-
Bug
-
Resolution: Not a Bug
-
 Normal
Normal
-
None
-
4.12
-
Quality / Stability / Reliability
-
False
-
-
None
-
None
-
None
-
None
-
None
-
None
-
OCPNODE Sprint 238 (Blue)
-
1
-
None
-
None
-
None
-
None
-
None
-
None
-
None
Description of problem:
Run reliability test on AWS SDN cluster with 3 masters, 2 RHCOS workers 1 RHEL 8.6 workers Hybrid. app build time increased on HREL8.6 node after test run for 4 hours
Version-Release number of selected component (if applicable):
4.12.0-rc.1
How reproducible:
Reproduced on 4.12.0-rc.1 + RHEL 8.6 node 4.11.18-x86_64 + RHEL 8.6 node
Steps to Reproduce:
1. Install a AWS SDN cluster with 3 masters, 2 workers templatehttps://gitlab.cee.redhat.com/aosqe/flexy-templates/-/blob/master/functionality-testing/aos-4_12/ipi-on-aws/versioned-installer-customer_vpc vm_type: m5.xlarge Build: 4.12.0-rc.1 2. Install one RHEL 8.6 worker node. instance_size: m5.xlarge Test1: root_volume_size: "30" Test2: root_volume_size: "30" Test4: root_volume_size: "120" 3. Install dittybopper for monitoring https://github.com/cloud-bulldozer/performance-dashboards 4. Run Reliability-v2 test on the cluster https://github.com/openshift/svt/tree/master/reliability-v2 Reliability test config: Reliability-v2 Default - 1 admin, 15 developers x 2projects
Actual results:
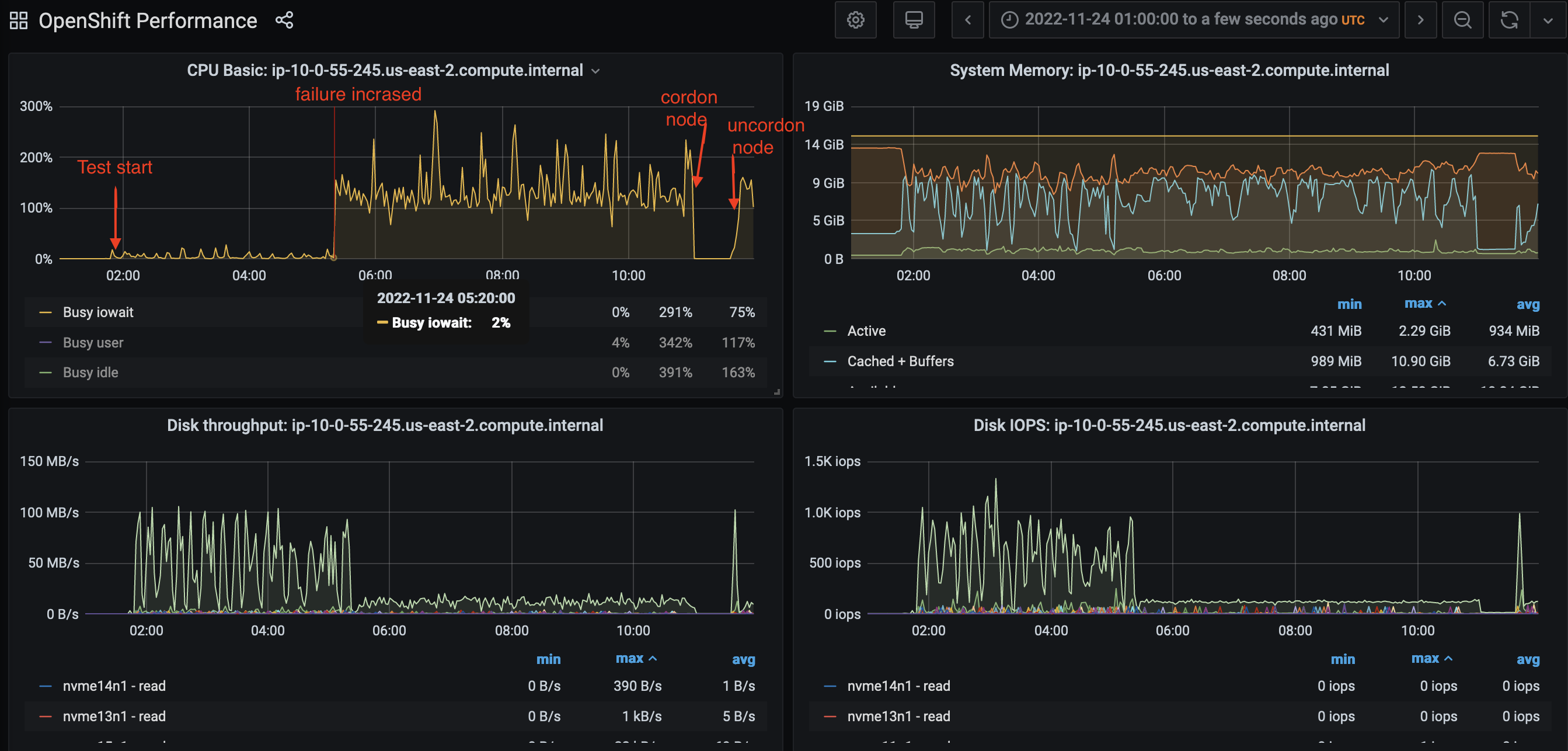
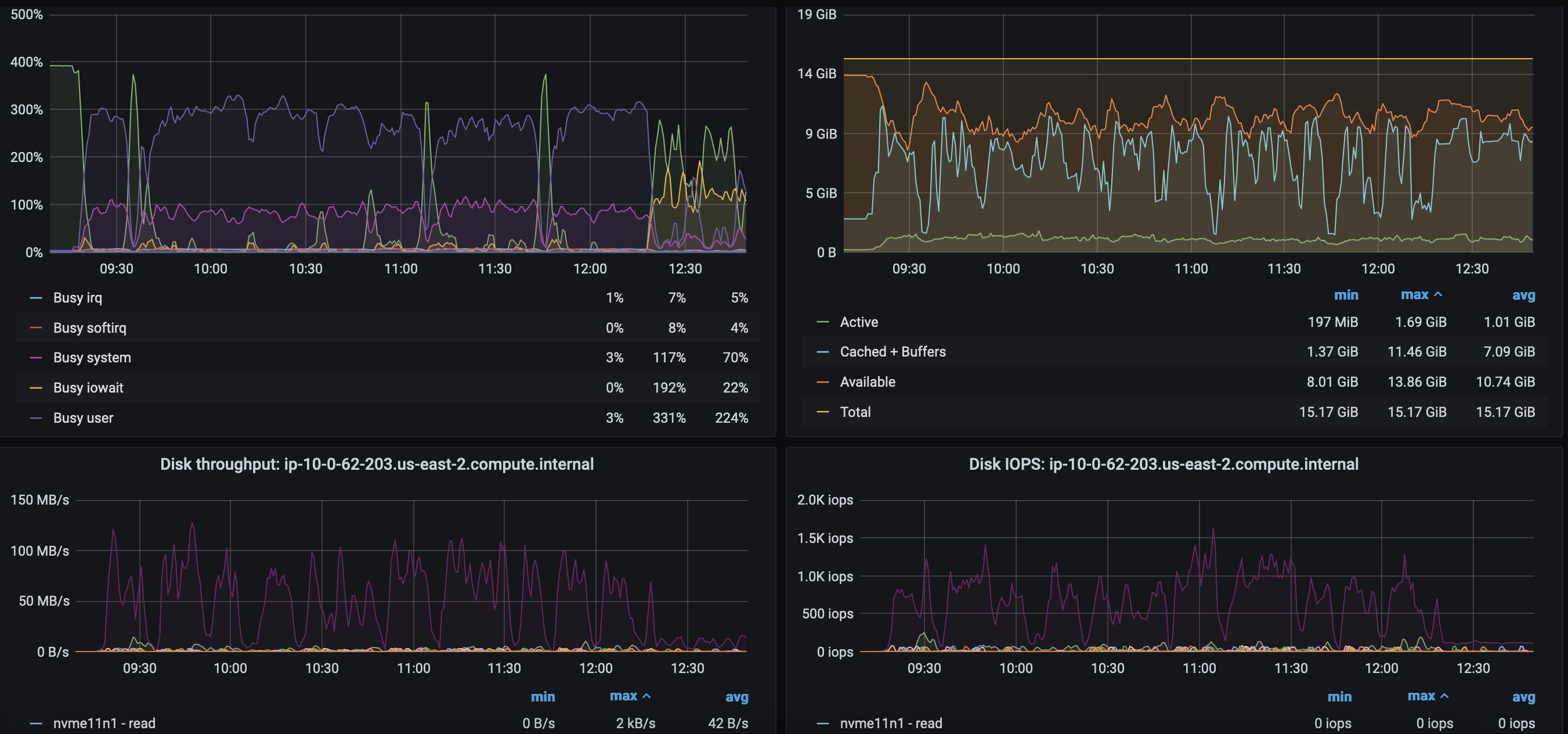
From about [2022-11-24 05:20 UTC], after test run for about 4 hours, new-app test case failure started to increase due to the app build job didn't finish within timeout 30 minutes. The build pods that were running and not complete for 20-30 minutes are all located on the RHEL worker node (10.0.55.245). Checking the pod events, there are some 'Error: context deadline exceeded'. Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 23m default-scheduler Successfully assigned testuser-0-1/cakephp-mysql-persistent-1-build to ip-10-0-55-245.us-east-2.compute.internal Normal AddedInterface 23m multus Add eth0 [10.129.2.114/23] from openshift-sdn Warning Failed 21m kubelet Error: context deadline exceeded Normal Pulled 21m (x2 over 23m) kubelet Container image "quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:05b273a7ff6bd1b0df6015d7f294372c91799982840fdff415c01475347a37a1" already present on machine Normal Created 21m kubelet Created container git-clone Normal Started 21m kubelet Started container git-clone Warning Failed 19m kubelet Error: context deadline exceeded Normal Pulled 19m (x2 over 21m) kubelet Container image "quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:05b273a7ff6bd1b0df6015d7f294372c91799982840fdff415c01475347a37a1" already present on machine Normal Created 18m kubelet Created container manage-dockerfile Normal Started 18m kubelet Started container manage-dockerfile Warning Failed 14m (x2 over 16m) kubelet Error: context deadline exceeded Normal Pulled 14m (x3 over 18m) kubelet Container image "quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:05b273a7ff6bd1b0df6015d7f294372c91799982840fdff415c01475347a37a1" already present on machine Normal Created 12m kubelet Created container sti-build Normal Started 12m kubelet Started container sti-build Checking the dittybopper monitoring dashboards, I found The CPU 'Busy iowait' increased a lot and the Disk throughput Disk IOPS decreased since that time [2022-11-24 05:20 UTC].
Expected results:
RHEL worker nodes should work without problem like RHCOS worker nodes.
Additional info:
3 master nodes, 2 are RHCOS workernodes, 1 is RHEL worker node(10.0.55.245).
# oc get nodes -o wide NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME ip-10-0-48-219.us-east-2.compute.internal Ready worker 2d1h v1.25.2+cd98eda 10.0.48.219 <none> Red Hat Enterprise Linux CoreOS 412.86.202211142021-0 (Ootpa) 4.18.0-372.32.1.el8_6.x86_64 cri-o://1.25.1-2.rhaos4.12.gitafa0c57.el8 ip-10-0-49-122.us-east-2.compute.internal Ready control-plane,master 2d1h v1.25.2+cd98eda 10.0.49.122 <none> Red Hat Enterprise Linux CoreOS 412.86.202211142021-0 (Ootpa) 4.18.0-372.32.1.el8_6.x86_64 cri-o://1.25.1-2.rhaos4.12.gitafa0c57.el8 ip-10-0-55-245.us-east-2.compute.internal Ready worker 26h v1.25.2+5533733 10.0.55.245 <none> Red Hat Enterprise Linux 8.6 (Ootpa) 4.18.0-425.3.1.el8.x86_64 cri-o://1.25.1-5.rhaos4.12.git6005903.el8 ip-10-0-69-142.us-east-2.compute.internal Ready control-plane,master 2d1h v1.25.2+cd98eda 10.0.69.142 <none> Red Hat Enterprise Linux CoreOS 412.86.202211142021-0 (Ootpa) 4.18.0-372.32.1.el8_6.x86_64 cri-o://1.25.1-2.rhaos4.12.gitafa0c57.el8 ip-10-0-73-55.us-east-2.compute.internal Ready worker 2d1h v1.25.2+cd98eda 10.0.73.55 <none> Red Hat Enterprise Linux CoreOS 412.86.202211142021-0 (Ootpa) 4.18.0-372.32.1.el8_6.x86_64 cri-o://1.25.1-2.rhaos4.12.gitafa0c57.el8 ip-10-0-74-109.us-east-2.compute.internal Ready control-plane,master 2d1h v1.25.2+cd98eda 10.0.74.109 <none> Red Hat Enterprise Linux CoreOS 412.86.202211142021-0 (Ootpa) 4.18.0-372.32.1.el8_6.x86_64 cri-o://1.25.1-2.rhaos4.12.gitafa0c57.el8
Test started at : [2022-11-24 01:45:27 UTC]
Not sure if this is an coincidence, on [2022-11-24 05:22:37 UTC], there is an ingress upgrade.
[2022-11-24 05:22:37 UTC] @Qiujie Li - qili , Operator progressing: ingress 4.12.0-rc.1 True True False 44h ingresscontroller "default" is progressing: IngressControllerProgressing: One or more status conditions indicate progressing: DeploymentRollingOut=True (DeploymentRollingOut: Waiting for router deployment rollout to finish: 1 of 2 updated replica(s) are available......
After that the failure of new_app started to increase
OCP Reliability APP 6 hours ago [2022-11-24 05:48:14 UTC] @Qiujie Li - qili , new_app: visit 'rails-pgsql-persistent-testuser-7-1.apps.qili-preserve-aws.qe-lrc.devcluster.openshift.com' failed after 30 minutes. status_code: 503. Wait more 5 minutes for manual debug. OCP Reliability APP 6 hours ago [2022-11-24 05:48:39 UTC] @Qiujie Li - qili , new_app: visit 'rails-pgsql-persistent-testuser-0-0.apps.qili-preserve-aws.qe-lrc.devcluster.openshift.com' failed after 30 minutes. status_code: 503. Wait more 5 minutes for manual debug.
Checked the dittybopper dashboard
The CPU 'Busy iowait' increased a lot since about [2022-11-24 05:20], the Disk throughput Disk IOPS decreased
On [10:37] I cordoned the RHEL worker node(10.0.55.245), and scaled up one RHCOS worker. The CPU 'Busy iowait' decreased.
oc adm cordon ip-10-0-55-245.us-east-2.compute.internal oc scale --replicas=2 machinesets -n openshift-machine-api qili-preserve-aws-nssnr-worker-us-east-2b
Later I uncordon the RHEL worker, The CPU 'Busy iowait' increased again.
Please check attached picture 'rhel_cpu_disk'
The node log of the RHEL worker node(10.0.55.245) is updated to ip-10-0-55-245.us-east-2.compute.internal-2022-11-24-05-06.log.zip.
Disk usage on the RHEL worker node(10.0.55.245).
sh-4.4# df -lh Filesystem Size Used Avail Use% Mounted on /dev/nvme0n1p2 30G 17G 14G 57% / sh-4.4# du -h -d 1 / 0 /tmp 0 /mnt 0 /dev 53G /var 0 /sys 0 /opt 0 /proc 102M /run 16K /home 24K /root 27M /etc ... sh-4.4# du -h -d 1 /var 0 /var/games 0 /var/preserve 0 /var/tmp 50G /var/lib 0 /var/db 0 /var/gopher 0 /var/local 12K /var/spool 0 /var/yp 0 /var/kerberos 0 /var/crash 0 /var/adm 0 /var/empty 0 /var/nis 1019M /var/log 601M /var/cache 0 /var/ftp 0 /var/opt 51G /var