-
Bug
-
Resolution: Duplicate
-
 Critical
Critical
-
None
-
4.6
-
Incidents & Support
-
False
-
-
None
-
Critical
-
None
-
None
-
None
-
Rejected
-
SDN Sprint 230, SDN Sprint 231
-
2
-
Customer Escalated
-
-
None
-
None
-
None
-
None
-
None
-
None
-
None
Description of problem:
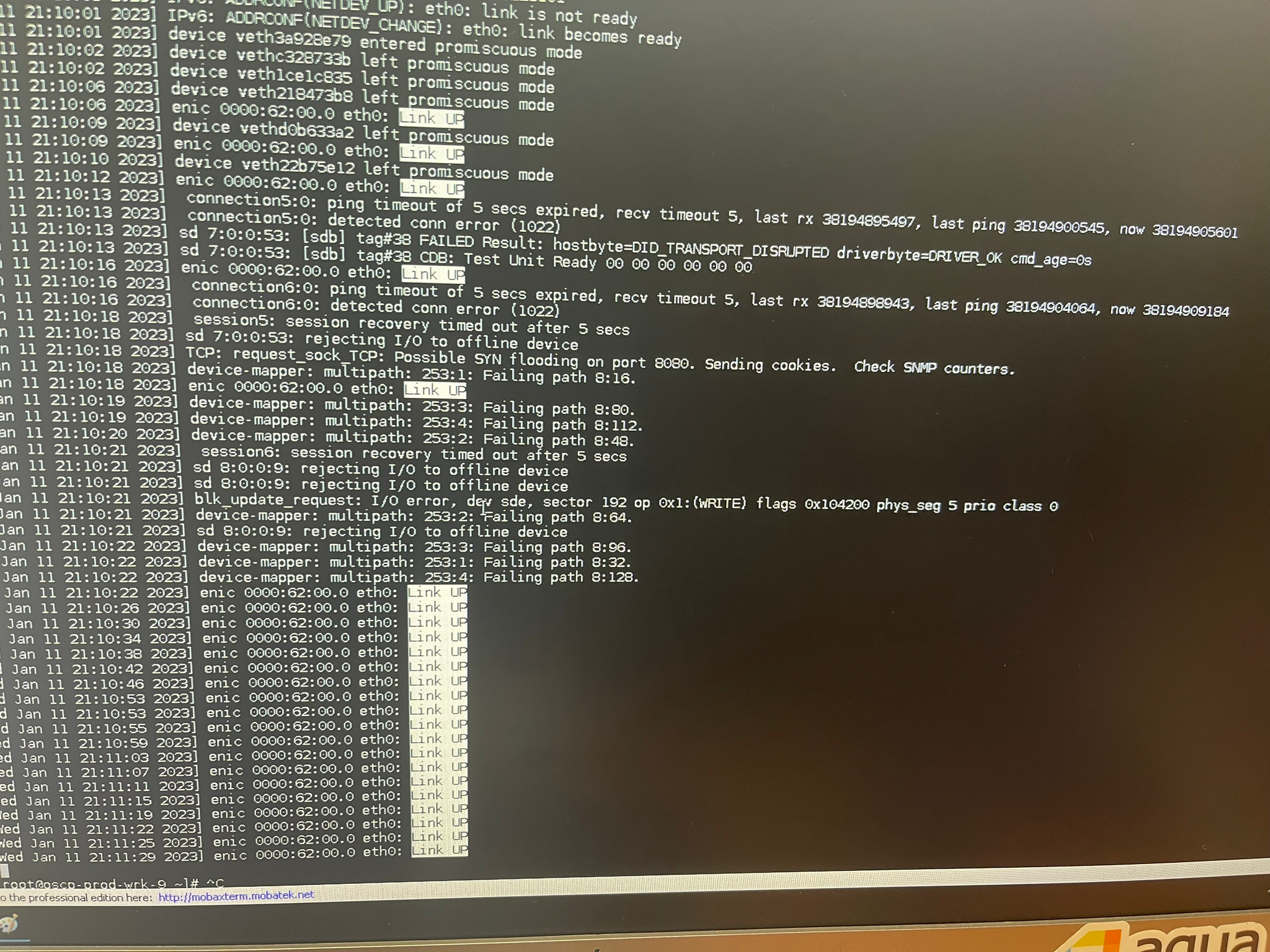
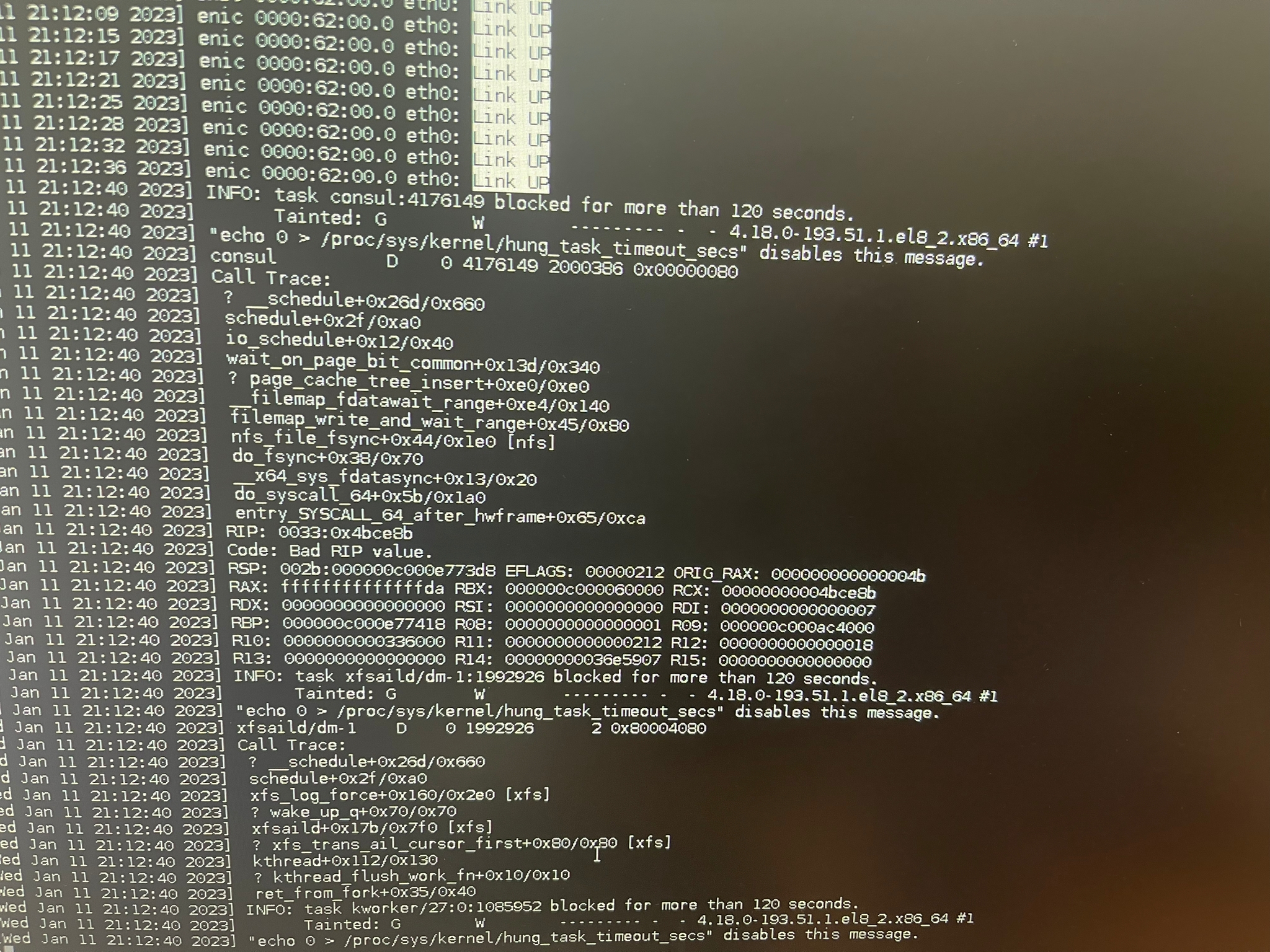
In the last two months, the customer PaaS team experienced nodes’ network interface (NIC) “freeze” on multiple nodes in the production environment (OCP 4.6). It happens only on the worker nodes.
Version-Release number of selected component (if applicable):
OCP 4.6
Actual results:
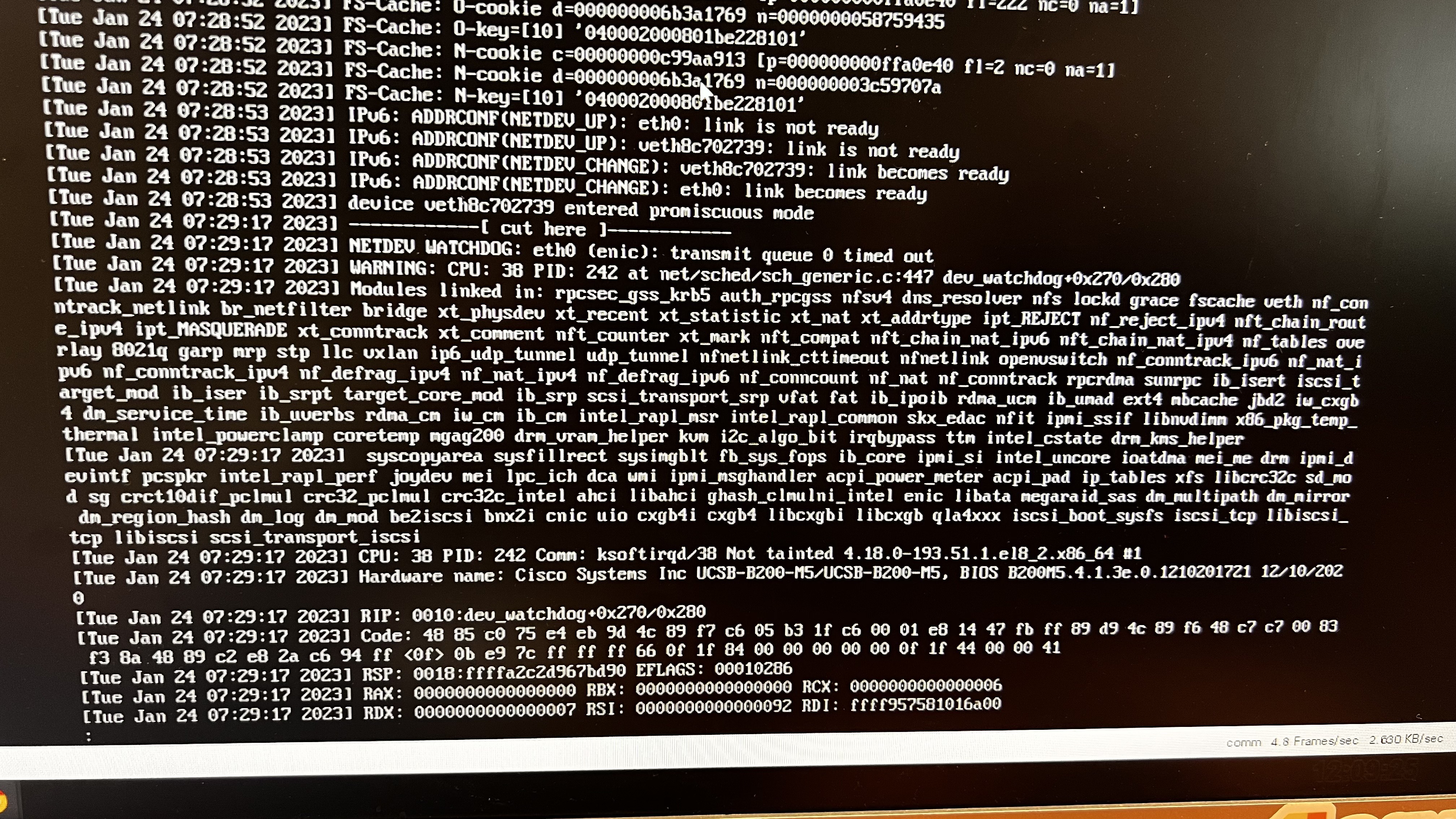
NIC freezes and customer is getting errors like
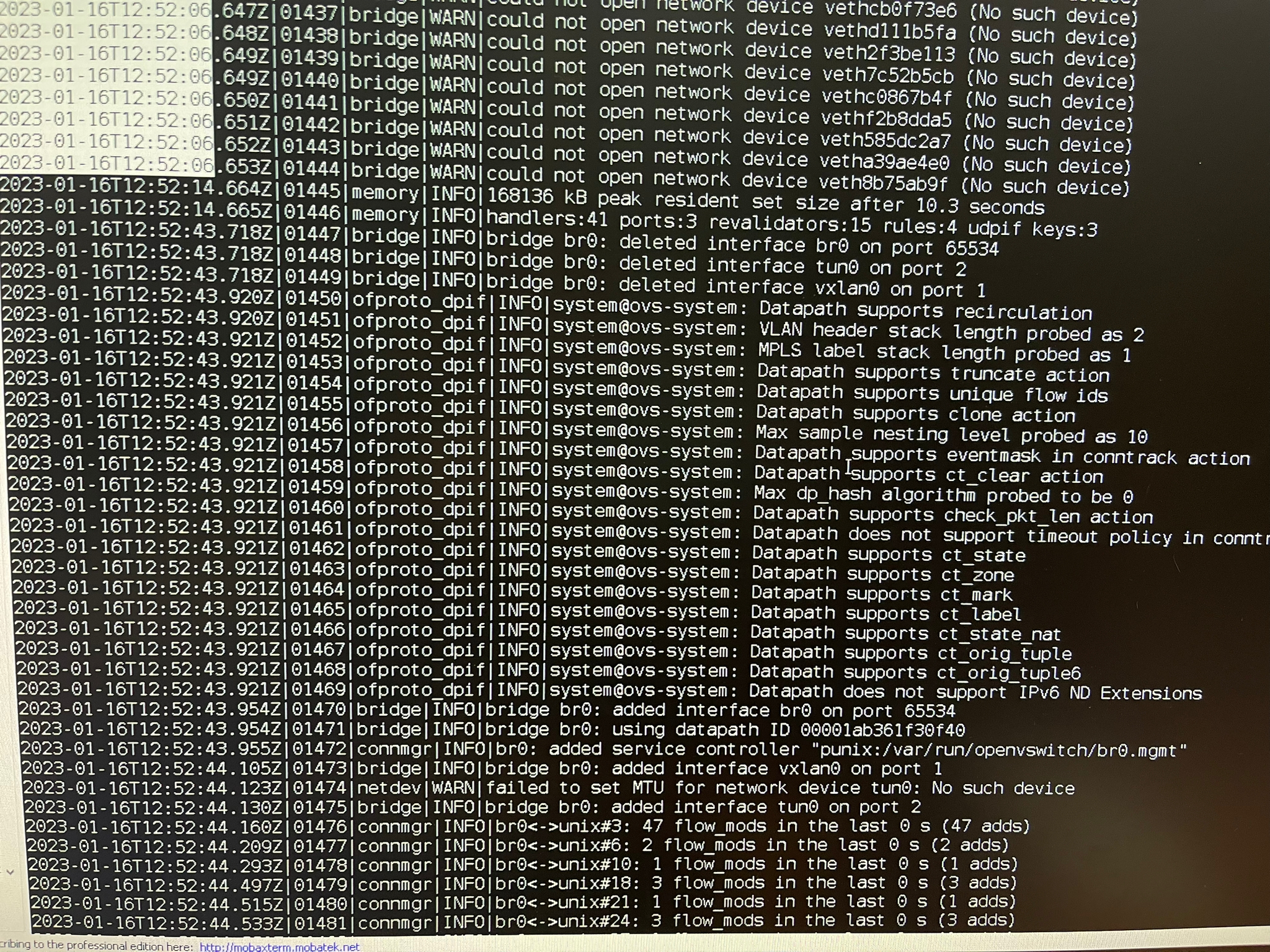
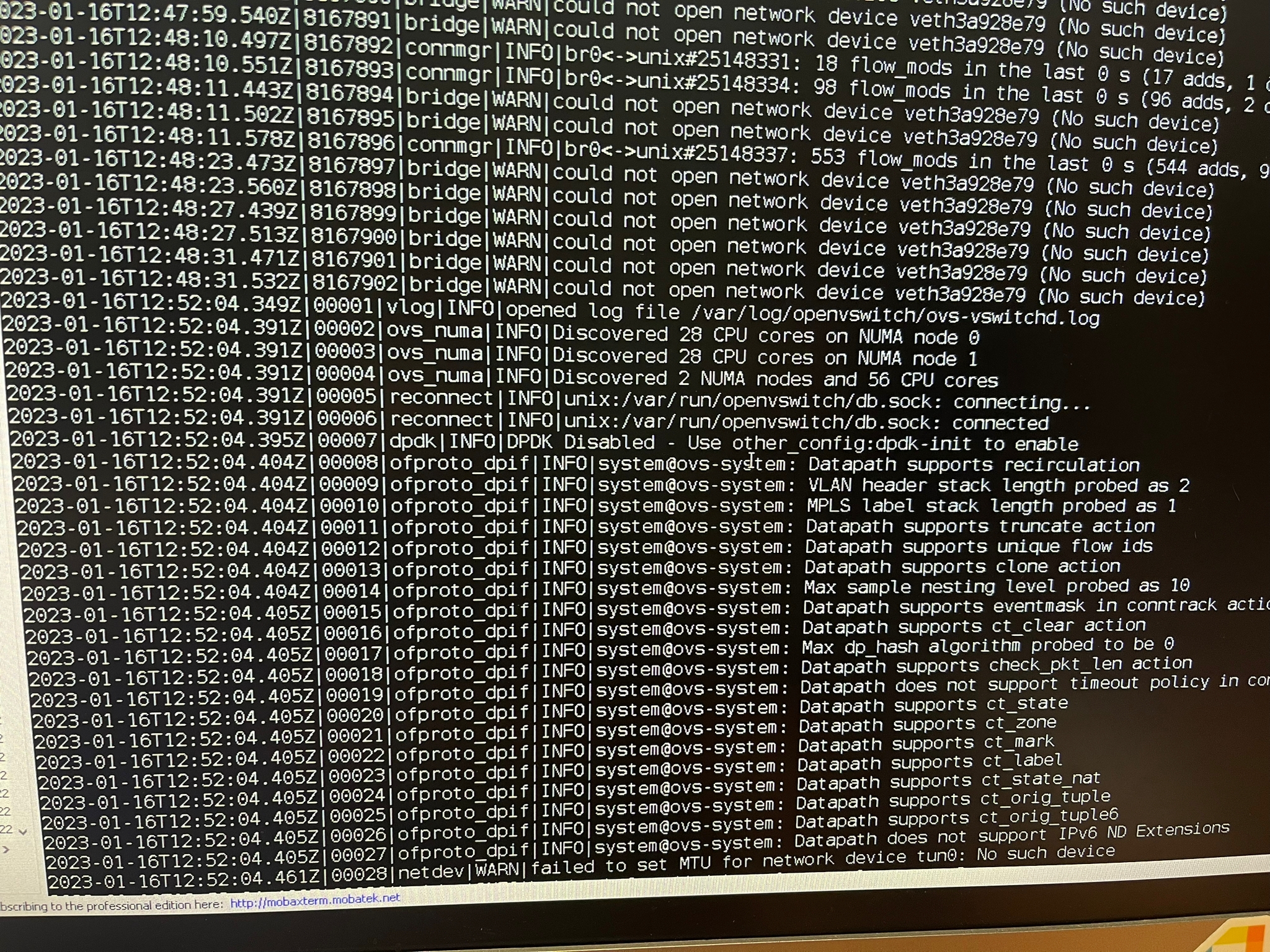
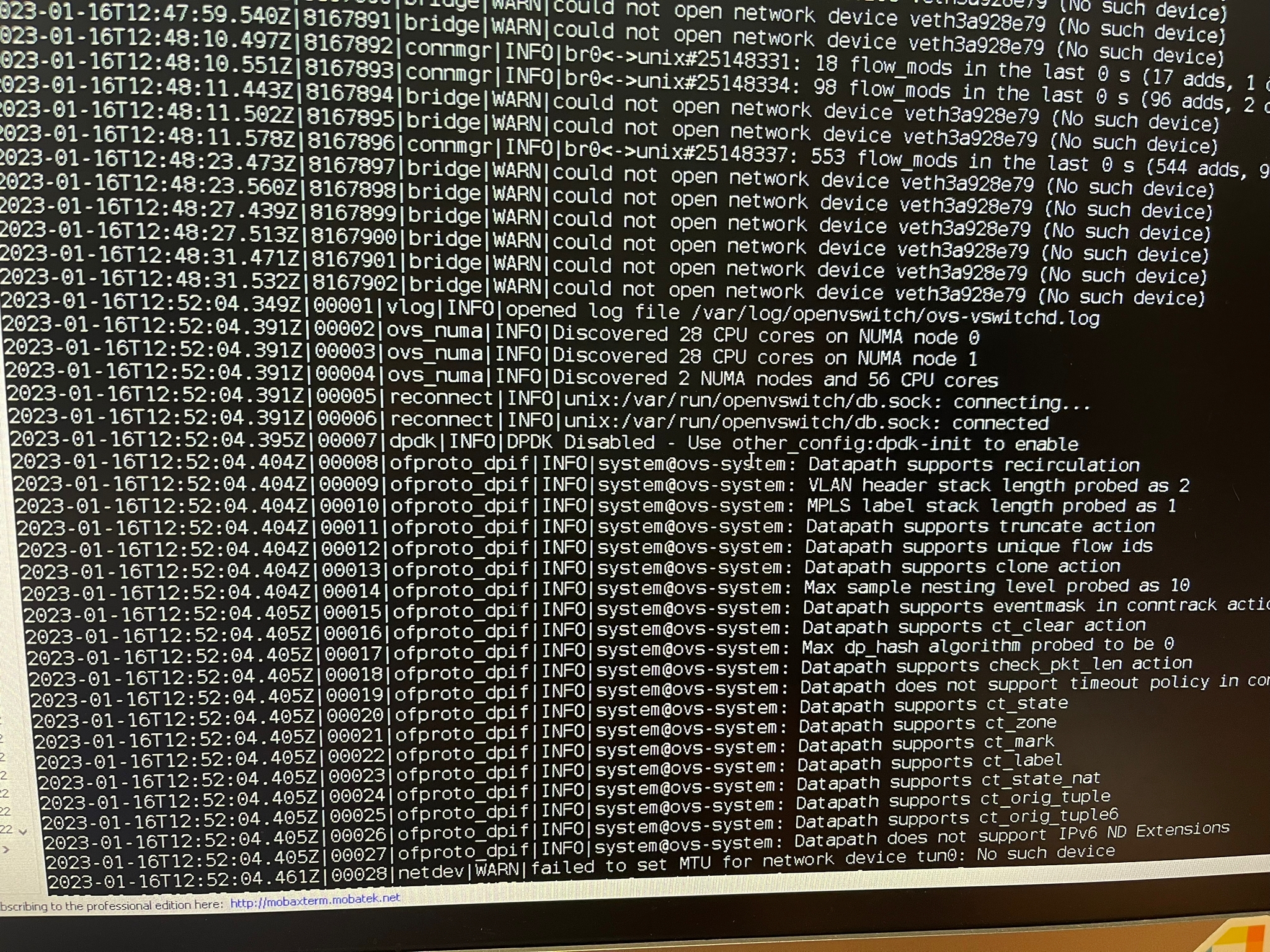
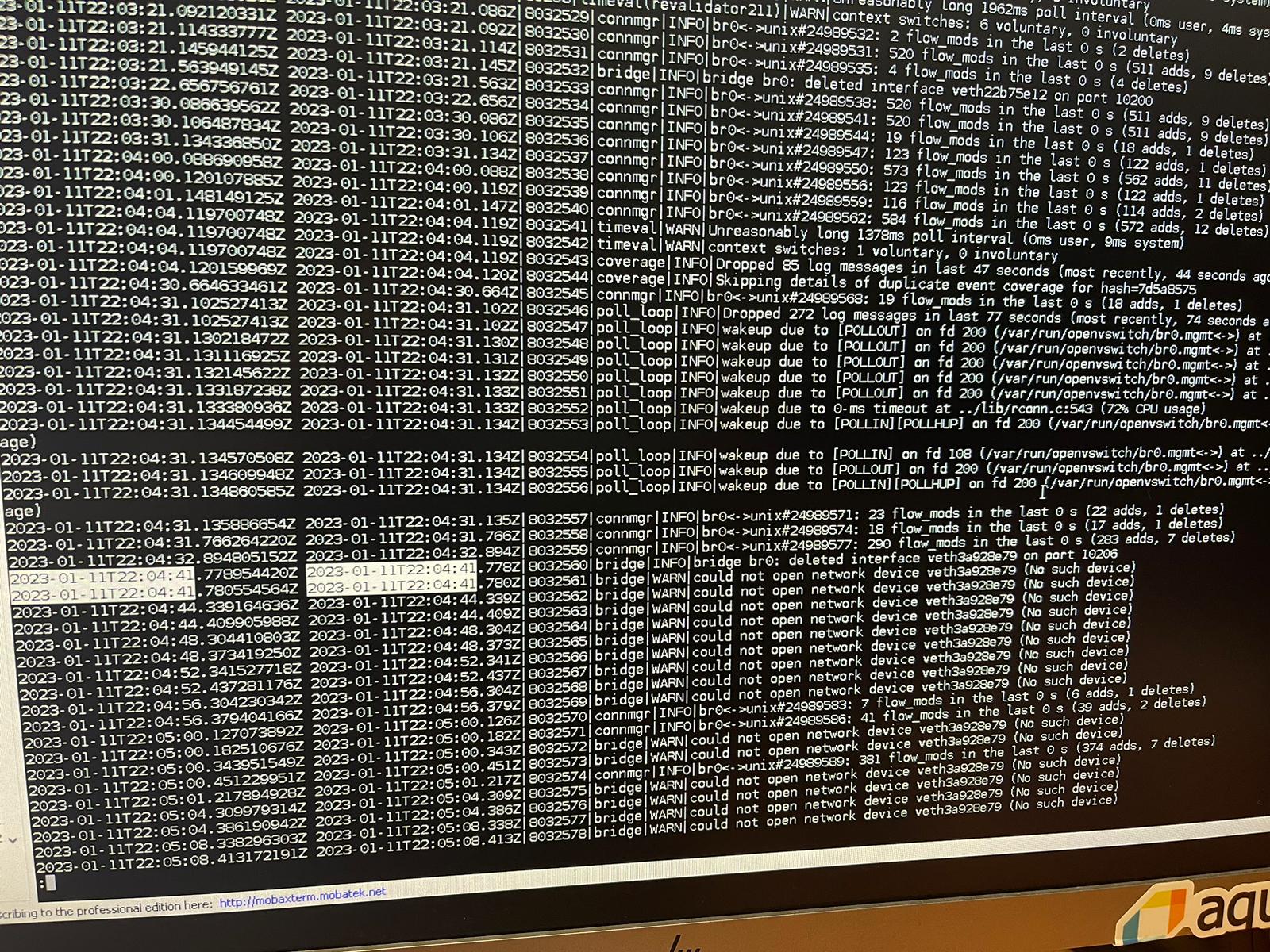
" Bridge|WARN| could not open network device veth<ID> (no such device)"
this line shows up 11331 time in log and it starts right around the time of the network freeze - the first time this line shows up is 22:04:41 - the log shows that it deleted this veth device seconds before that
the sdn container stops work working (removing CNI_DEL and adding ip for pods) around the freeze time
crictl logs -t --tail 100 ID_OF_SDN_CONTAINER $> sdn-log.txt
after the freeze the SDN container only shows the log "SyncVNIDRules: 1 unsued VNID"
in the journalctl we saw the log line
"about to del CNI network multus-cni-network (type=multuis)"
Expected results:
NIC freezing MUST not happen.
Additional info:
OCP: 4.6
CASE: 03402417
Customer enviroment is Air Gaped and restricted cluster. So logs like sosreports and MG can not be provided.
Some logs have attached with the case. Kindly refer it.
Customer is facing similar kind of issue like https://bugzilla.redhat.com/show_bug.cgi?id=1893088
Issue Type: Highly escalated
Cluster specifications
Prod - OCP version 4.6.27
Dev - OCP version 4.8.37
Worker nodes are installed on bare metal servers - Cisco UCSB-B200-M5
Master nodes are running on VMware VMs (Hybrid installation)
NOTE: After the restart of node it works perfectly fine.
This issue is intermittent in nature.
- links to