Description of problem:
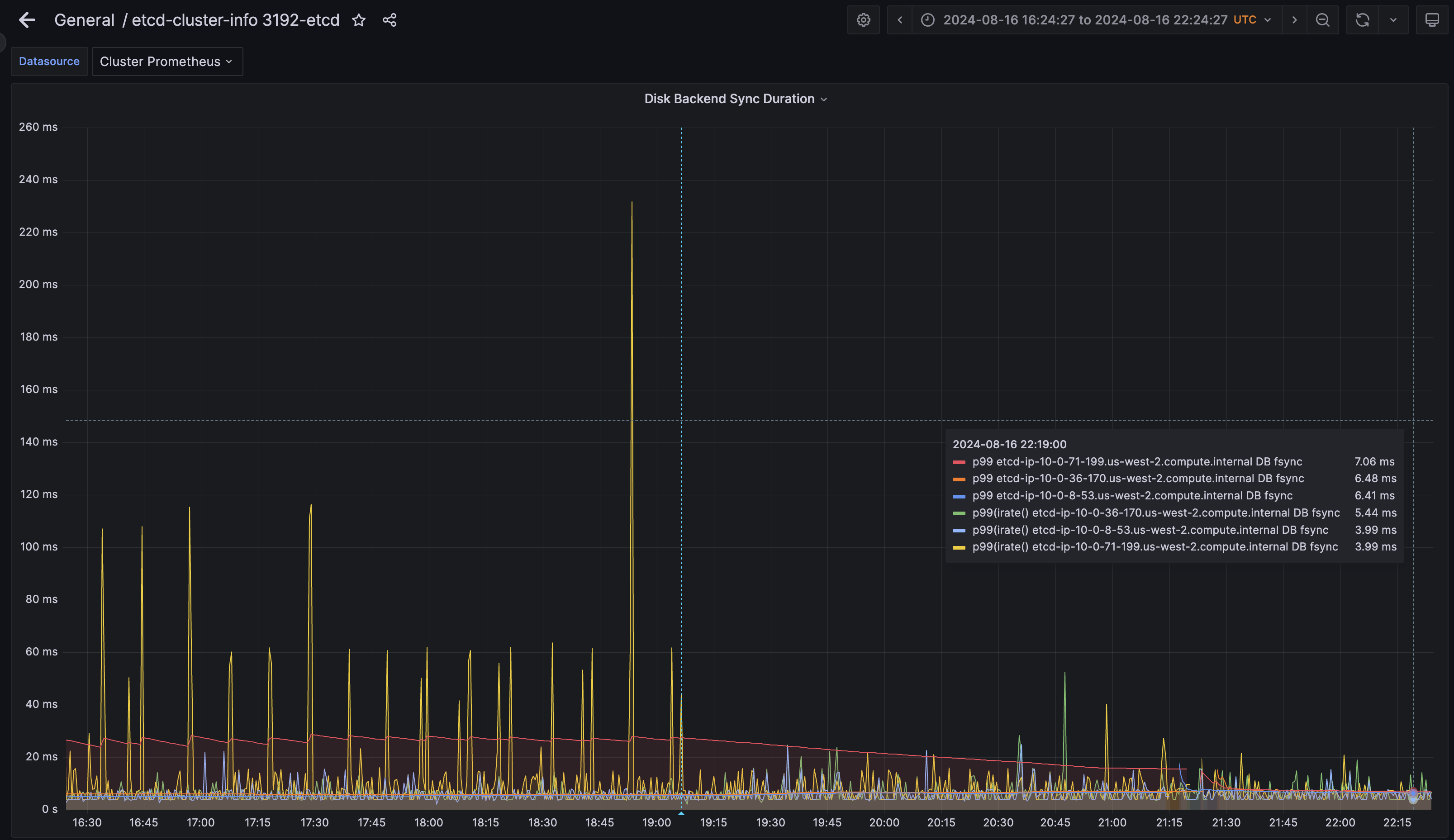
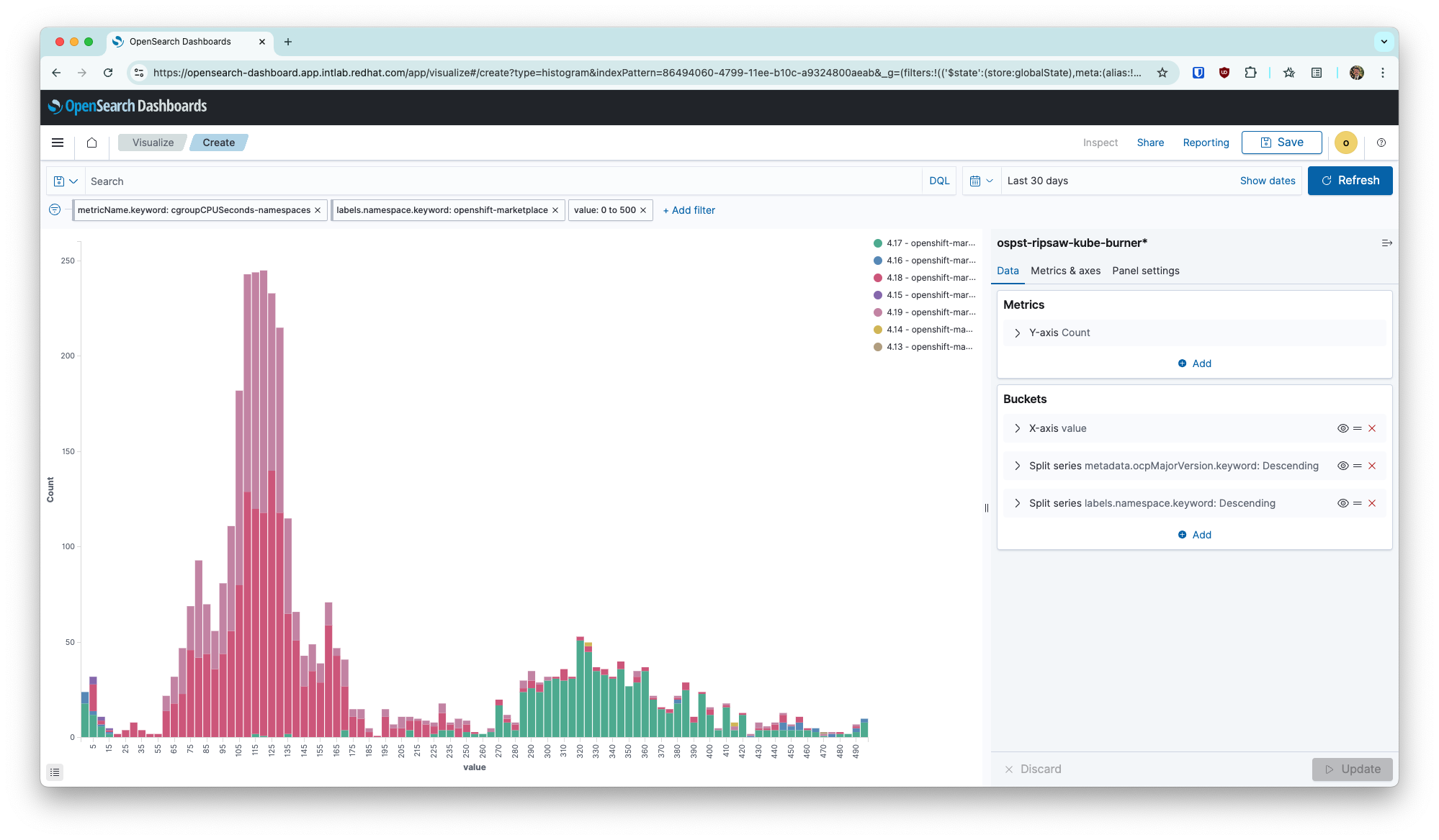
On a freshly installed cluster, etcd disk sync latencies (backend and WAL sync durations) sit higher than the SLAs (10ms) and leave one etcd member considerably higher than the other two. (example: 23ms, 6ms, 6ms) Looking further into the metrics, each time one of the default four CatalogSources spawn a pod, this pod writes ~1GB worth of data to disk, increments writes_merge by ~5k, and spikes both WAL and backend sync durations for etcd. The magnitude of this spike is higher than we are even able to reproduce with `fio`. (At least, as of today.)
Version-Release number of selected component (if applicable):
4.16.0-0.nightly-2024-08-19-053157 4.15.0-0.nightly-2024-08-19-025745
How reproducible:
100%
Steps to Reproduce:
1. Install a cluster
2. Plot the following queries:
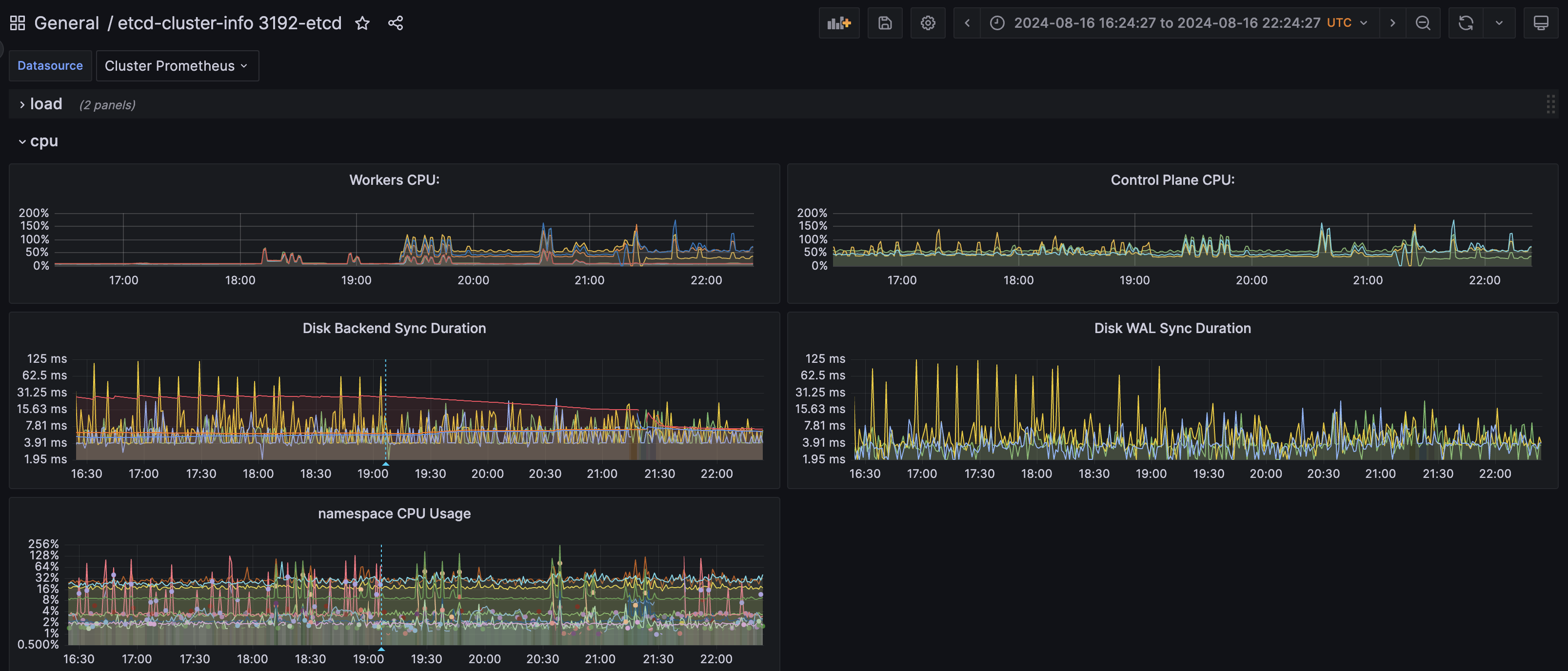
changes in etcd DB sync latency: histogram_quantile(0.99, sum(irate(etcd_disk_backend_commit_duration_seconds_bucket{namespace="openshift-etcd"}[2m])) by (pod, le))
changes in etcd WAL sync latency: histogram_quantile(0.99, sum(irate(etcd_disk_wal_fsync_duration_seconds_bucket{namespace="openshift-etcd"}[2m])) by (pod, le))
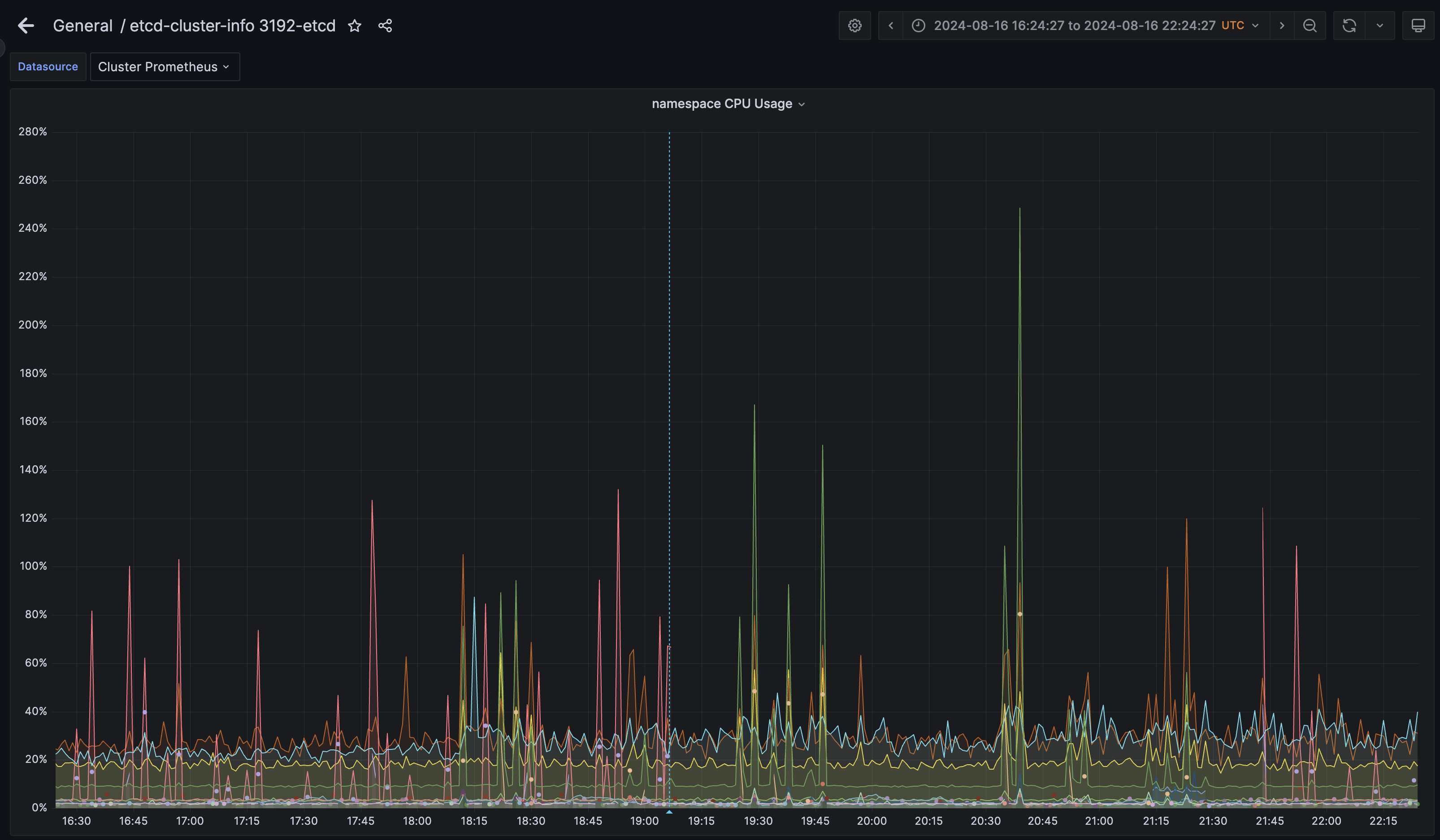
namespace cpu usage: topk( 10 , sum( irate(container_cpu_usage_seconds_total{container!~"POD|",namespace=~"openshift-.*"}[$interval])*100 ) by (namespace) )
Actual results:
See spikes in CPU from openshift-marketplace namespace that align with spikes in fsync latencies.
Expected results:
Don't see any spikes in etcd latency during stable operation.
Additional info:
I have must-gather and prometheus dumps to share links in the comments. screenshots: Screenshot 2024-08-16 at 17.24.57_etcd_backend-sync_linear copy.png Screenshot 2024-08-16 at 17.25.06_namespace-cpu_full copy.png See this doc for more information: https://docs.google.com/document/d/1xV5g_W2rpyKoVrzn4DdcdrJtvCmr1fGNEsvtZvaL-Jk/edit
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- is duplicated by
-
OCPBUGS-33094 redhat-operator needs a lot of CPU resources every 15 minutes
-

- Closed
-
- is related to
-
-

- Closed
-
- relates to
-
-
- Closed
-
- links to