-
Bug
-
Resolution: Not a Bug
-
 Major
Major
-
None
-
4.12.z
-
None
-
Quality / Stability / Reliability
-
False
-
-
None
-
Important
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
Description of problem:
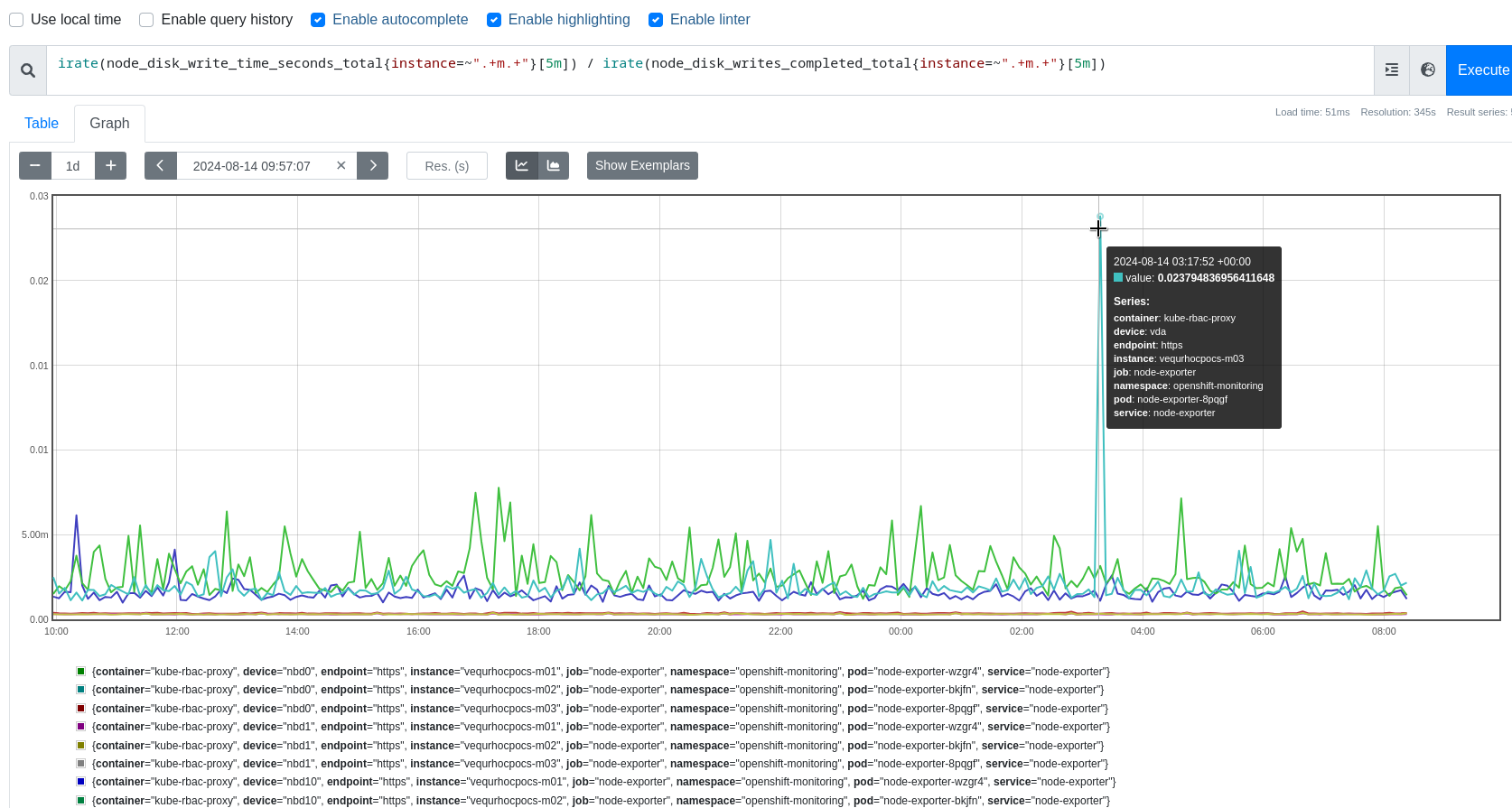
The Gloo and Volt Applications running in multiple namespaces use Kubernetes Lease to perform Leader Election and sometimes the applications crash because of Kube-api's high response time.
Additional info:
The Application logs before it crashes show multiple timeouts:
The Gloo and Volt Applications in multiple namespaces use Kubernetes Lease to perform Leader Election.
Sometimes happens the applications crash because of Kube-api's high response time.
2024-07-27T21:33:36.386331860Z E0727 21:33:36.386287 1 leaderelection.go:367] Failed to update lock: etcdserver: request timed out
2024-07-27T21:33:39.380015042Z E0727 21:33:39.379957 1 leaderelection.go:330] error retrieving resource lock openet-provisioning/gloo: Get "https://172.30.0.1:443/apis/coordination.k8s.io/v1/namespaces/openet-provisioning/leases/gloo": context deadline exceeded
2024-07-27T21:33:39.380015042Z I0727 21:33:39.380008 1 leaderelection.go:283] failed to renew lease openet-provisioning/gloo: timed out waiting for the condition
2024-07-27T21:33:39.380055284Z E0727 21:33:39.380034 1 leaderelection.go:306] Failed to release lock: resource name may not be empty
In Kube-apiserver logs we can see the following:
$ for pod in $(omc -n openshift-kube-apiserver get pod -oname | grep kube-apiserver-vequrhocpocs-m0); do echo $pod; omc -n openshift-kube-apiserver logs $pod kube-apiserver | grep -A2 'openet-provisioning/leases/gloo' | grep 2024-07-27T21:33 ; done
pod/kube-apiserver-vequrhocpocs-m01
pod/kube-apiserver-vequrhocpocs-m02
2024-07-27T21:33:36.385416768Z I0727 21:33:36.385395 18 trace.go:205] Trace[516070347]: "Update" url:/apis/coordination.k8s.io/v1/namespaces/openet-provisioning/leases/gloo,user-agent:gloo/v0.0.0 (linux/amd64) kubernetes/$Format/leader-election,audit-id:f1035a7b-36b1-45e9-985c-241693d628a1,client:10.30.65.31,accept:application/json, */*,protocol:HTTP/2.0 (27-Jul-2024 21:33:29.383) (total time: 7001ms):
2024-07-27T21:33:36.385416768Z Trace[516070347]: ---"Write to database call finished" len:740,err:etcdserver: request timed out 7001ms (21:33:36.385)
2024-07-27T21:33:36.385416768Z Trace[516070347]: [7.001910514s] [7.001910514s] END
2024-07-27T21:33:39.383488939Z I0727 21:33:39.383447 18 trace.go:205] Trace[699849289]: "Get" url:/apis/coordination.k8s.io/v1/namespaces/openet-provisioning/leases/gloo,user-agent:gloo/v0.0.0 (linux/amd64) kubernetes/$Format/leader-election,audit-id:8d6d239c-c523-4e91-baaf-a163cb5d8636,client:10.30.65.31,accept:application/json, */*,protocol:HTTP/2.0 (27-Jul-2024 21:33:38.388) (total time: 995ms):
2024-07-27T21:33:39.383488939Z Trace[699849289]: [995.004036ms] [995.004036ms] END
2024-07-27T21:33:39.383625431Z E0727 21:33:39.383600 18 timeout.go:141] post-timeout activity - time-elapsed: 3.680219ms, GET "/apis/coordination.k8s.io/v1/namespaces/openet-provisioning/leases/gloo" result: <nil>
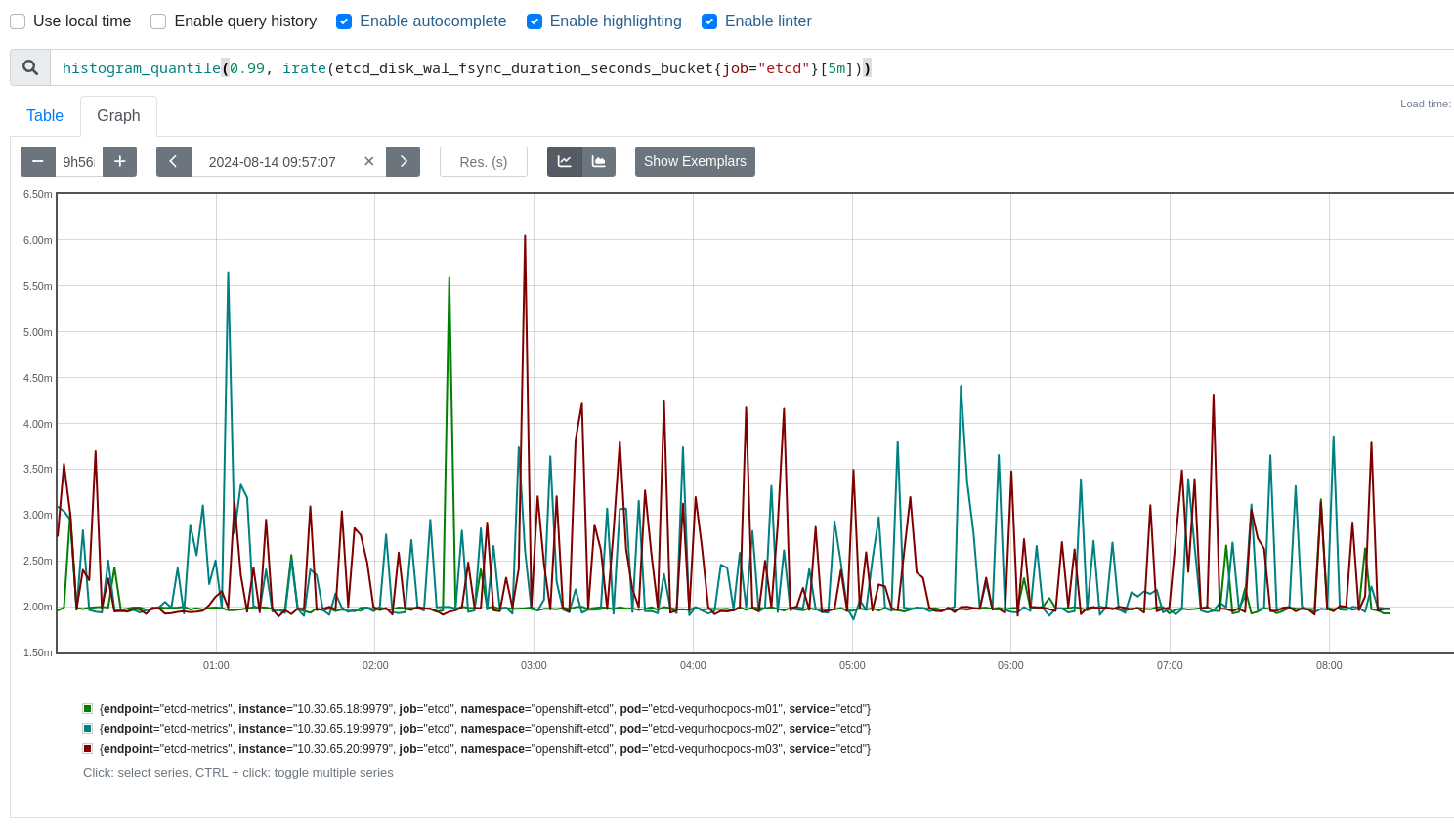
In ETCD logs:
for pod in $(omc -n openshift-etcd get pod -oname | grep etcd-vequrhocpocs-m); do echo $pod; omc -n openshift-etcd logs $pod etcd | grep 2024-07-27T21:33 | grep -e 'leases/openet-provisioning/gloo' -e 'slow network' -e 'slow fdatasync' ; done
pod/etcd-vequrhocpocs-m01
pod/etcd-vequrhocpocs-m02
2024-07-27T21:33:36.196752362Z {"level":"warn","ts":"2024-07-27T21:33:36.196658Z","caller":"etcdserver/v3_server.go:909","msg":"timed out waiting for read index response (local node might have slow network)","timeout":"7s"}
2024-07-27T21:33:39.380291042Z {"level":"warn","ts":"2024-07-27T21:33:39.380212Z","caller":"etcdserver/util.go:170","msg":"apply request took too long","took":"991.495725ms","expected-duration":"200ms","prefix":"read-only range ","request":"key:\"/kubernetes.io/leases/openet-provisioning/gloo\" ","response":"","error":"context canceled"}
2024-07-27T21:33:39.380291042Z {"level":"info","ts":"2024-07-27T21:33:39.380271Z","caller":"traceutil/trace.go:171","msg":"trace[1738619559] range","detail":"{range_begin:/kubernetes.io/leases/openet-provisioning/gloo; range_end:; }","duration":"991.574163ms","start":"2024-07-27T21:33:38.388685Z","end":"2024-07-27T21:33:39.38026Z","steps":["trace[1738619559] 'agreement among raft nodes before linearized reading' (duration: 991.494234ms)"],"step_count":1}
2024-07-27T21:33:39.380341698Z {"level":"warn","ts":"2024-07-27T21:33:39.3803Z","caller":"v3rpc/interceptor.go:197","msg":"request stats","start time":"2024-07-27T21:33:38.388676Z","time spent":"991.61874ms","remote":"[::1]:38054","response type":"/etcdserverpb.KV/Range","request count":0,"request size":48,"response count":0,"response size":0,"request content":"key:\"/kubernetes.io/leases/openet-provisioning/gloo\" "}
2024-07-27T21:33:41.269998667Z {"level":"warn","ts":"2024-07-27T21:33:41.269905Z","caller":"wal/wal.go:805","msg":"slow fdatasync","took":"12.084562092s","expected-duration":"1s"}
pod/etcd-vequrhocpocs-m03
Additional information about the ETCD storage:
1. ETCD disk: vdb
2. Control Plane nodes virtualized on OSP.
3. The vdb disk is ephemeral, encrypted and backed by a raid controller "RAID 5".
Due to this timeout, the Gloo application in production crashes, and the pod restarts. We would like your help to understand why sometimes this issue occurs.
{kind=link}
{kind=link}