-
Bug
-
Resolution: Not a Bug
-
 Normal
Normal
-
None
-
4.9
-
Quality / Stability / Reliability
-
None
-
None
-
3
-
Low
-
None
-
Unspecified
-
None
-
None
-
OCPNODE Sprint 234 (Green)
-
1
-
None
-
If docs needed, set a value
-
None
-
None
-
None
-
None
-
None
Description of problem:
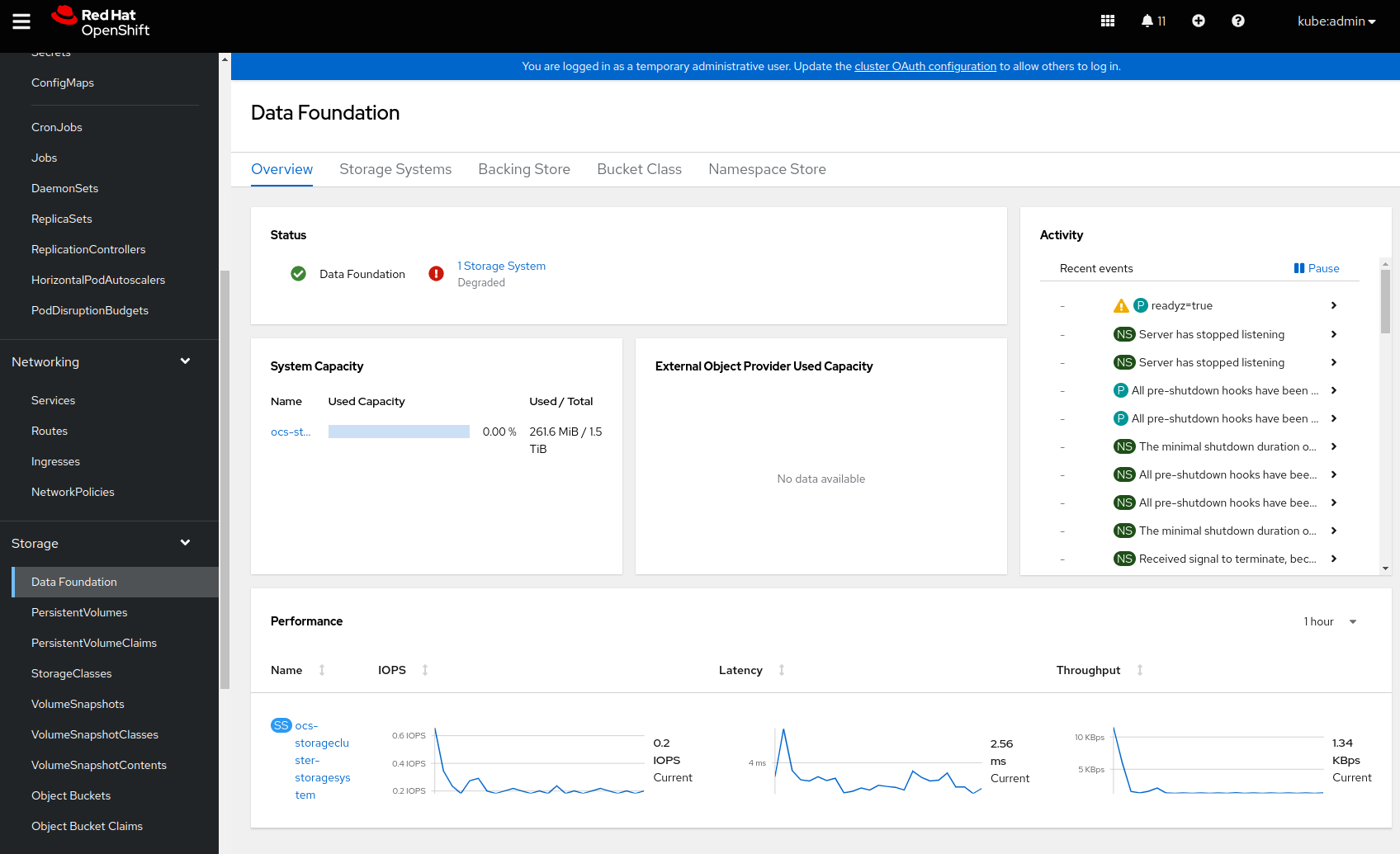
After OCS installation, there are multiple Events of Warning type from
horizontalpodautoscaler/noobaa-endpoint complaining that openshift is
"unable to get metrics for resource cpu". The stream of such events stops about
15 minutes after OCS installation.
NooBaa endpoint deployment is controlled by a horizontal pod autoscaler, which is the originator of these events
this is the cause for https://bugzilla.redhat.com/show_bug.cgi?id=1885524
Version-Release number of selected component (if applicable):
- OCP 4.9.0-0.nightly-2021-11-24-090558
- OCS 4.9.0-249.ci
How reproducible:
Steps to Reproduce:
1.
2.
3.
Steps to Reproduce
==================
1. Install OCP/OCS cluster
2. Login to OCP Console and open Overview Cluster dashboard
(Home -> Overview -> Cluster)
3. See "Recent events" list
Or you can also go to Events page or list events via command line client:
`oc get events -n openshift-storage`.
Actual results
==============
After OCS installation, I see warnings related to HPA noobaa-endpoint such as:
```
15m Warning FailedGetResourceMetric horizontalpodautoscaler/noobaa-endpoint unable to get metrics for resource cpu: no metrics returned from resource metrics API
15m Warning FailedComputeMetricsReplicas horizontalpodautoscaler/noobaa-endpoint invalid metrics (1 invalid out of 1), first error is: failed to get cpu utilization: unable to get metrics for resource cpu: no metrics re
turned from resource metrics API
12m Warning FailedGetResourceMetric horizontalpodautoscaler/noobaa-endpoint did not receive metrics for any ready pods
12m Warning FailedComputeMetricsReplicas horizontalpodautoscaler/noobaa-endpoint invalid metrics (1 invalid out of 1), first error is: failed to get cpu utilization: did not receive metrics for any ready pods
```
Expected results
================
Admin should not wait another 15 minutes after OCS Storage Cluster installation
for these events to stop.
There should be no such Warning events from
horizontalpodautoscaler/noobaa-endpoint right after OCS installation.
Additional info
===============
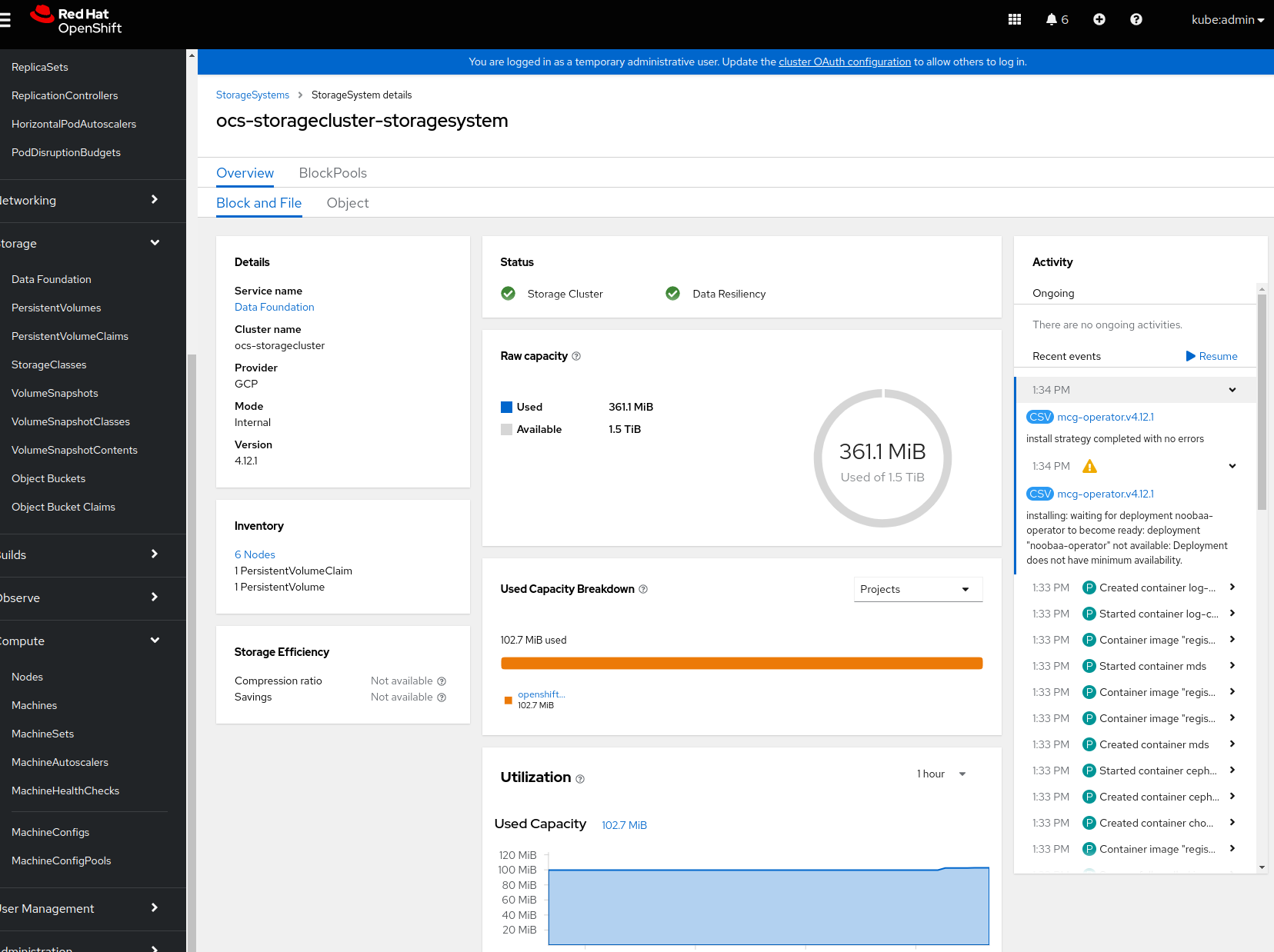
After about 15 minutes after OCS installation, the horizontalpodautoscaler
noobaa-endpoint seems to work fine (I don't claim it works as expected, rather
that it's not in an error state):
```
$ ./oc describe horizontalpodautoscaler/noobaa-endpoint -n openshift-storage
Name: noobaa-endpoint
Namespace: openshift-storage
Labels: app=noobaa
Annotations: <none>
CreationTimestamp: Mon, 05 Oct 2020 19:58:22 +0200
Reference: Deployment/noobaa-endpoint
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): 0% (2m) / 80%
Min replicas: 1
Max replicas: 2
Deployment pods: 1 current / 1 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ScaleDownStabilized recent recommendations were higher than current one, applying the highest recent recommendation
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request)
ScalingLimited False DesiredWithinRange the desired count is within the acceptable range
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedGetResourceMetric 19m (x2 over 20m) horizontal-pod-autoscaler unable to get metrics for resource cpu: no metrics returned from resource metrics API
Warning FailedComputeMetricsReplicas 19m (x2 over 20m) horizontal-pod-autoscaler invalid metrics (1 invalid out of 1), first error is: failed to get cpu utilization: unable to get metrics for resource cpu: no metrics returned from resource metrics API
Warning FailedComputeMetricsReplicas 17m (x10 over 19m) horizontal-pod-autoscaler invalid metrics (1 invalid out of 1), first error is: failed to get cpu utilization: did not receive metrics for any ready pods
Warning FailedGetResourceMetric 17m (x11 over 19m) horizontal-pod-autoscaler did not receive metrics for any ready pods
```
Private
Extra private groups
Comment 1

{kind=link}
{kind=link}