-
Bug
-
Resolution: Done-Errata
-
 Critical
Critical
-
None
-
4.13.0
-
Quality / Stability / Reliability
-
False
-
-
None
-
Moderate
-
None
-
None
-
Rejected
-
SDN Sprint 231, SDN Sprint 232, SDN Sprint 233, SDN Sprint 234, SDN Sprint 235
-
5
-
None
-
None
-
None
-
None
-
None
-
None
-
None
This is a long standing issue where gcp ovn for some reason sees dramatically more disruption to ingress during upgrades than other clouds. It can best be seen in the "ingress" graphs in charts such as: https://lookerstudio.google.com/s/v6xhLCTHHDY
Notice image-registry-new (which is ingress backed), ingress-to-console new, and ingress-to-oauth new, all of which take an average of 40s as of the time of this writing. For comparison, Azure is normally <10, and AWS <4.
You will also note the load-balancer new backend shows similar high disruption, but after conversations with network edge we now know the code paths for these two are very different, thus we're filing this as a separate bug. The SLB bug is https://issues.redhat.com/browse/OCPBUGS-6796. The two may prove to be same cause in future, as they do appear similar, but not identical even in terms of when the problems occur.
Some example prob jows are easy to find as the disruption is on average there. Note that we do not typically fail a test on these as the disruption monitoring stack is built to try to pin where we're at now, and this is a long standing issue.
This job was near successful but got 45s of disruption to image-registry-new. The disruption observed can always be seen in artifacts such as: https://gcsweb-ci.apps.ci.l2s4.p1.openshiftapps.com/gcs/origin-ci-test/logs/periodic-ci-openshift-release-master-ci-4.13-upgrade-from-stable-4.12-e2e-gcp-ovn-upgrade/1620744632478470144/artifacts/e2e-gcp-ovn-upgrade/openshift-e2e-test/artifacts/junit/backend-disruption_20230201-120923.json
Expanding the first "Intervals - spyglass" chart on the main prowjob page, you can see when the disruption occurred and what else was going on in the cluster at that time.
This shows we're not getting a continuous 40+s of disruption, rather a few batches.
The ingress services all go down roughly together, the service load balancer pattern looks a little different, thus the different bug mentioned above.
For more examples just visit https://sippy.dptools.openshift.org/sippy-ng/jobs/4.13/runs?filters=%7B%22items%22%3A%5B%7B%22columnField%22%3A%22name%22%2C%22operatorValue%22%3A%22equals%22%2C%22value%22%3A%22periodic-ci-openshift-release-master-ci-4.13-upgrade-from-stable-4.12-e2e-gcp-ovn-upgrade%22%7D%5D%7D&sortField=timestamp&sort=desc, it will happen nearly every time.
When examining what else was going on when this happens, we see some clear patterns of nodes being updated.
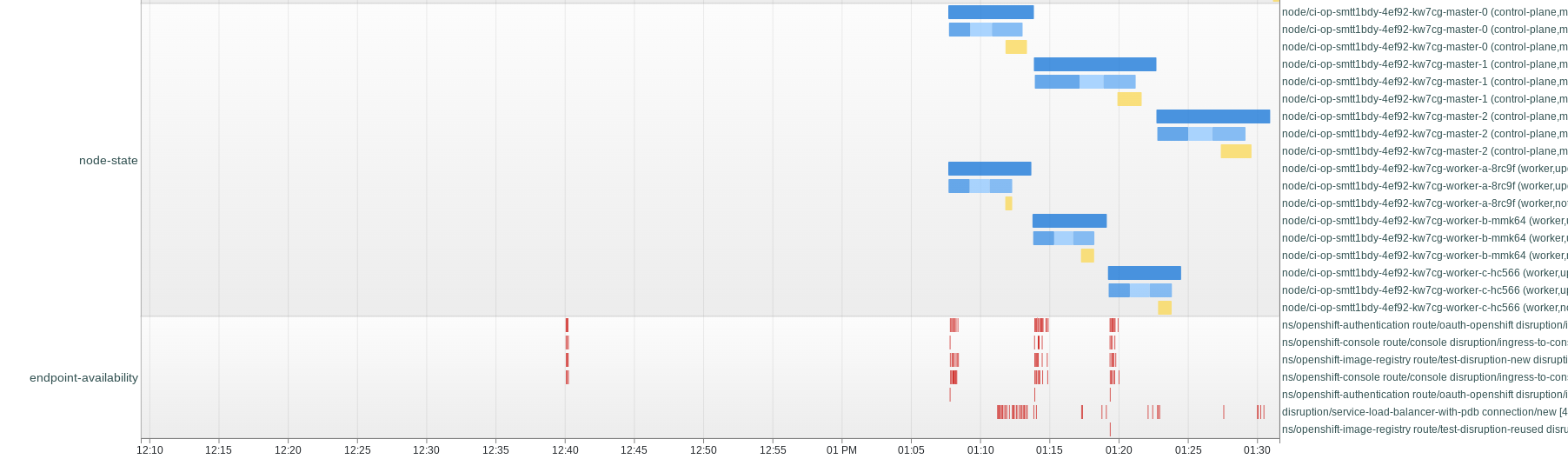
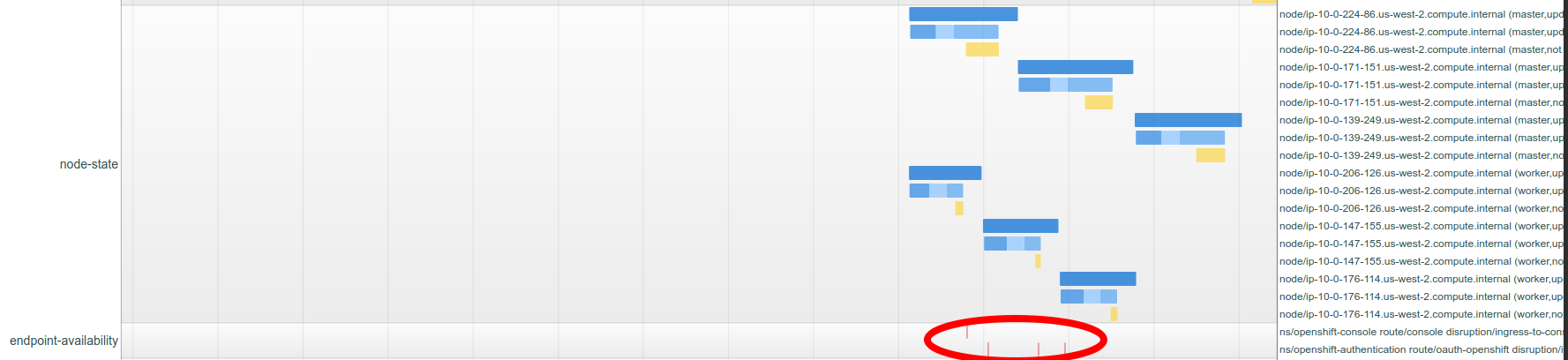
- blocks
-
-
- Closed
-
- is cloned by
-
-
- Closed
-
-
-
- Closed
-
- relates to
-
-

- Closed
-
- links to
-
 RHEA-2023:5006
rpm
RHEA-2023:5006
rpm

