-
Bug
-
Resolution: Done
-
 Major
Major
-
None
-
4.11
-
Quality / Stability / Reliability
-
False
-
-
None
-
None
-
None
-
None
-
Rejected
-
Windu 231, X-Files 232
-
2
-
None
-
None
-
None
-
None
-
None
-
None
-
None
Description of problem:
Redhat-operator part of the marketplace is failing regularly due to startup probe timing out connecting to registry-server container part of the same pod within 1 sec which in turn increases CPU/Mem usage on Master nodes: 62m Normal Scheduled pod/redhat-operators-zb4j7 Successfully assigned openshift-marketplace/redhat-operators-zb4j7 to ip-10-0-163-212.us-west-2.compute.internal by ip-10-0-149-93 62m Normal AddedInterface pod/redhat-operators-zb4j7 Add eth0 [10.129.1.112/23] from ovn-kubernetes 62m Normal Pulling pod/redhat-operators-zb4j7 Pulling image "registry.redhat.io/redhat/redhat-operator-index:v4.11" 62m Normal Pulled pod/redhat-operators-zb4j7 Successfully pulled image "registry.redhat.io/redhat/redhat-operator-index:v4.11" in 498.834447ms 62m Normal Created pod/redhat-operators-zb4j7 Created container registry-server 62m Normal Started pod/redhat-operators-zb4j7 Started container registry-server 62m Warning Unhealthy pod/redhat-operators-zb4j7 Startup probe failed: timeout: failed to connect service ":50051" within 1s 62m Normal Killing pod/redhat-operators-zb4j7 Stopping container registry-server Increasing the threshold of the probe might fix the problem: livenessProbe: exec: command: - grpc_health_probe - -addr=:50051 failureThreshold: 3 initialDelaySeconds: 10 periodSeconds: 10 successThreshold: 1 timeoutSeconds: 5 name: registry-server ports: - containerPort: 50051 name: grpc protocol: TCP readinessProbe: exec: command: - grpc_health_probe - -addr=:50051 failureThreshold: 3 initialDelaySeconds: 5 periodSeconds: 10 successThreshold: 1 timeoutSeconds: 5
Version-Release number of selected component (if applicable):
How reproducible:
Always
Steps to Reproduce:
1. Install OSD cluster using 4.11.0-0.nightly-2022-08-26-162248 payload 2. Inspect redhat-operator pod in openshift-marketplace namespace 3. Observe the resource usage ( CPU and Memory ) of the pod
Actual results:
Redhat-operator failing leading to increase to CPU and Mem usage on master nodes regularly during the startup
Expected results:
Redhat-operator startup probe succeeding and no spikes in resource on master nodes
Additional info:
Attached cpu, memory and event traces.
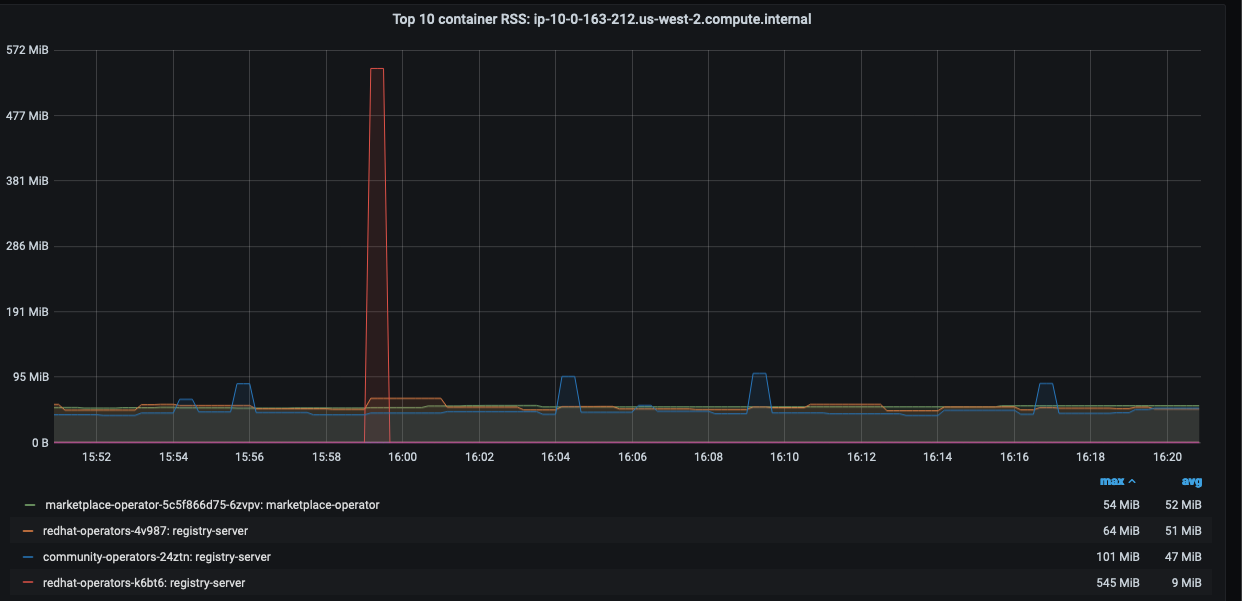
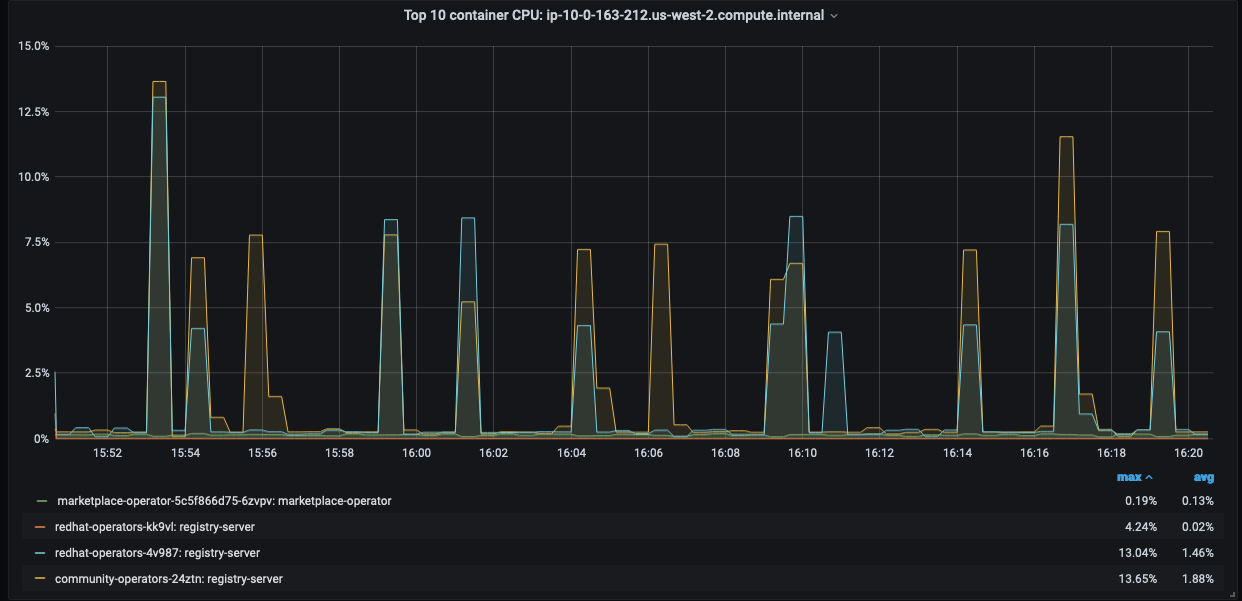
- blocks
-
-
- Closed
-
- duplicates
-
-

- Closed
-
- is caused by
-
-
- New
-
- is cloned by
-
-
- Closed
-
- links to

