-
Bug
-
Resolution: Unresolved
-
 Undefined
Undefined
-
None
-
4.18.0
-
None
-
Quality / Stability / Reliability
-
False
-
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
Description of problem:
Some time ago, a test ([sig-arch] all leases in ns/%s must gracefully release) checking for graceful lease releases was added to openshift/origin.
The test verifies whether components/operators release their leases gracefully so that the next instance/replica can quickly acquire a new lease and start its work.
However, based on this query, it appears that the test frequently 'fails' for various operators.
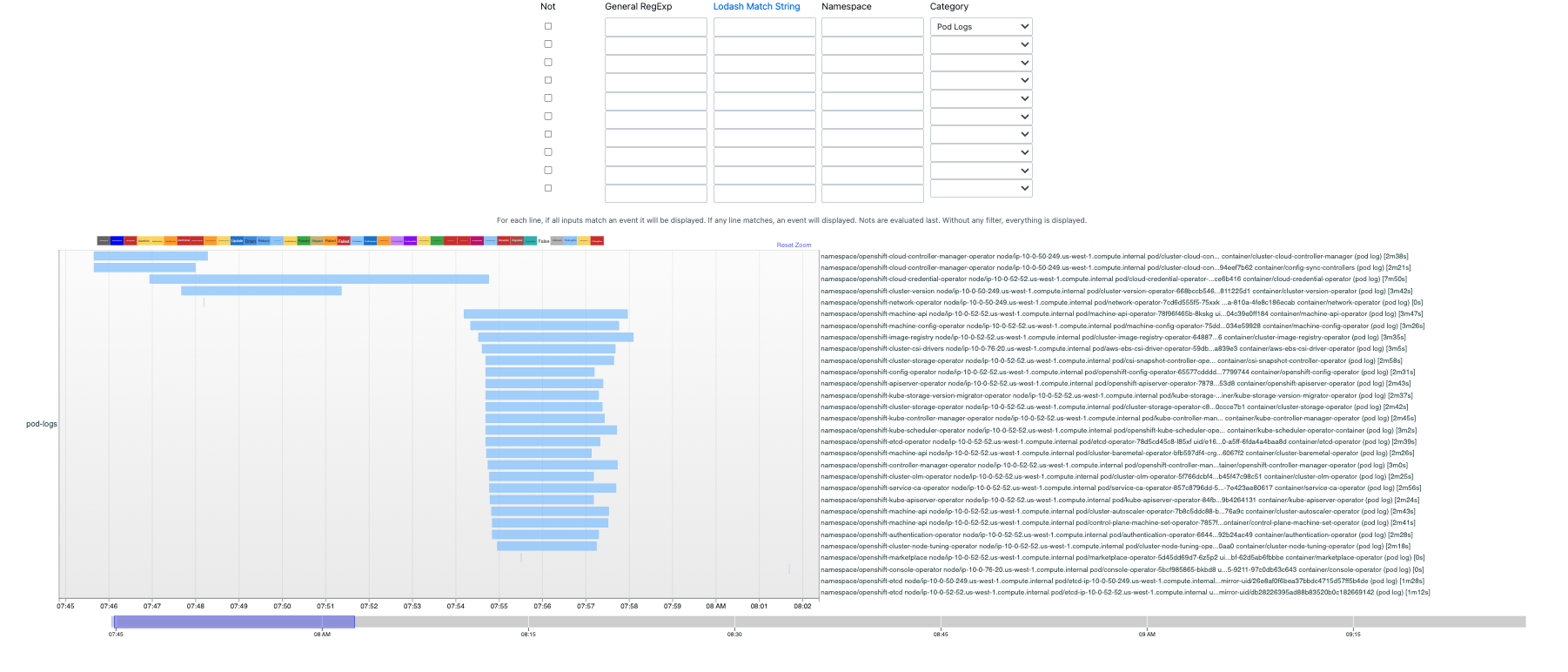
Here is an example of a failed CI run where the 'openshift-kube-apiserver-operator' waited 144 seconds before acquiring a lease.
For operators using library-go, the worst non-graceful lease acquisition time is 2m43s, while the worst graceful lease acquisition time is 26s.
I'm also attaching a timeline from the same run, which shows that lease acquisition took longer for other components around the same time.
We should investigate why, in some cases, components/operators take longer to acquire their leases.
The suspicion is that leases are not released gracefully due to server unavailability, which may result from etcd unavailability. However, I don't have data to support this theory.
Note: This issue might be connected to https://issues.redhat.com/browse/OCPBUGS-42087 and a few other failures. It is possible that all of them share the same root cause.