-
Bug
-
Resolution: Done
-
 Critical
Critical
-
None
-
4.12.0
-
Quality / Stability / Reliability
-
False
-
-
None
-
Critical
-
None
-
None
-
Rejected
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
Description of problem:
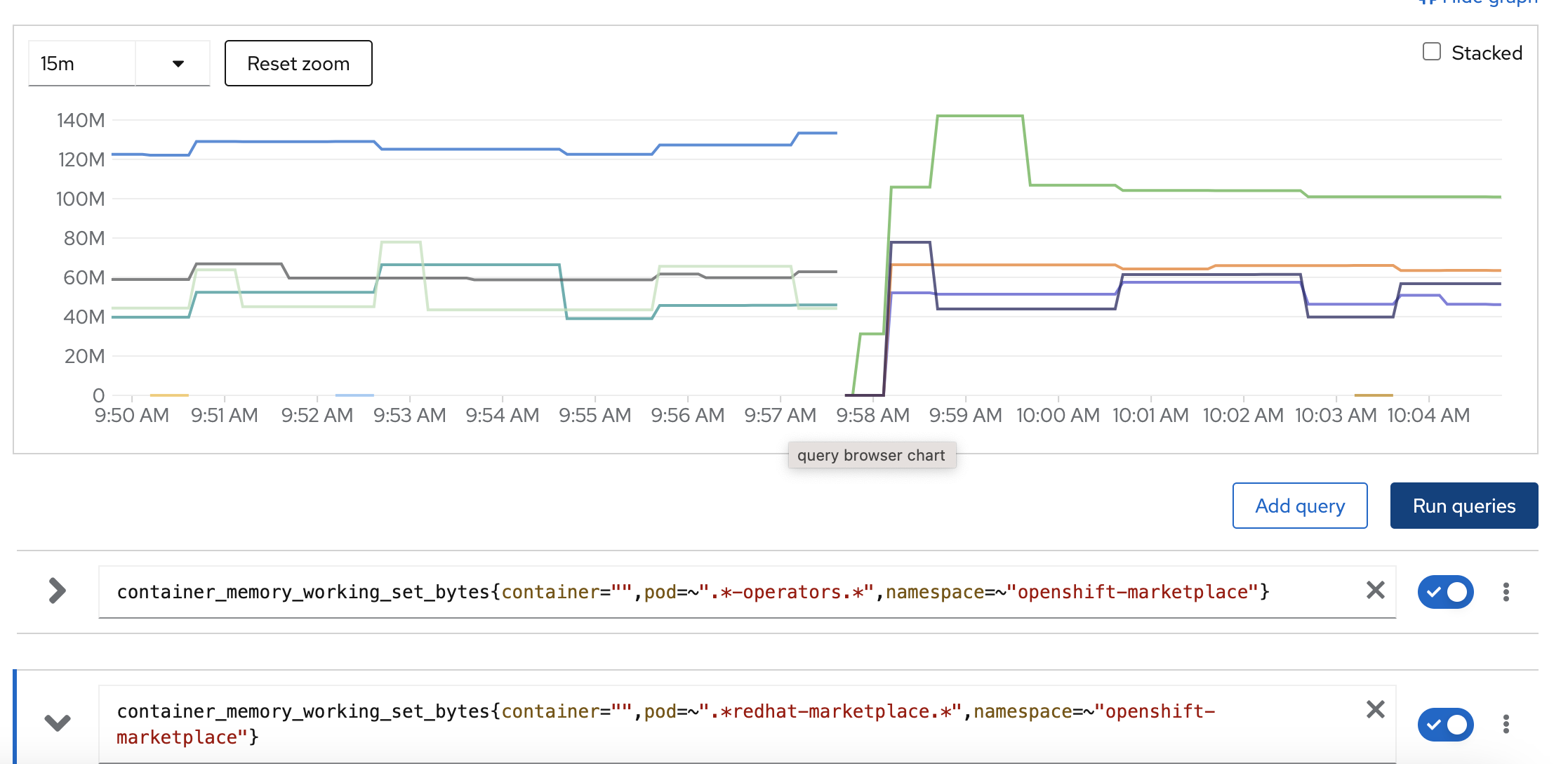
In OCP 4.12, OLM catalog images serve data from a file-based catalog. During startup, the server reads the FBC to generate a cache on the filesystem so that queries are fast and so that baseline memory remains low. However, in comparison to older sqlite-based servers, the startup process has a longer duration and uses more memory due to YAML/JSON unmarshaling and re-structuring of the data to align with OLM's GRPC API. As a result, this causes catalog pods to allocate memory beyond their requests and to fail health probes that expect the pod to become healthy much faster.
Version-Release number of selected component (if applicable):
How reproducible:
Always
Steps to Reproduce:
1. Simultaneously create catalog sources using images "registry.redhat.io/redhat/redhat-operator-index:v4.12" and "registry.redhat.io/redhat/redhat-operator-index:v4.10" in the openshift-marketplace namespace
2. Observe catalog source status and note that startup time with the 4.12 image is is noticably longer than startup time of the 4.10 image (which is sqlite based)
3. Observe memory usage of catalog pods and not that the 4.12 catalog pod has a large memory spike during startup that the 4.10 image does not have.
- Prometheus query: sum (container_memory_rss{namespace='openshift-marketplace',container="",pod!="",pod=~".*-catalog.*"}) by (pod)
Actual results:
There is a startup time and memory spike regression in the 4.12 images.
Expected results:
There is no (or at least a very limited) startup time and memory spike regression in the 4.12 images.
Additional info:
In standard OCP clusters, the OLM has already resolved the health probe issue by introducing a startupProbe that accounts for the potential of a longer startup time. However, Hypershift uses custom catalog pod specs and did not inherit this part of the fix.
- is blocked by
-
OPRUN-2726 downstream opm server change to use pre-existent cache
-

- Closed
-
- is caused by
-
-

- New
-
- is related to
-
-
- Closed
-
