-
Bug
-
Resolution: Duplicate
-
 Major
Major
-
None
-
4.19
-
None
-
False
-
-
None
-
Critical
-
None
-
x86_64
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
Description of problem
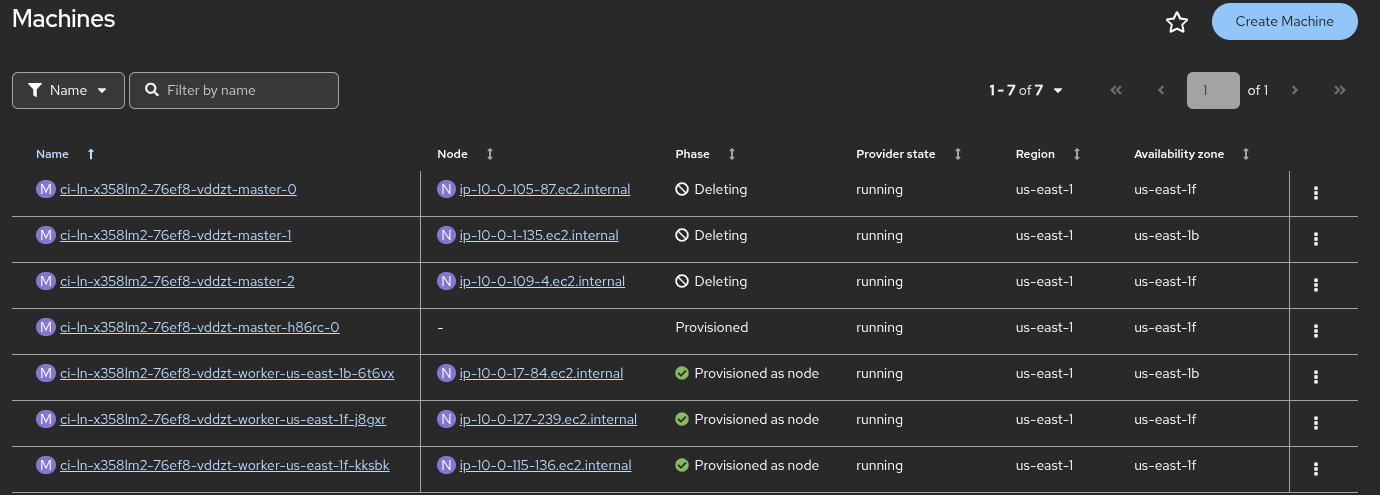
A compliance controller ordered the deletion of all three of an OCP cluster's control plane machines within a ~1hr span (expected behavior because the machines were too old per compliance rules). Etcd quorum was lost during this time span because "old" machines were drained/deleted before replacement machines could fully join the etcd cluster.
Version-Release number of selected component (if applicable):
OCP v4.19.17
How reproducible
Unclear
Steps to Reproduce
- Do oc delete machine -n openshift-machine-api master-0
- Wait 15 minutes
- Do oc delete machine -n openshift-machine-api master-1
- Wait 15 minutes
- Do oc delete machine -n openshift-machine-api master-2
Actual results
Control plane machines are drained/shut-down too soon, leaving the cluster with only 1-2 healthy etcd members until the replacement node has fully joined the etcd cluster. etcdNoLeader and etcdInsufficientMembers alerts fire intermittently.
Expected results
Deleted control plane machines aren't drained until a replacement machine has fully provisioned, joined the cluster as a node, and joined the etcd cluster as a member. Ideally, this means that there would briefly be 4 etcd members (assuming the usual 3-node control plane), but even in the worst case, CPMS should ensure there are never fewer than 2 healthy etcd members.
Additional info
This graph screenshot shows the observed behavior. The three "rapid" machine deletions took place between ~8pm and ~9pm. The unacceptable period (when there was only one healthy etcd member) occurs around 8:12pm. The brief spike to 4 members around 10pm was a result of a test deletion we performed after the bug was observed, and it demonstrates the expected behavior.
- is duplicated by
-
-
- Verified
-
- is related to
-
-
- Verified
-
- relates to
-
-

- New
-