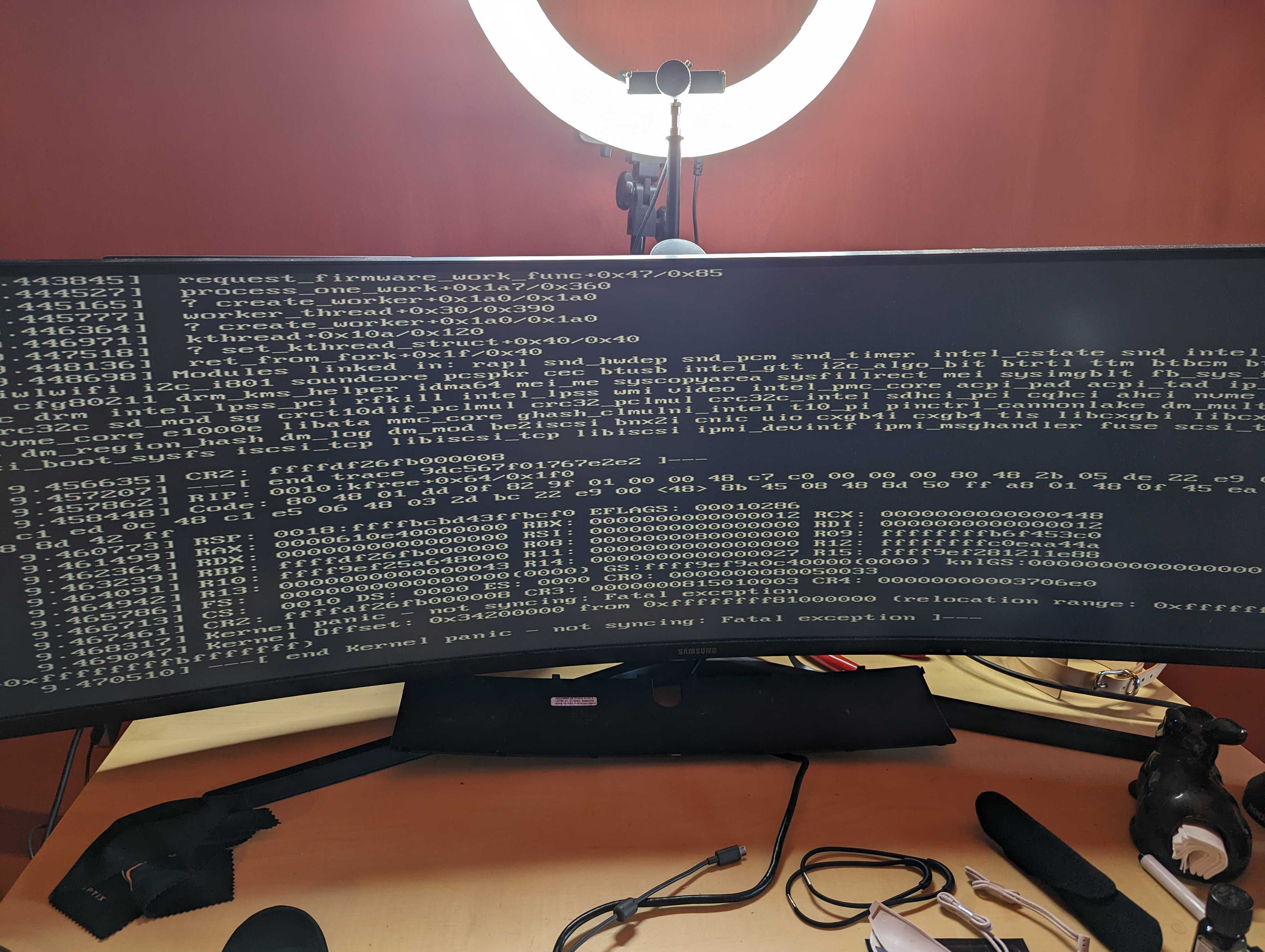
My SNO OpenShift installed on a NUC10i7FNH is stuck upgrading from 4.10 to 4.11 because a machine config pool is degraded. I've traced the source of the degraded pool to an image mismatch: desired is "quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:939d801d4e39b1a5215fabe51f64dfa7e986888f6815ccacd9565d8941470ab8" but my SNO is running "quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:23d0609643c25efcd30a7a64483fdee2343ced26b1fd08c0cbf8d03a5d405939". Steps taken: oc debug node/my-node chroot /host bash /run/bin/machine-config-daemon pivot quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:939d801d4e39b1a5215fabe51f64dfa7e986888f6815ccacd9565d8941470ab8 systemctl reboot The node experiences a kernel panic every time it tries to boot this new kernel so I need to select the older kernel to get my node to boot.
Version-Release number of selected component (if applicable):
How reproducible:
Steps to Reproduce:
1. Upgrade 4.10 to fast-4.11 on a NUC10i7FNH 2. Reboot node
Actual results:
Kernel will panic
Expected results:
Boot into OpenShift 4.11 without error
Additional info:
The attachment button in Jira is disabled for me so I've uploaded the sosreport to my own Vaultwarden instance available for 30 days from today, 01/09/2022 at https://bitwarden.hansen.agency/#/send/lyK0AHefQoq_TBC_YfMa5g/nCALB_2KQAG7h5cBR3J-xA