-
Feature
-
Resolution: Unresolved
-
 Critical
Critical
-
None
-
Product / Portfolio Work
-
-
47% To Do, 53% In Progress, 0% Done
-
-
False
-
None
-
False
-
L
-
Approved
-
-
-
-
-
-
None
-
-
Undefined
Feature Overview (aka. Goal Summary)
This feature aims to improve the user experience for cluster upgrades by providing more accurate and reliable status information for Cluster Operators.
To ensure that operators behave predictably during upgrades and other cluster lifecycle events, and thus reduce confusion about the upgrade process.
This will be achieved by enforcing new rules for operator behavior and tracking compliance to address common issues reported by customers.
A successful upgrade path for a given ClusterOperator should follow a specific pattern:
- Before Upgrade starts, Operators are in a healthy, stable state: Available=True, Progressing=False, Degraded=False.
- When Upgrade starts the operator should become Progressing=True as it works to apply the new version.
It should not become Degraded=True or Available=False.
- After Upgrade, the operator should return to a state of Progressing=False, with Available=True and Degraded=False.
Goals (aka. expected user outcomes)
As a cluster-admin I want to get accurate information about the status of cluster operators and monitor the upgrade process without encountering false alarms.
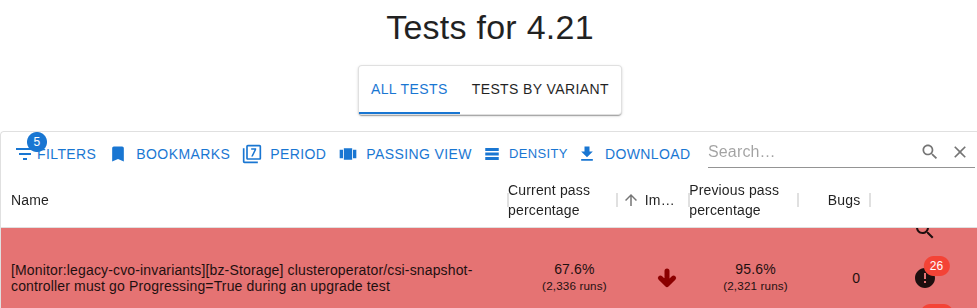
- ClusterOperator must not report Degrade=True or Available=False during the course of a normal upgrade. OCP bugs haven been filed in this area [1].
- Operators MUST go progressing when transitioning between versions (We will need to decide how to enforce it. Ideas are here). For now, this goal applies only to HA clusters.
- Operators MUST NOT re-enter progressing state when simply observing node lifecycle events such as scaleup/scaledown or reboots – primarily an issue for operators that observe DaemonSets continuously: bugs coming from
OTA-1637. - OCP bugs will be filed for the cluster operator that take too long to upgrade
OTA-1626.
Eventually, with these changes we should have Accurate status reporting, clear and clean upgrade progress information, Stable Operator status
- The bugs in a single Jira query grouped by Component: Bugs causing false alarms in ClusterOperator status during OpenShift upgrades
- The bugs in JIRA Dashboard: https://issues.redhat.com/secure/Dashboard.jspa?selectPageId=12390305 should be fixed to help improve UX of cluster upgrade.
- "Call for action: Implementing Cluster Operator Condition Rules to Improve Upgrade UX" is sent to the mailing list: openshift-eng@redhat.com
 and aos-devel@redhat.com.
and aos-devel@redhat.com. - Verification with Sippy of an OCP Bug on ClusterOperator's condition and Removal of its exception on the test is sent to the same mailing list as above.
New changed API rule
https://github.com/openshift/api/pull/2469/files
- A component must not report Available=False or Degrade=True during the course of a normal upgrade.
- A version change is a config change. Operators must go Progressing=True when transitioning between versions.
- Operators should not report Progressing only because DaemonSets owned by them are adjusting to a new node from cluster scaleup or a node rebooting from cluster upgrade.
- A component in a cluster with less than 250 nodes must complete a version change within a limited period of time: 90 minutes for Machine Config Operator and 20 minutes for others.
Deployment considerations{}
| Deployment considerations | List applicable specific needs (N/A = not applicable) |
| Self-managed, managed, or both | Both |
| Classic (standalone cluster) | Applicable |
| Hosted control planes | Applicable |
| Multi node, Compact (three node), or Single node (SNO), or all | All except upgrade on SNO about Available=False and Degraded=True |
| Connected / Restricted Network | Applicable |
| Architectures, e.g. x86_x64, ARM (aarch64), IBM Power (ppc64le), and IBM Z (s390x) | All |
| Operator compatibility | All core OpenShift operators |
| Backport needed (list applicable versions) | TBD based on release schedule and customer demand. |
| UI need (e.g. OpenShift Console, dynamic plugin, OCM) | The OpenShift Console Status command |
| Other (please specify) | N/A |
Documentation Considerations
explain the new operator status behavior during upgrades. Degraded or Unavailable status during an upgrade is now a sign of a problem, not just a temporary state. mention the time limits for operator updates.
Background:
This Feature is a continuation of OCPSTRAT-835.
Customers are asking for improvements to the upgrade experience (both over-the-air and disconnected). This is a feature tracking epics required to get that work done.
Action for each component team
- Deliver the fixes for the relevant OCP bugs to improve UX of cluster upgrade.
JIRA Dashboard : https://issues.redhat.com/secure/Dashboard.jspa?selectPageId=12390305 - project = "OpenShift Bugs" AND (issue in linkedIssues(TRT-1578) OR issue in linkedIssues(
OTA-362) OR issue in linkedIssues(OTA-1637)) ORDER BY assignee DESC, component
References
- clones
-
-

- Closed
-
- is blocked by
-
TRT-1578 Ensure all HA components are not degraded by design during upgrades
-
- New
-
-
-

- In Progress
-
- is cloned by
-
-
- New
-
- is depended on by
-
-
- New
-
- is related to
-
OTA-980 Is the Failing=True status condition is a good indicator for admins?
-
- To Do
-
- relates to
-
-

- In Progress
-
- links to