-
Story
-
Resolution: Unresolved
-
 Undefined
Undefined
-
None
-
None
-
None
-
None
-
False
-
-
False
-
None
-
None
-
None
-
None
-
None
User Story
As a user, I want to know when a MachineSet is having trouble scaling, so that I can figure out what's going on and fix it. Because otherwise it is difficult to distinguish scheduling failures due to slow scaleups from scheduling failures do to no scaling at all.
Background
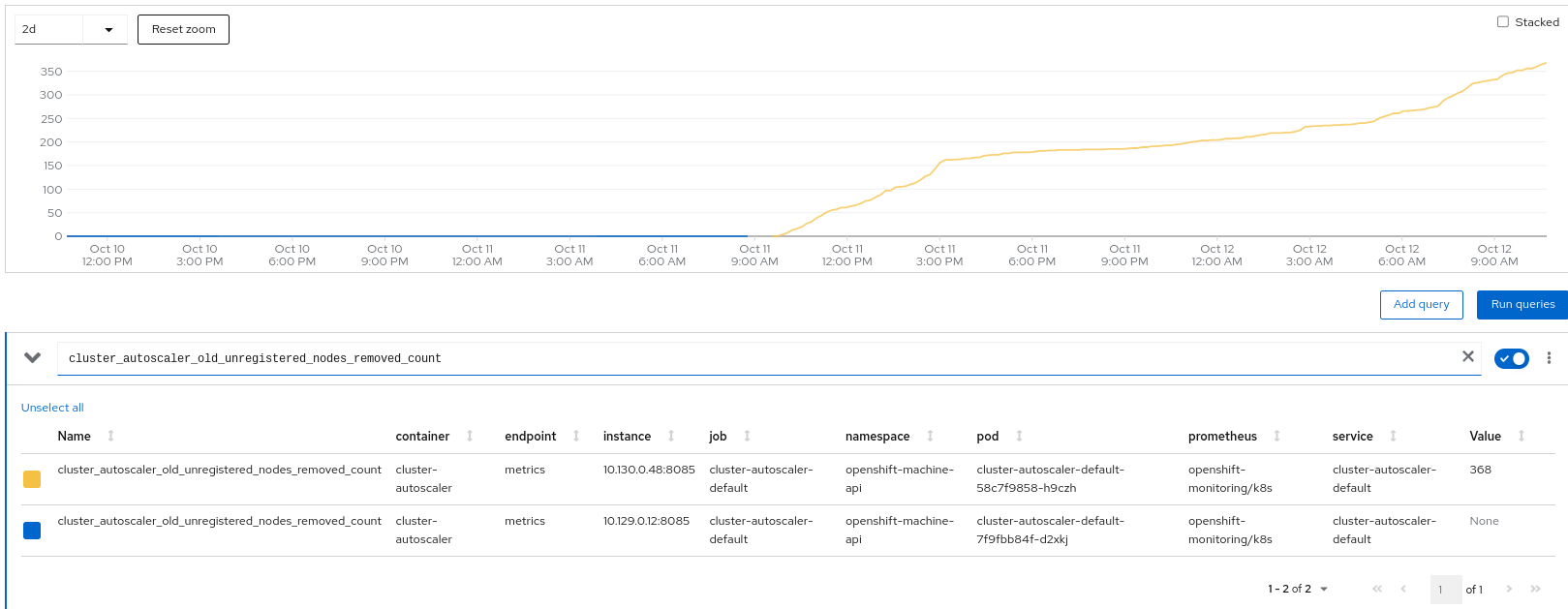
Seen in an 4.12.0-ec.3 to 4.12.0-ec.4 update:
$ oc -n openshift-machine-api get -o json events | jq -r '[.items[] | select(tostring | contains("MachineSet")) | .ts = .firstTimestamp // .metadata.creationTimestamp] | sort_by(.ts)[] | .ts + " " + (.count | tostring) + " " + (.involvedObject | .kind + " " + .name) + " " + .reason + ": " + .message' | tail
2022-10-11T17:54:21Z 1 ConfigMap cluster-autoscaler-status ScaleUpTimedOut: Nodes added to group MachineSet/openshift-machine-api/build0-gstfj-ci-builds-worker-b failed to register within 15m28.122543246s
2022-10-11T18:00:17Z 1 ConfigMap cluster-autoscaler-status ScaleUpTimedOut: Nodes added to group MachineSet/openshift-machine-api/build0-gstfj-ci-prowjobs-worker-b failed to register within 15m25.918752699s
2022-10-11T18:07:33Z 1 ConfigMap cluster-autoscaler-status ScaleUpTimedOut: Nodes added to group MachineSet/openshift-machine-api/build0-gstfj-ci-tests-worker-d failed to register within 15m26.371318304s
2022-10-11T18:15:52Z 1 ConfigMap cluster-autoscaler-status ScaleUpTimedOut: Nodes added to group MachineSet/openshift-machine-api/build0-gstfj-ci-builds-worker-b failed to register within 15m6.180555101s
2022-10-11T18:28:01Z 1 ConfigMap cluster-autoscaler-status ScaleUpTimedOut: Nodes added to group MachineSet/openshift-machine-api/build0-gstfj-ci-tests-worker-c failed to register within 15m1.330253578s
2022-10-11T18:36:34Z 1 ConfigMap cluster-autoscaler-status ScaleUpTimedOut: Nodes added to group MachineSet/openshift-machine-api/build0-gstfj-ci-longtests-worker-b failed to register within 15m15.146323452s
2022-10-11T18:42:13Z 1 ConfigMap cluster-autoscaler-status ScaleUpTimedOut: Nodes added to group MachineSet/openshift-machine-api/build0-gstfj-ci-prowjobs-worker-b failed to register within 15m8.388183709s
2022-10-11T18:43:14Z 4 ConfigMap cluster-autoscaler-status ScaledUpGroup: Scale-up: setting group MachineSet/openshift-machine-api/build0-gstfj-ci-builds-worker-b size to 3 instead of 2 (max: 120)
2022-10-11T19:07:07Z 1 ConfigMap cluster-autoscaler-status ScaledUpGroup: Scale-up: setting group MachineSet/openshift-machine-api/build0-gstfj-ci-longtests-worker-b size to 1 instead of 0 (max: 120)
2022-10-11T19:09:10Z 2 ConfigMap cluster-autoscaler-status ScaledUpGroup: Scale-up: setting group MachineSet/openshift-machine-api/build0-gstfj-ci-builds-worker-b size to 4 instead of 3 (max: 120)
But the only alert in this space was the info ClusterAutoscalerUnschedulablePods, which often fires as the cluster is successfully scaling into a large load batch.
This is similar to OCPCLOUD-1660, but that is about trouble creating the Machine instances. This particular round had successful instance creation, but do to MachineConfig vs. bootimage issues, the new machines were unable to create their CertificateSigningRequests or join as Nodes.
This is also similar to OCPCLOUD-1661, and that would have helped. But like ClusterAutoscalerUnschedulablePods, it would have been ambiguous about "slow to level" vs. "not making any progress". An alert that understands the 15m ScaleUpTimedOut cutoff would be an unambigous warning sign.
Steps
1. Create a MachineConfig pool that is not compatible with a MachineSet's boot image.
2. Request more replicas.
3. See the ScaleUpTimedOut events. And with this ticket, hopefully some kind of alert about the ScaleUpTimedOut too.
Stakeholders
All autoscaling users would benefit. Especially those on long-lived clusters, where old bootimages increase the change of boot-image vs. MachineConfig incompatibility (RFE-817, RFE-3001).
Definition of Done
- A new alert that fires in situations that result in ScaleUpTimedOut eventing.
- Docs
- I don't think we usually doc new alerts?
- Testing
- If it's easy to write CI to excercise the new alert, great. I don't think we need to block on automated CI, but there is some technical-debt risk to features that lack CI coverage.
{kind=link}
- is related to
-
OCPBUGS-4101 Empty/missing node-sizing SYSTEM_RESERVED_ES parameter can result in kubelet not starting
-
- Closed
-
-
-
- Closed
-
-
OCPCLOUD-1661 Investigate reporting on expected versus observed replicas for MachineSets
-
- Closed
-