu. We keep getting measures for the instance in both nodes with different vm_instance label value, depending. For the node where it is running, we get real values and for the initial one we keep getting the last values generated when the instance was running which are not longer valid. This fakes the result of certain queries, i.e. `clamp_max((avg by (resource)(rate(ceilometer_cpu{resource='d0b40b5a-9254-4782-b798-14810d12cea3'}[300s]))/10e+8) *(100/1), 100)`
Expected behavior
- Measures for instances should be reported only from the node where the instance is actually running and no old metrics should be reported as current.
Screenshots
Bug impact
- This is impacting watcher optimizations as the metrics are not providing accurate real values.
Known workaround
- Please add any known workarounds.
Additional context
- Getting the metrics from different hosts ceilometer exporter returns values after the vm has been migrated.
[cloud-user@compute2 ~]$ sudo virsh list
Id Name State
--------------------
[cloud-user@compute2 ~]$ curl https://localhost:9101/metrics --insecure -s|grep ceilometer_cpu|grep 39627a9c-29e6-4d2d-af0c-78bf29419f07
ceilometer_cpu
1.535e+010
[cloud-user@compute2 ~]${code}