-
Bug
-
Resolution: Won't Do
-
 Undefined
Undefined
-
None
-
4.17, 4.18
-
Quality / Stability / Reliability
-
False
-
-
5
-
Important
-
No
-
None
-
Rejected
-
ETCD Sprint 259, ETCD Sprint 260, ETCD Sprint 261, ETCD Sprint 262, ETCD Sprint 263
-
5
-
None
-
None
-
None
-
None
-
None
-
None
-
None
deads reported in this thread that the static pod controller appears to sometimes deploy pods that do not show up in a reasonable timeframe, which occasionally triggers this test to fail (source job):
[sig-node] static pods should start after being created { static pod lifecycle failure - static pod: "etcd" in namespace: "openshift-etcd" for revision: 7 on node: "ci-op-h9zjcc96-51425-8gcc2-master-0" didn't show up, waited: 3m0s}
David suspects that this actually happens far more often than the test failures indicate, however this test should be a good resource to find affected runs.
Test details indicates this fails up to 10% of the time on some job variants. The most common compnent affected appears to be kube-controller-manager, but apiserver and etcd are both appearing at times. Use the test details link if looking for more job runs.
Slack thread has more details from both deads@redhat.com and tjungblu@redhat.com.
Suspicion is that fixing this could improve install times and reliability.
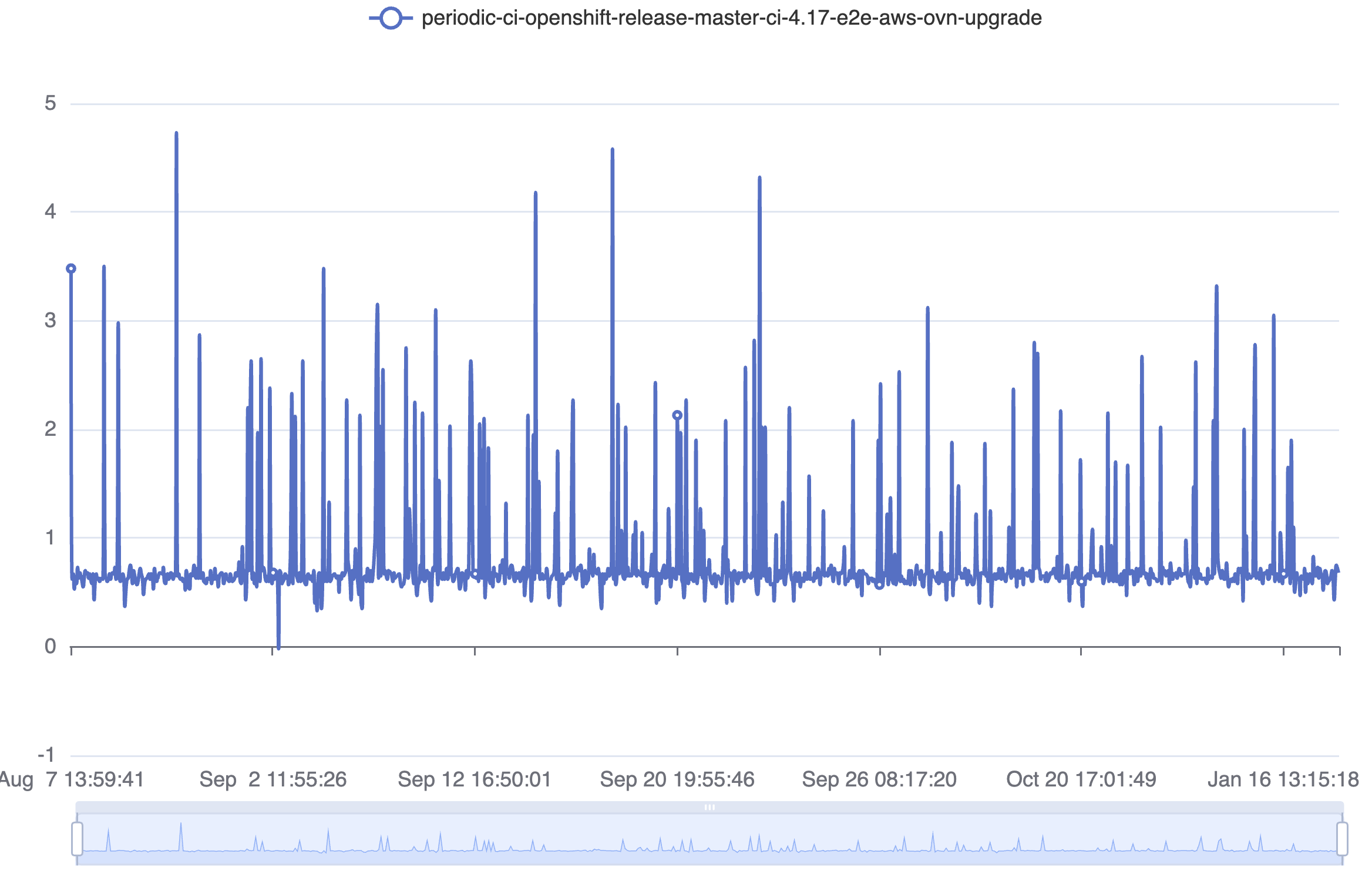
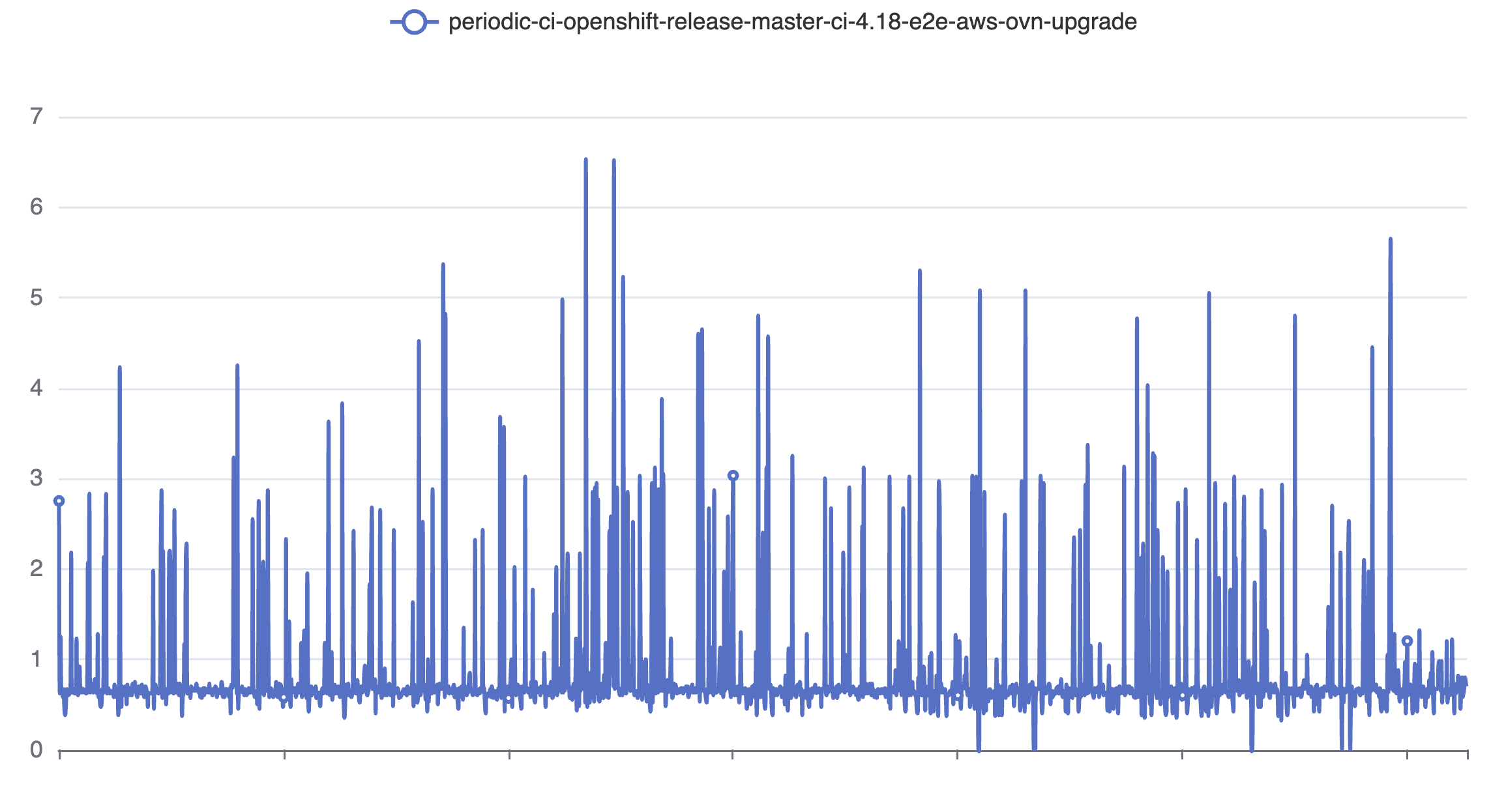
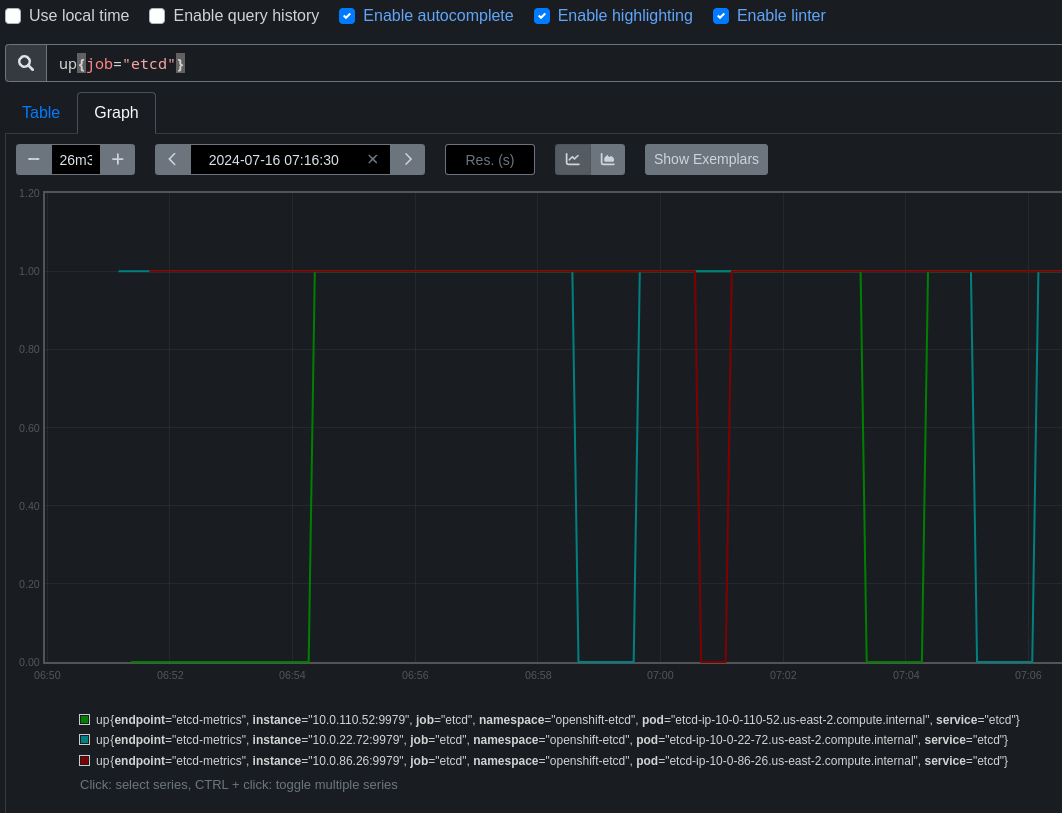

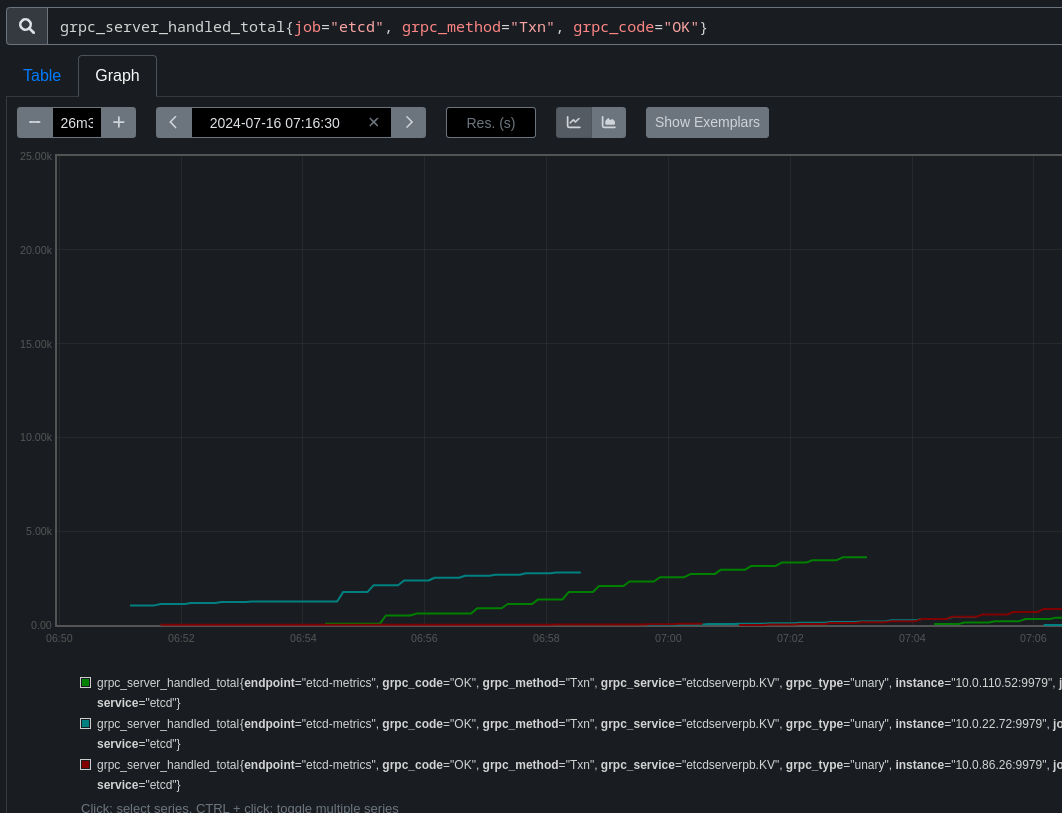


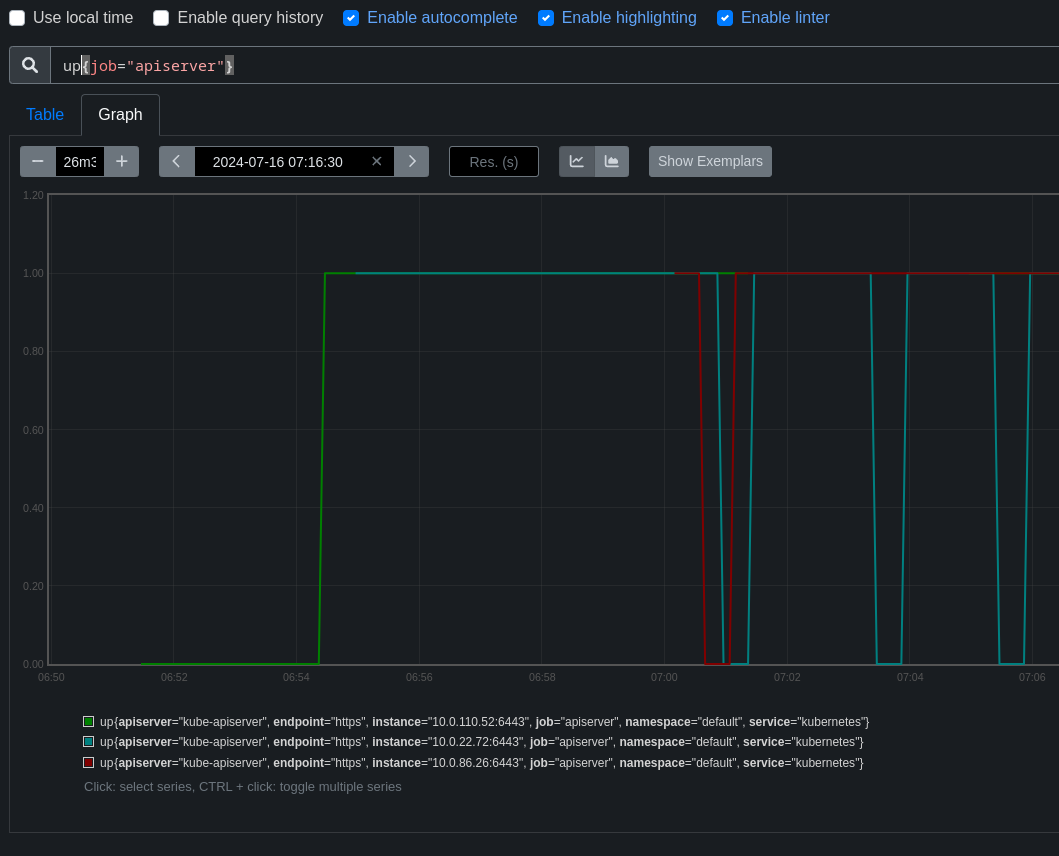
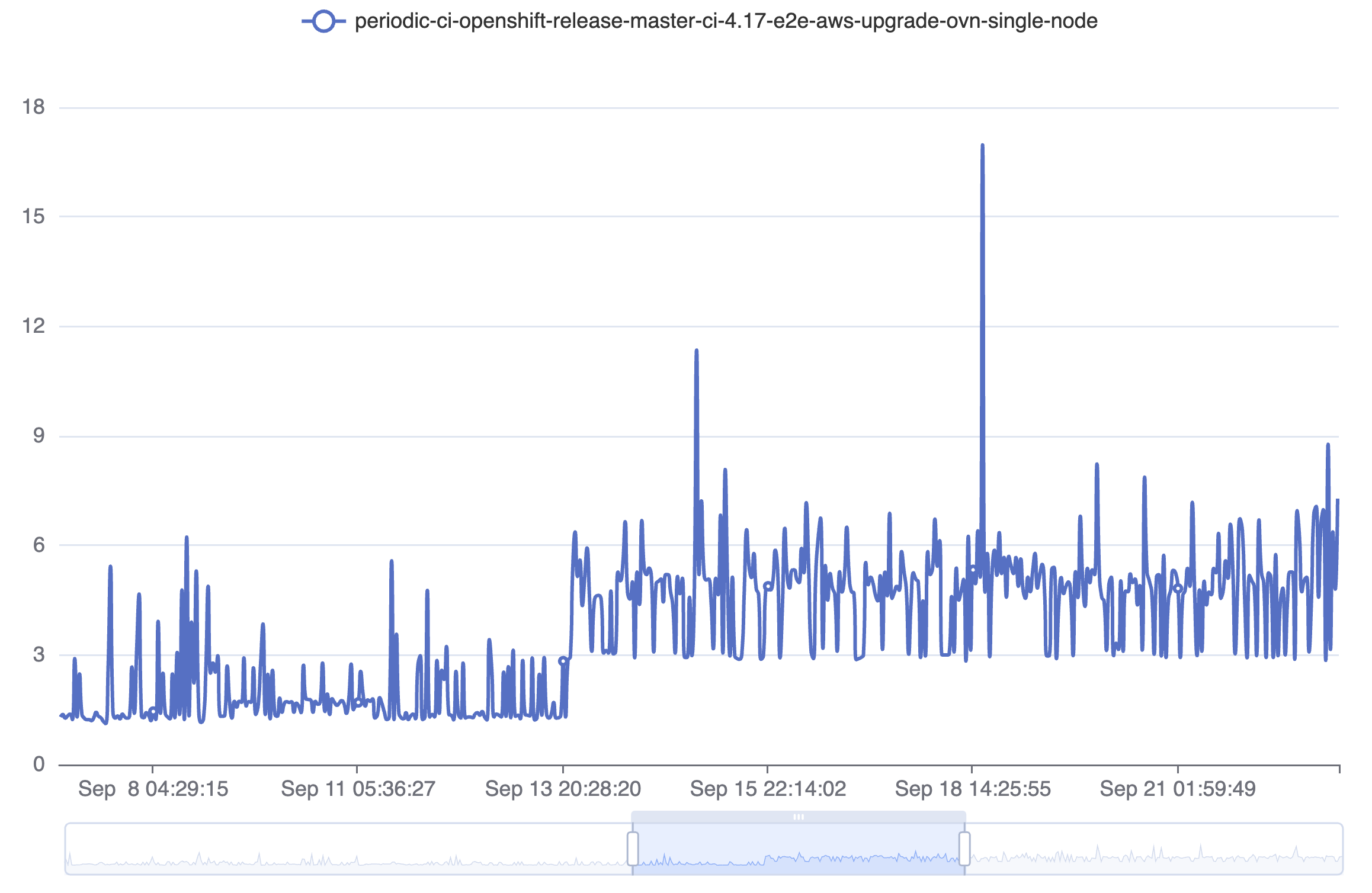
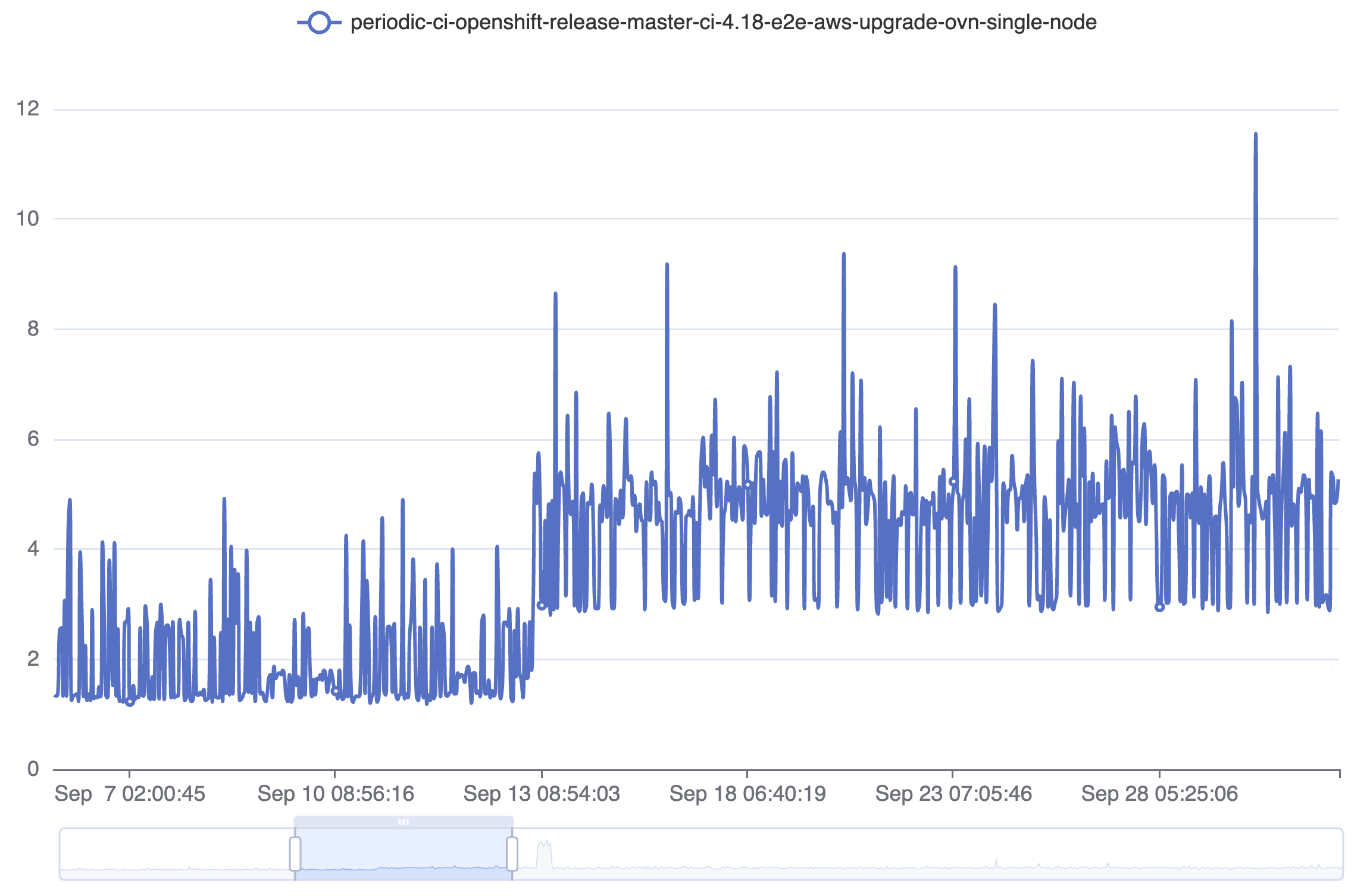
- duplicates
-
-

- Closed
-
- is related to
-
-
- Closed
-
-
-
- Closed
-

