-
Bug
-
Resolution: Not a Bug
-
 Normal
Normal
-
None
-
4.11
-
Quality / Stability / Reliability
-
False
-
-
None
-
Moderate
-
None
-
None
-
None
-
None
-
OCPNODE Sprint 227 (Blue), OCPNODE Sprint 228 (Blue)
-
2
-
None
-
None
-
None
-
None
-
None
-
None
-
None
Description of problem:
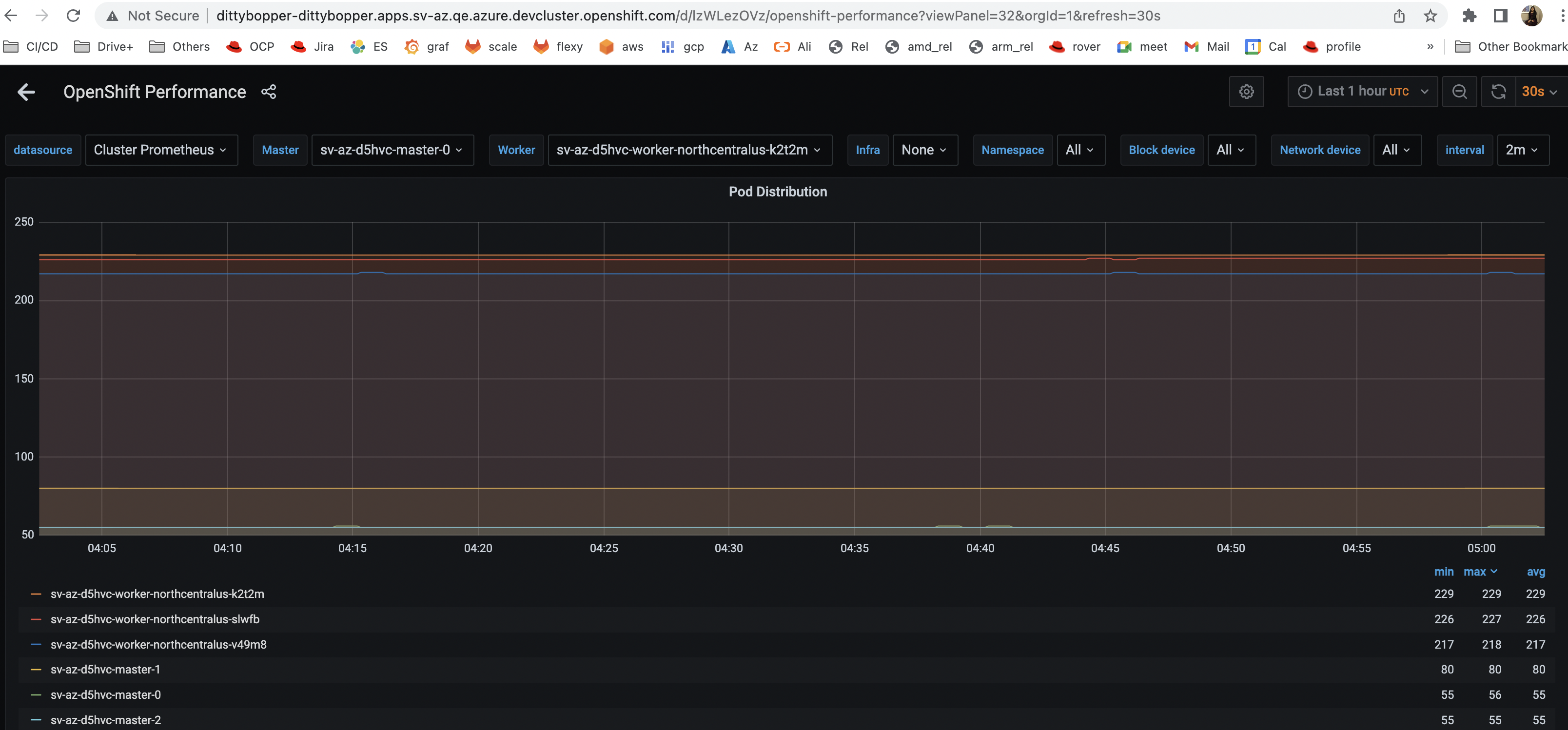
When running kube burner Perf Scale-ci "cluster-density" test on AWS ARM Baremetal 20 node cluster using instance type m6g.metal with following configuration, "SystemMemoryExceedsReservation" alerts are being fired with any load > 160 JOB_ITERATIONS.
I ran the test with 220 JOB ITERATIONS and higher and noticed this behavior. Other than these alerts, pods per worker node are around 140 to 180 (well below 250), cluster is accessible and no operators are degraded.
| Instance Size | vCPU | Memory (GiB) | Instance Storage (GB) | Network Bandwidth (Gbps)*** | EBS Bandwidth (Mbps) |
| m6g.metal | 64 | 256 | EBS-Only | 25 | 19,000 |
Version-Release number of selected component (if applicable):
[root@6bf1c9bc5331 temp_Downloads]# oc version Client Version: 4.10.0 Server Version: 4.11.0 Kubernetes Version: v1.24.0+9546431 [root@6bf1c9bc5331 temp_Downloads]#
How reproducible: Execute https://github.com/cloud-bulldozer/e2e-benchmarking/tree/master/workloads/kube-burner/workloads/cluster-density
Steps to Reproduce:
1. Create 3 master and 3 worker nodes cluster with following configuration.
vm_type_bootstrap: "m6g.metal" vm_type_masters: "m6g.metal" vm_type_workers: "m6g.metal" networkType: "OVNKubernetes" region: "us-east-2" masters_azs: ["us-east-2a"] workers_azs: ["us-east-2a"] installer_payload_image: "registry.ci.openshift.org/ocp-arm64/release-arm64:4.11.0"
2. Scale cluster to: 20 worker nodes; No Infra or Workload nodes.
3. Execute Kube burner test (see repo link above) and set JOB_ITERATIONS=240 (I had initially tested with 160 jobs, then added additional 80 iterations).
Actual results: SystemMemoryExceedsReservation alerts are being fired on some worker nodes.
Other than that, cluster appears to be healthy, number of pods per worker node was well below 200/250, cluster is accessible and no unexpected cluster operators degradation.
Expected results: No SystemMemoryExceedsReservation alerts are expected since these machines are quite powerful to be able to handle this load.
Additional info:
The goal of the test was to find out 4.11 baselines for future reference. However, noticing these alerts which look like false positives.
Also, found following article which indicates the issue as false positives found in older versions (4.8). Support for ARM and baremetal is relatively newer in 4.11 and may have same issue?
https://access.redhat.com/solutions/5788171
Also, based on suggestions in:
and
https://access.redhat.com/solutions/5843241
checked the information on the node and did not find systemReserved set automatically or by default.