-
Bug
-
Resolution: Done
-
 Critical
Critical
-
None
-
4.13
-
None
-
Quality / Stability / Reliability
-
False
-
-
None
-
Critical
-
None
-
None
-
Approved
-
CLOUD Sprint 232, CLOUD Sprint 233, CLOUD Sprint 234
-
3
-
Done
-
Bug Fix
-
-
None
-
None
-
None
-
None
Description of problem:
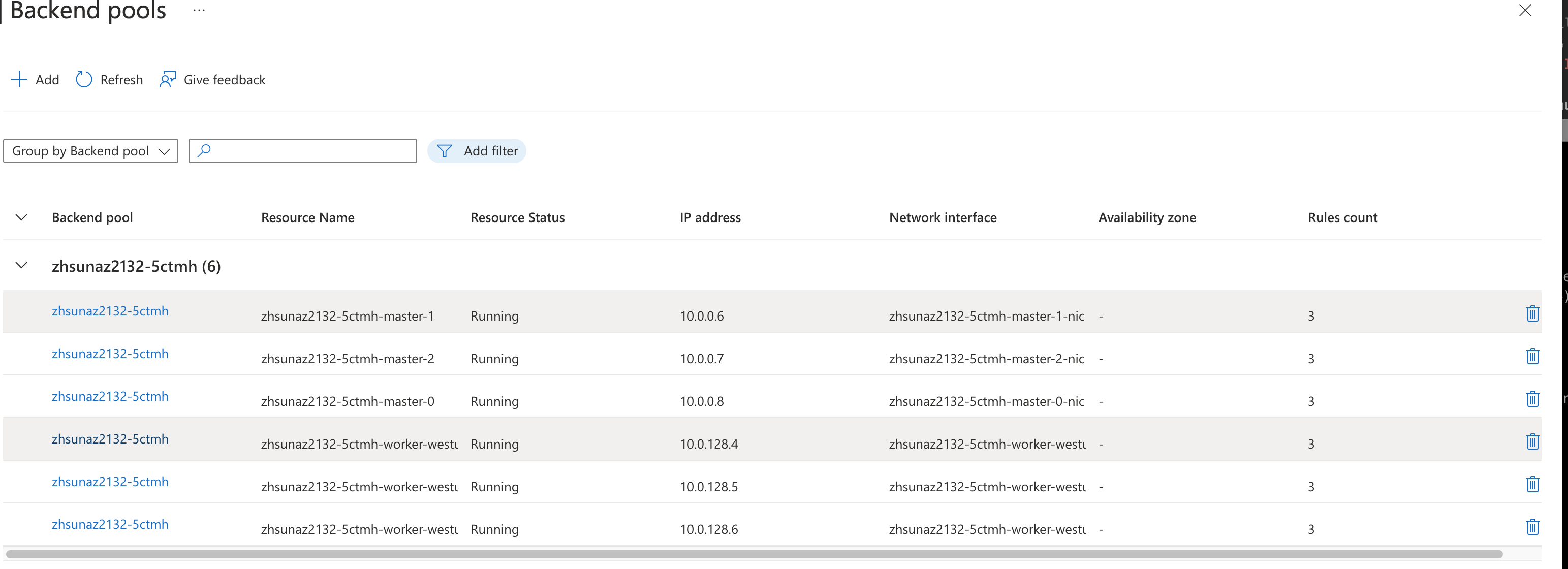
On azure, delete a master, old machine stuck in Deleting, some pods in cluster are in ImagePullBackOff, check from azure console, new master did not add into lb backend, seems this lead the machine has no internet connection.
Version-Release number of selected component (if applicable):
4.13.0-0.nightly-2023-02-12-024338
How reproducible:
Always
Steps to Reproduce:
1. Set up a cluster on Azure, networkType ovn 2. Delete a master 3. Check master and pod
Actual results:
Old machine stuck in Deleting, some pods are in ImagePullBackOff.
$ oc get machine
NAME PHASE TYPE REGION ZONE AGE
zhsunaz2132-5ctmh-master-0 Deleting Standard_D8s_v3 westus 160m
zhsunaz2132-5ctmh-master-1 Running Standard_D8s_v3 westus 160m
zhsunaz2132-5ctmh-master-2 Running Standard_D8s_v3 westus 160m
zhsunaz2132-5ctmh-master-flqqr-0 Running Standard_D8s_v3 westus 105m
zhsunaz2132-5ctmh-worker-westus-dhwfz Running Standard_D4s_v3 westus 152m
zhsunaz2132-5ctmh-worker-westus-dw895 Running Standard_D4s_v3 westus 152m
zhsunaz2132-5ctmh-worker-westus-xlsgm Running Standard_D4s_v3 westus 152m
$ oc describe machine zhsunaz2132-5ctmh-master-flqqr-0 -n openshift-machine-api |grep -i "Load Balancer"
Internal Load Balancer: zhsunaz2132-5ctmh-internal
Public Load Balancer: zhsunaz2132-5ctmh
$ oc get node
NAME STATUS ROLES AGE VERSION
zhsunaz2132-5ctmh-master-0 Ready control-plane,master 165m v1.26.0+149fe52
zhsunaz2132-5ctmh-master-1 Ready control-plane,master 165m v1.26.0+149fe52
zhsunaz2132-5ctmh-master-2 Ready control-plane,master 165m v1.26.0+149fe52
zhsunaz2132-5ctmh-master-flqqr-0 NotReady control-plane,master 109m v1.26.0+149fe52
zhsunaz2132-5ctmh-worker-westus-dhwfz Ready worker 152m v1.26.0+149fe52
zhsunaz2132-5ctmh-worker-westus-dw895 Ready worker 152m v1.26.0+149fe52
zhsunaz2132-5ctmh-worker-westus-xlsgm Ready worker 152m v1.26.0+149fe52
$ oc describe node zhsunaz2132-5ctmh-master-flqqr-0
Warning ErrorReconcilingNode 3m5s (x181 over 108m) controlplane [k8s.ovn.org/node-chassis-id annotation not found for node zhsunaz2132-5ctmh-master-flqqr-0, macAddress annotation not found for node "zhsunaz2132-5ctmh-master-flqqr-0" , k8s.ovn.org/l3-gateway-config annotation not found for node "zhsunaz2132-5ctmh-master-flqqr-0"]
$ oc get po --all-namespaces | grep ImagePullBackOf
openshift-cluster-csi-drivers azure-disk-csi-driver-node-l8ng4 0/3 Init:ImagePullBackOff 0 113m
openshift-cluster-csi-drivers azure-file-csi-driver-node-99k82 0/3 Init:ImagePullBackOff 0 113m
openshift-cluster-node-tuning-operator tuned-bvvh7 0/1 ImagePullBackOff 0 113m
openshift-dns node-resolver-2p4zq 0/1 ImagePullBackOff 0 113m
openshift-image-registry node-ca-vxv87 0/1 ImagePullBackOff 0 113m
openshift-machine-config-operator machine-config-daemon-crt5w 1/2 ImagePullBackOff 0 113m
openshift-monitoring node-exporter-mmjsm 0/2 Init:ImagePullBackOff 0 113m
openshift-multus multus-4cg87 0/1 ImagePullBackOff 0 113m
openshift-multus multus-additional-cni-plugins-mc6vx 0/1 Init:ImagePullBackOff 0 113m
openshift-ovn-kubernetes ovnkube-master-qjjsv 0/6 ImagePullBackOff 0 113m
openshift-ovn-kubernetes ovnkube-node-k8w6j 0/6 ImagePullBackOff 0 113m
Expected results:
Replace master successful
Additional info:
Tested payload 4.13.0-0.nightly-2023-02-03-145213, same result. Before we have tested in 4.13.0-0.nightly-2023-01-27-165107, all works well.
- depends on
-
-

- Closed
-
- is cloned by
-
-
- Closed
-
- is related to
-
-

- Closed
-
-
-
- Closed
-
- links to