-
Bug
-
Resolution: Unresolved
-
 Normal
Normal
-
4.21
-
None
-
False
-
-
1
-
None
-
None
-
None
-
None
-
MCO Sprint 281
-
1
-
None
-
None
-
None
-
None
-
None
-
None
-
None
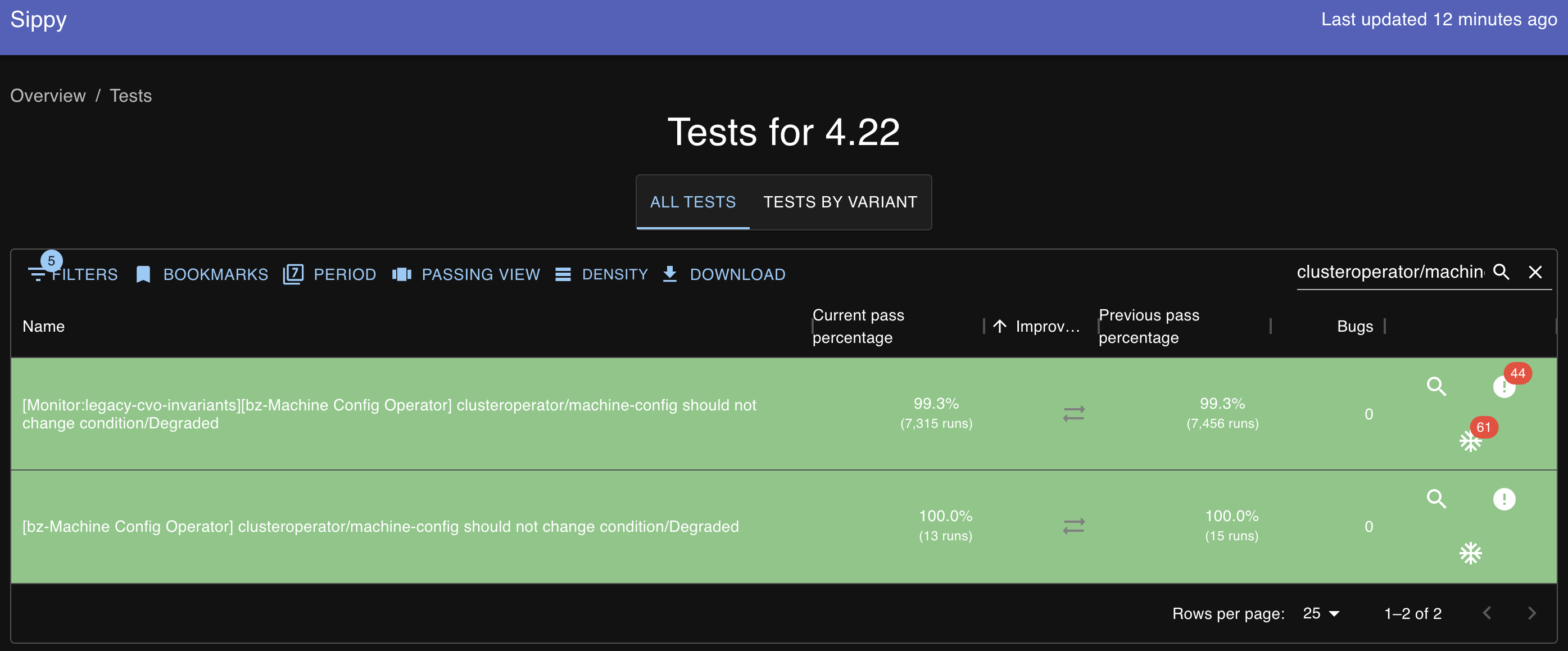
"A component must not report Degraded during the course of a normal upgrade" as defined in the API docs.
The cluster operator machine-config reported Degraded=True in CI jobs for 4.21.
Non-upgrade jobs: job 1 and job 2.
: [Monitor:legacy-cvo-invariants][bz-Machine Config Operator] clusteroperator/machine-config should not change condition/Degraded expand_less
Run #0: Failed expand_less 1h53m25s
{ 0 unexpected clusteroperator state transitions during e2e test run, as desired.
3 unwelcome but acceptable clusteroperator state transitions during e2e test run. These should not happen, but because they are tied to exceptions, the fact that they did happen is not sufficient to cause this test-case to fail:
Nov 24 22:11:18.359 E clusteroperator/machine-config condition/Degraded reason/MachineConfigurationFailed status/True Failed to resync 4.21.0-0.nightly-2025-11-24-202346 because: Operation cannot be fulfilled on machineconfigurations.operator.openshift.io "cluster": the object has been modified; please apply your changes to the latest version and try again (exception: https://issues.redhat.com/browse/MCO-1447)
Nov 24 22:11:18.359 - 5s E clusteroperator/machine-config condition/Degraded reason/MachineConfigurationFailed status/True Failed to resync 4.21.0-0.nightly-2025-11-24-202346 because: Operation cannot be fulfilled on machineconfigurations.operator.openshift.io "cluster": the object has been modified; please apply your changes to the latest version and try again (exception: https://issues.redhat.com/browse/MCO-1447)
Nov 24 22:11:23.994 W clusteroperator/machine-config condition/Degraded status/False (exception: Degraded=False is the happy case)
}
: [Monitor:legacy-cvo-invariants][bz-Machine Config Operator] clusteroperator/machine-config should not change condition/Degraded expand_lessRun #0: Failed expand_less2h1m21s{ 0 unexpected clusteroperator state transitions during e2e test run, as desired.
3 unwelcome but acceptable clusteroperator state transitions during e2e test run. These should not happen, but because they are tied to exceptions, the fact that they did happen is not sufficient to cause this test-case to fail:
Sep 16 10:11:28.224 E clusteroperator/machine-config condition/Degraded reason/MachineConfigNodeFailed status/True Failed to resync 4.20.0-0.ci-2025-09-16-023339 because: etcdserver: leader changed (exception: https://issues.redhat.com/browse/MCO-1447)
Sep 16 10:11:28.224 - 9s E clusteroperator/machine-config condition/Degraded reason/MachineConfigNodeFailed status/True Failed to resync 4.20.0-0.ci-2025-09-16-023339 because: etcdserver: leader changed (exception: https://issues.redhat.com/browse/MCO-1447)
Sep 16 10:11:37.571 W clusteroperator/machine-config condition/Degraded status/False (exception: Degraded=False is the happy case)
}
- blocks
-
-
- Closed
-
- is cloned by
-
-
- Closed
-
- is related to
-
MCO-1447 Add a filter to permit MachineConfigurationFailed in origin boot image tests
-
- Closed
-
- relates to
-
TRT-1578 Ensure all HA components are not degraded by design during upgrades
-
- New
-
- links to
