-
Bug
-
Resolution: Won't Do
-
 Undefined
Undefined
-
None
-
4.17.0
-
Quality / Stability / Reliability
-
False
-
-
3
-
Important
-
None
-
None
-
None
-
Rejected
-
ETCD Sprint 257, ETCD Sprint 258, ETCD Sprint 259
-
3
-
None
-
None
-
None
-
None
-
None
-
None
-
None
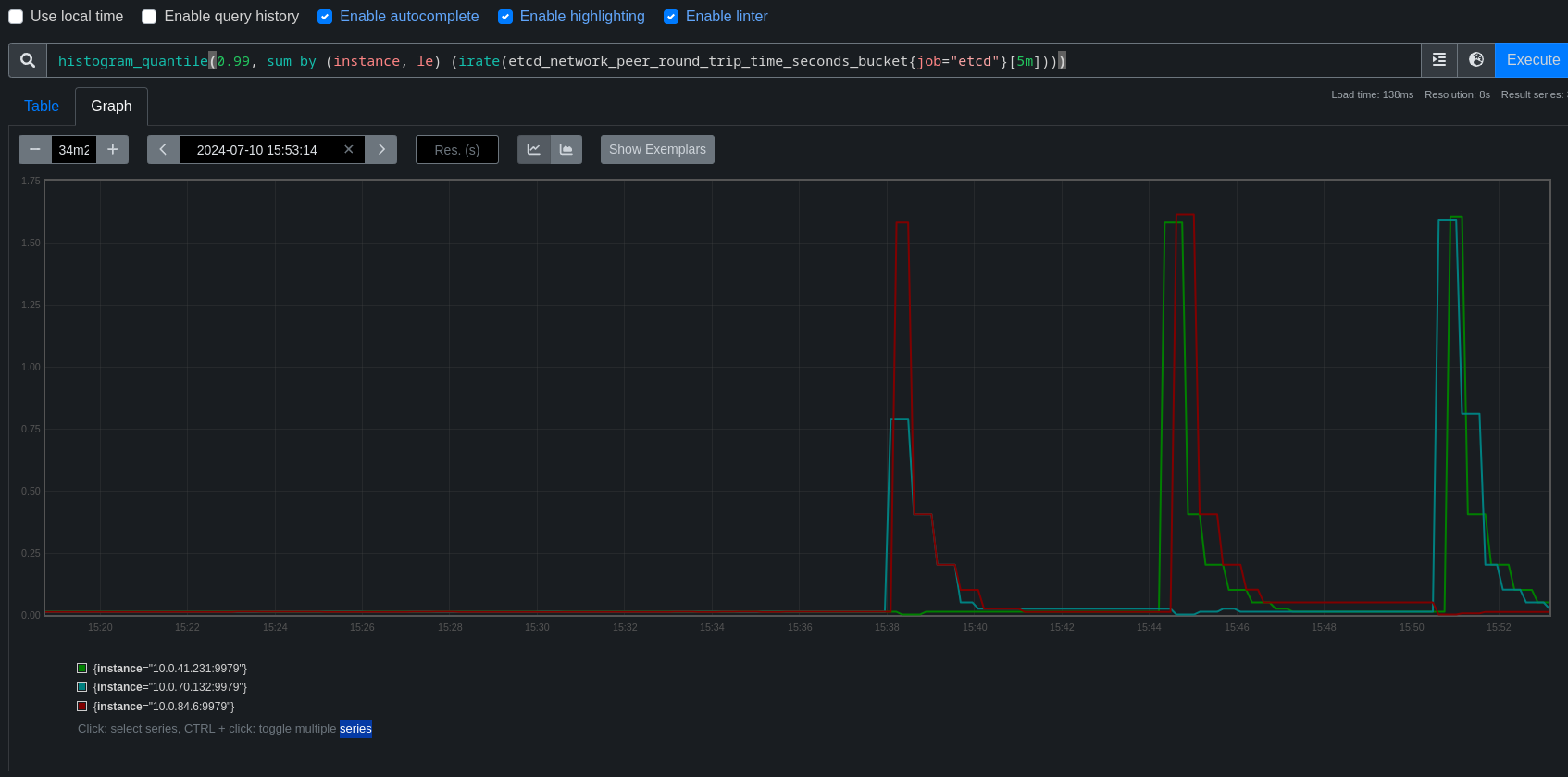
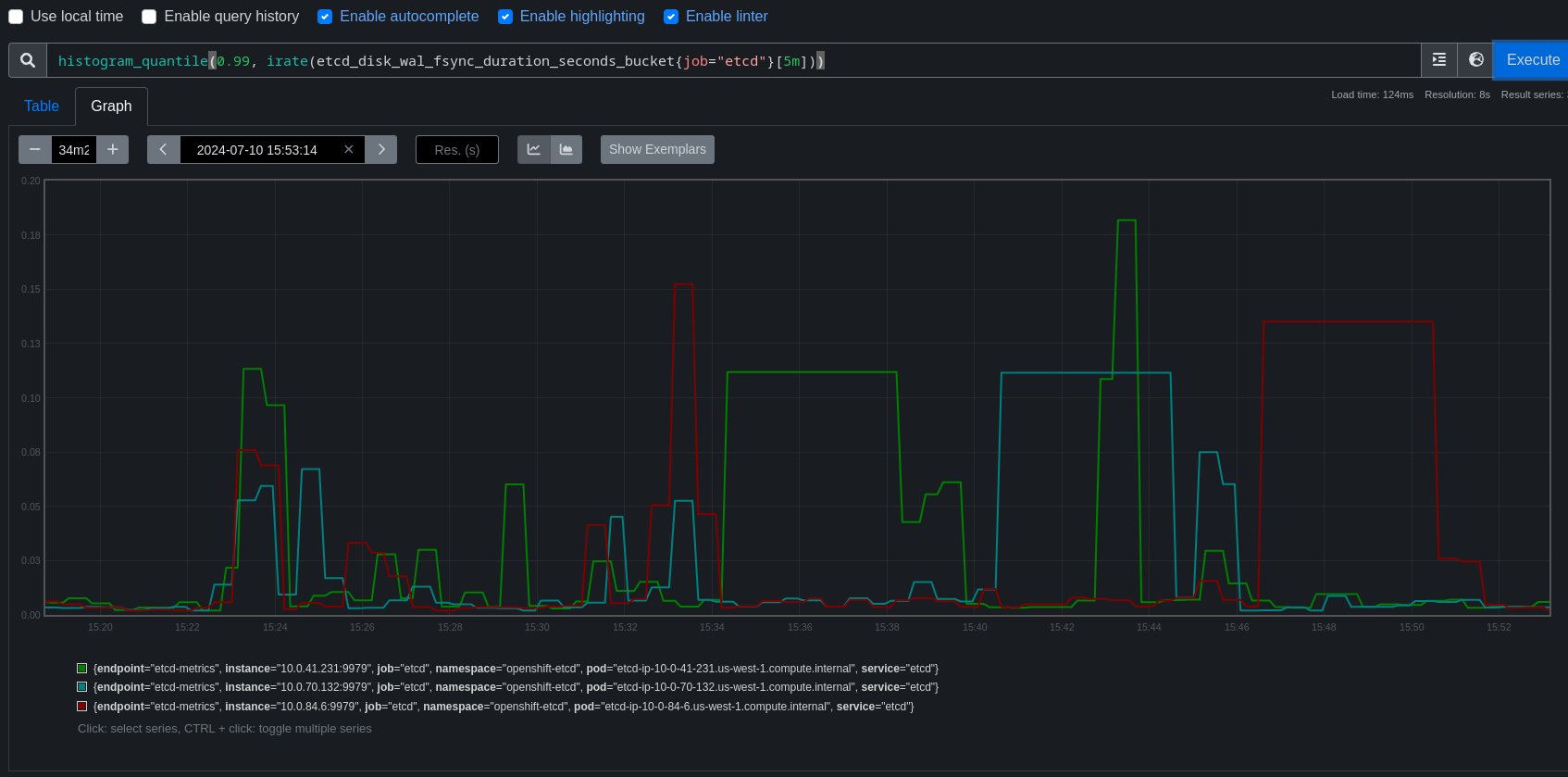
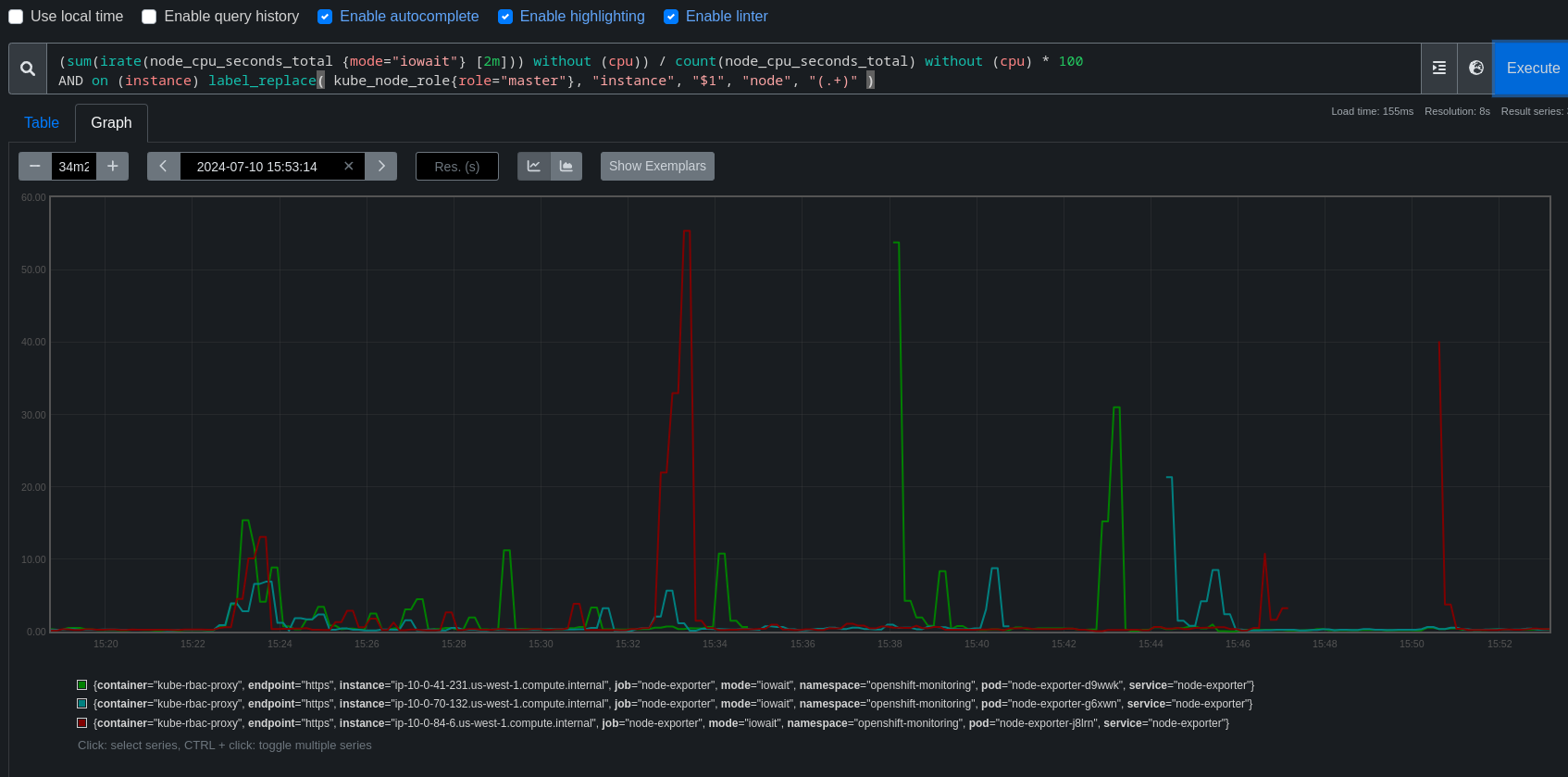
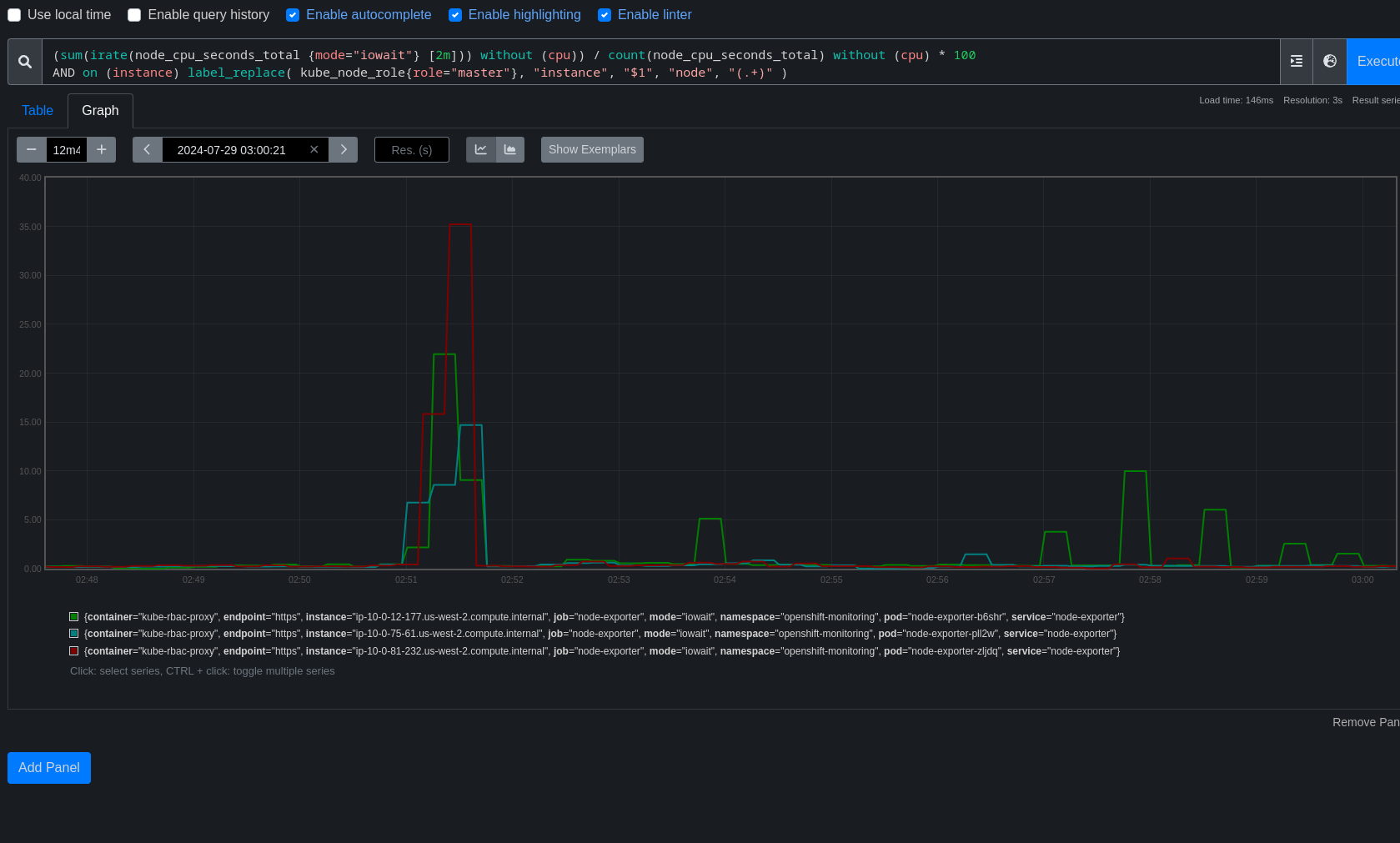
TRT tooling has detected changes in disruption for most kube/openshift/oauth API backends. Data actually looked quite good up until around the end of June, better than 4.16, but then something seems to have changed.
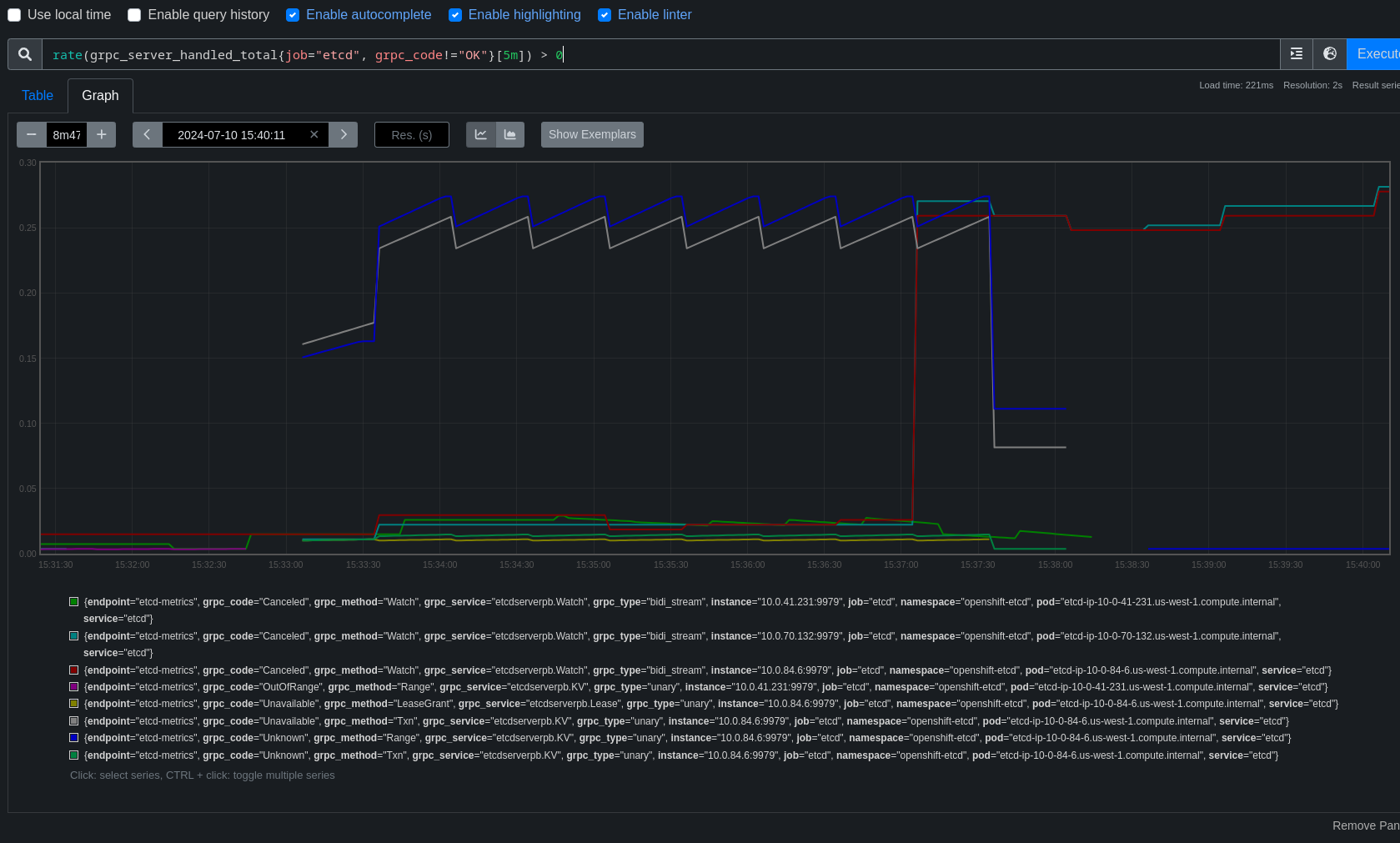
There are a few patterns visible in the job runs, but for this bug we're focusing on one pattern that's fairly easy to find where around the time the kube-apiserver is rolling out a new revision, API endpoints take roughly 4-7s of disruption.
Using this dashboard link, we had a rather consistent P95 of 0s until around June 22-23 and things begin getting erratic.
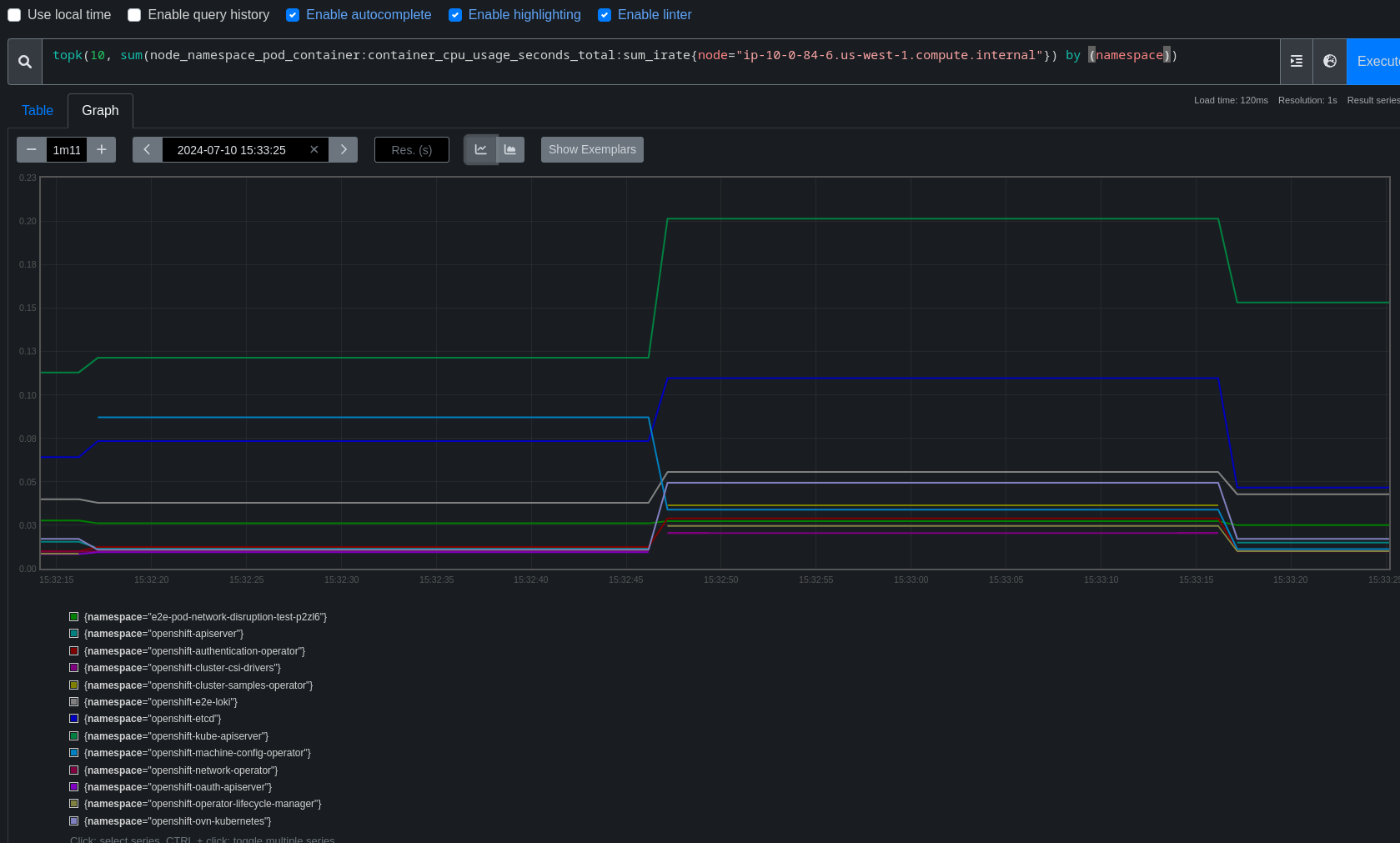
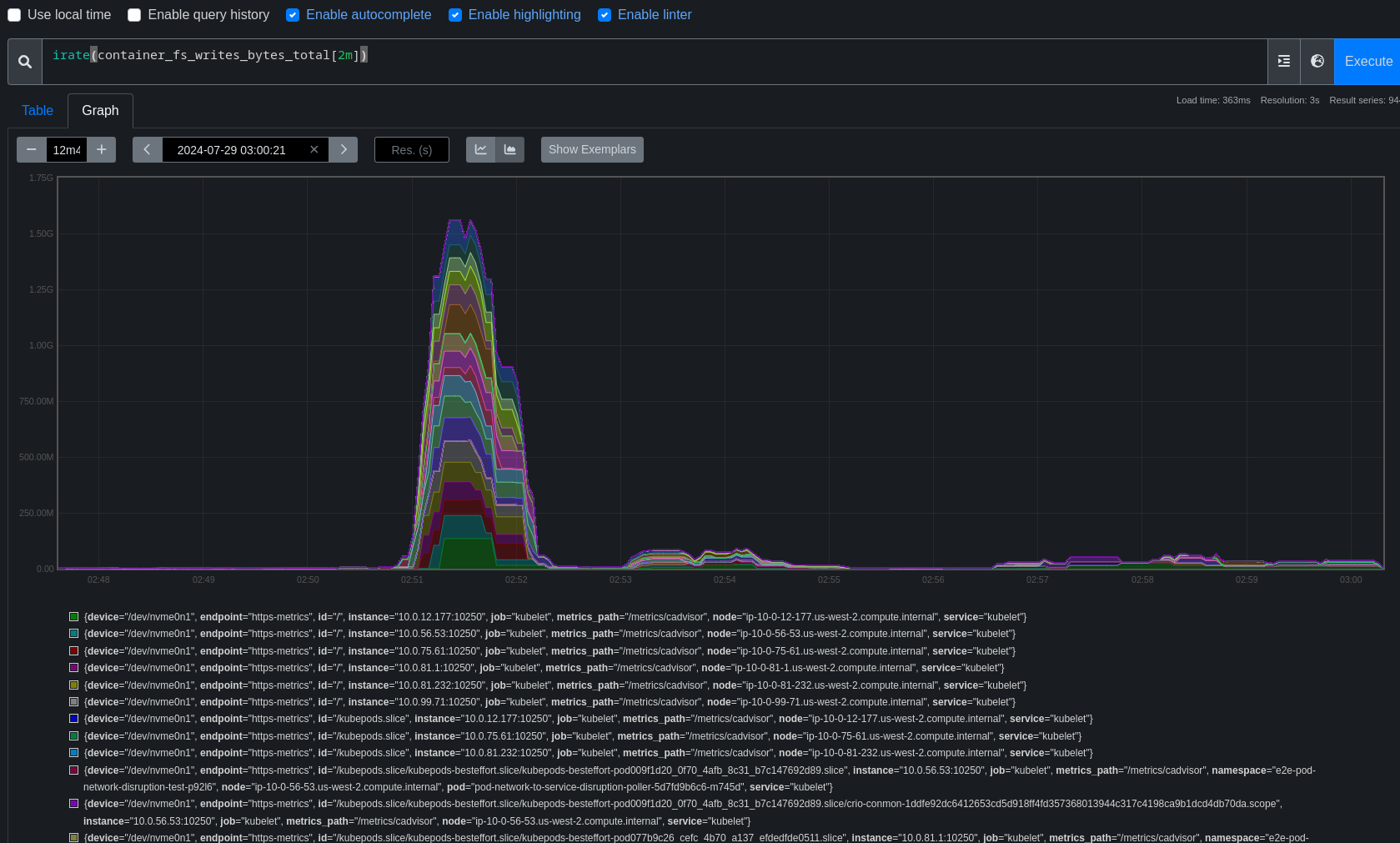
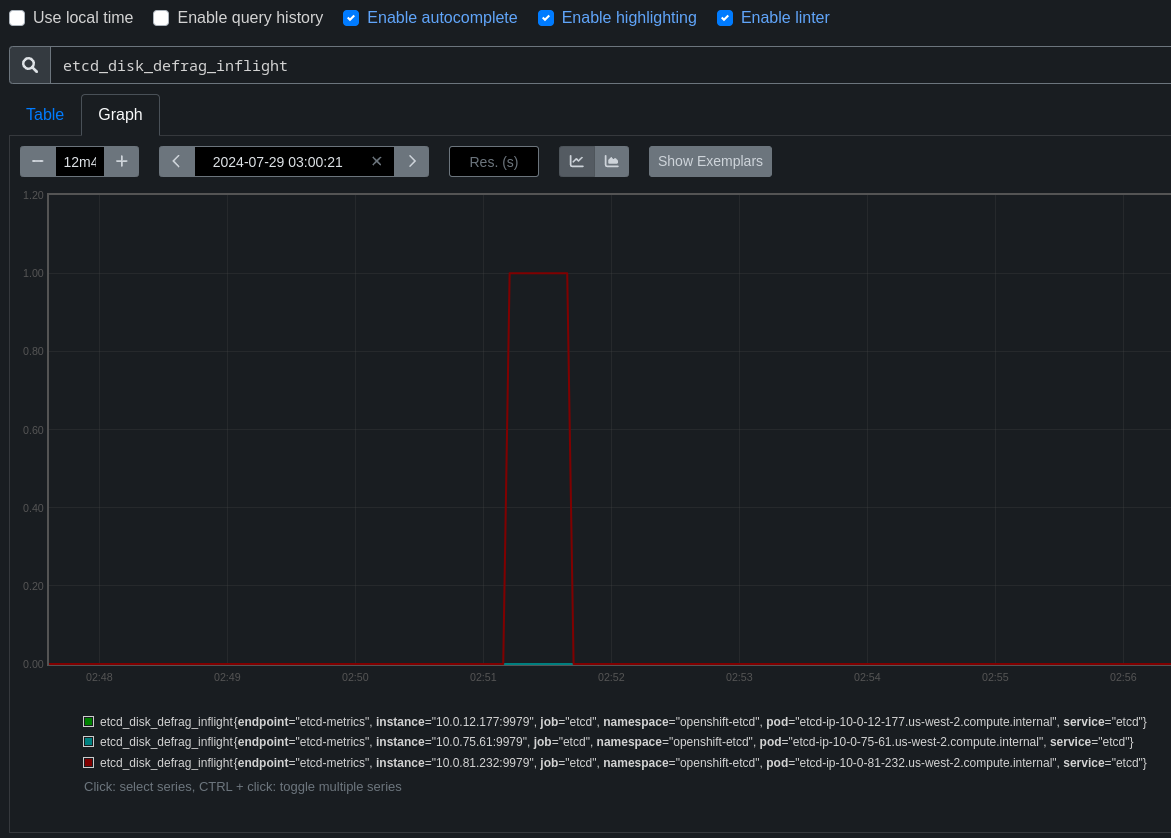
This bug is the result of scanning the job list lower on the dashboard and identifying patterns in the disruption.
For this bug, the specific pattern we're looking at is 5-7s of disruption when the kube-apiserver is rolling out a new revision.
Examples:
Open Debug Tools > Intervals or expand Spyglass charts to see the disruption and it's correlation to operator updates.
Error appears to always be net/http timeout awaiting response headers, and it affects both kube/openshift/oauth api, new and reused connections both.
Fairly easy to find more examples but we do have to watch out for one of the other two patterns. (I've seen several examples of disruption during node updates, and another bar earlier in the job runs, cause unknown, possible future bugs)