-
Bug
-
Resolution: Can't Do
-
 Normal
Normal
-
None
-
4.8
-
Quality / Stability / Reliability
-
False
-
-
1
-
None
-
None
-
None
-
None
-
None
-
MCO Sprint 235, MCO Sprint 236
-
2
-
None
-
None
-
None
-
None
-
None
-
None
-
None
Description of problem:
Delay in triggering MCDDrainError alert
Current understanding is MCDDrainError alert should pop up if any pod (infrastructure pod or application) on the node is not getting removed due to PDB. From below code we understnd that alert is looking at logs of machine-config-daemon pod of that node.
~~~
- name: mcd-drain-error
rules:
- alert: MCDDrainError
annotations:
message: 'Drain failed on {{ $labels.node }} , updates may be blocked. For
more details: oc logs -f -n {{ $labels.namespace }} {{ $labels.pod }}
-c machine-config-daemon'
expr: |
mcd_drain_err > 0
labels:
severity: warning
~~~
Issue:
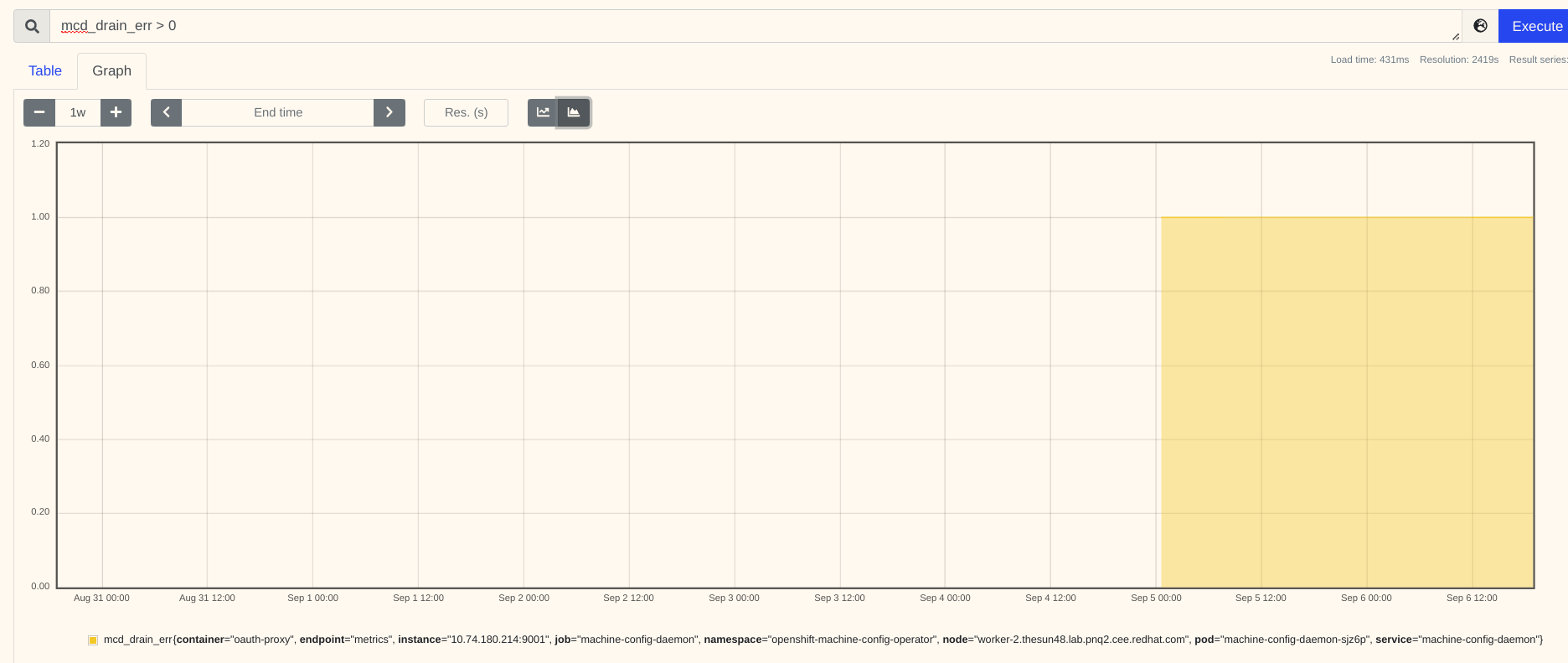
For Customer : Even after "Draining failed" in machine-config-daemon MCDDrainError alert did not appear.
For us (during reprod): I left my cluster in same state where MCP was stuck due to pdb for One week I saw various "Drain failed" logs .. but alert appeared on last day of the week
Version-Release number of selected component (if applicable):
4.8.43
How reproducible:
can be reproduced:
Steps to Reproduce:
1. Taint a worker node say worker-A 2. Create application add : Nodeselector (worker-A), tolration (worker-A), PDB 3. Create a test Machine Config to rollout woker MCP ~~~ name: 99-worker-test6 labels: machineconfiguration.openshift.io/role: worker spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:,test-6 filesystem: root mode: 0644 path: /etc/test6 ~~~ 4. check machine-config-daemon logs of the node
Actual results:
MCDDrainError do not appear!
Expected results:
MCDDrainError should appear as soon as Drain fails due to PDB
Additional info:
Alert intantly appered with an infrastructure pod was facing PDB issue.