-
Bug
-
Resolution: Done
-
 Undefined
Undefined
-
4.19, 4.20.0
Context:
- https://redhat-internal.slack.com/archives/C01CQA76KMX/p1746159892253309
- https://redhat-internal.slack.com/archives/C01CQA76KMX/p1745588996550679?thread_ts=1745583568.794629&cid=C01CQA76KMX
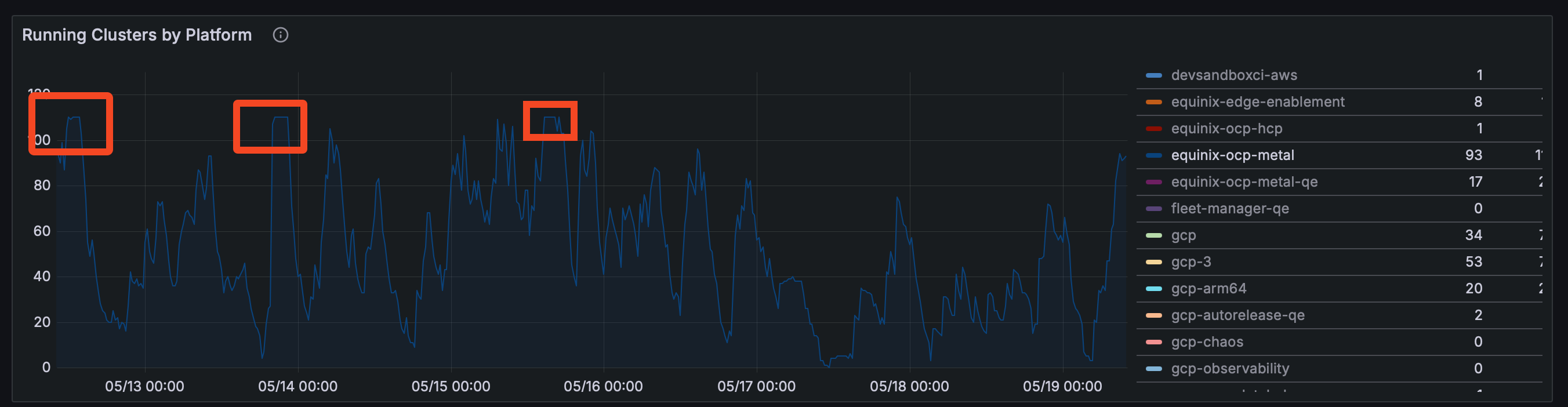
Metal has allocated 90 boskos leases; which through OFCIR redirects to either IBM Cloud, internal infrastructure, or Equinix cloud instances. This is not enough; we're frequently hitting capacity and having 0 free leases. 90 improved the situation, but I think 105 is the minimum to run the current load.
Alternative approach would be to spread out jobs more. There are 14 jobs per nightly stream, many of those informers could be moved to daily/twice-daily crons which could run middle of the night US eastern time which would spread out the load. We'd not lose regression protection as it would still be monitored by component readiness, and we'd smooth the lease utilization more.
Increasing job timeouts is not an acceptable solution, it delays getting release payloads. If a metal job takes 6h and it needs a retry, 12 hours is too long.

{kind=link}