-
Bug
-
Resolution: Duplicate
-
 Normal
Normal
-
None
-
4.17
-
None
-
Quality / Stability / Reliability
-
False
-
-
None
-
Moderate
-
No
-
None
-
None
-
None
-
MON Sprint 256, MON Sprint 257
-
2
-
In Progress
-
Release Note Not Required
-
NA
-
None
-
None
-
None
-
None
Description of problem
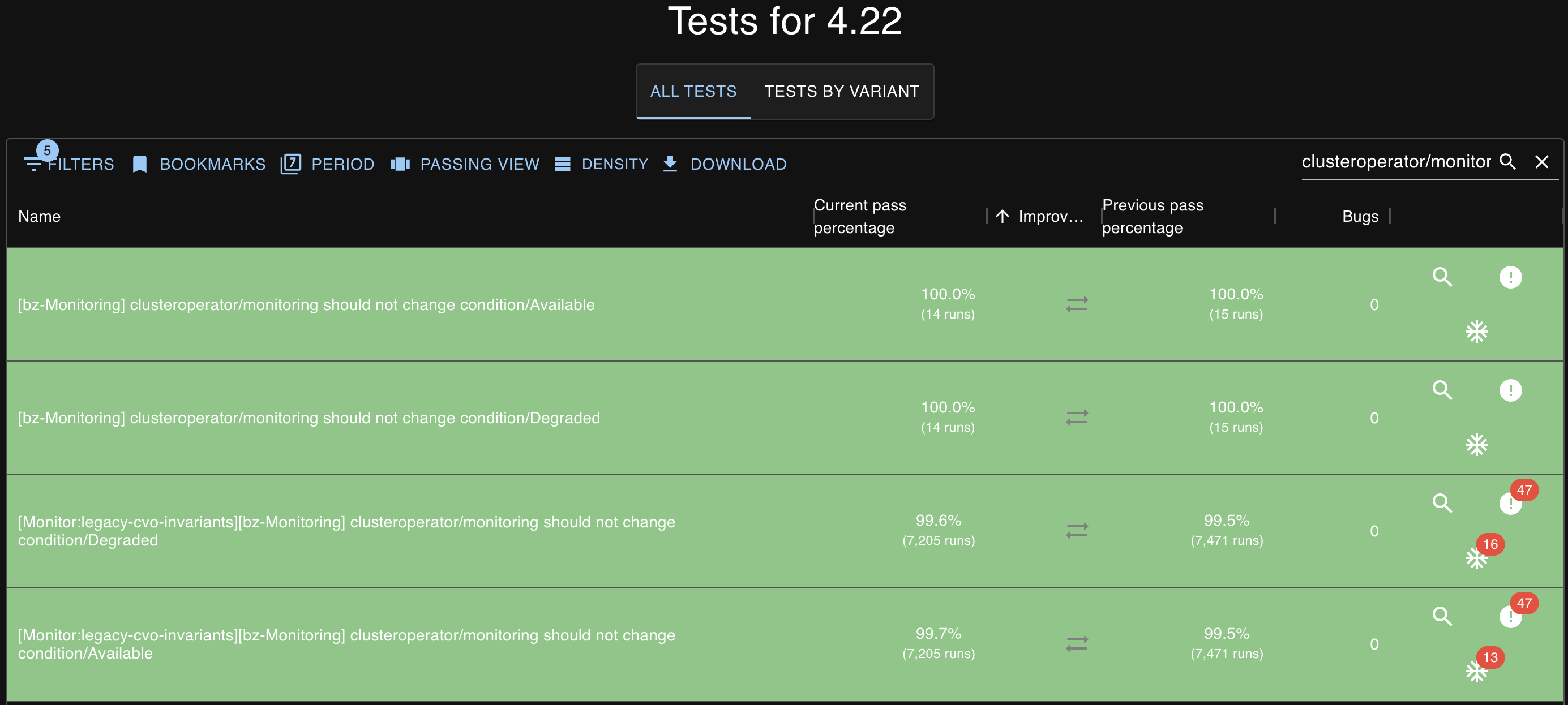
I bumped into monitoring going Available!=True in 4.17 CI, and saw it linking the shipped-in-4.15 OCPBUGS-23745 exception. I've cloned this bug to report the issues we're still seeing. All of the 4.17 hits over the past 96 hours have Available going Unknown on UpdatingPrometheusFailed and mentioning client rate limiter.
$ curl -s 'https://search.dptools.openshift.org/search?maxAge=96h&type=junit&context=0&name=periodic-.*4.17&search=clusteroperator/monitoring+condition/Available.*status/%5BUF%5D' | jq -r 'to_entries[].value | to_entries[].value[].context[]' Jun 18 16:55:17.636 - 2266s E clusteroperator/monitoring condition/Available reason/Unknown status/False Unknown (exception: We are not worried about Available=False or Degraded=True blips for stable-system tests yet.) Jun 17 12:17:22.197 W clusteroperator/monitoring condition/Available reason/UpdatingPrometheusFailed status/Unknown UpdatingPrometheus: client rate limiter Wait returned an error: context deadline exceeded (exception: https://issues.redhat.com/browse/OCPBUGS-23745) Jun 17 12:13:51.618 W clusteroperator/monitoring condition/Available reason/UpdatingPrometheusFailed status/Unknown UpdatingPrometheus: client rate limiter Wait returned an error: rate: Wait(n=1) would exceed context deadline (exception: https://issues.redhat.com/browse/OCPBUGS-23745) Jun 17 12:20:39.844 W clusteroperator/monitoring condition/Available reason/UpdatingPrometheusFailed status/Unknown UpdatingPrometheus: client rate limiter Wait returned an error: context deadline exceeded (exception: https://issues.redhat.com/browse/OCPBUGS-23745) Jun 17 23:45:45.828 W clusteroperator/monitoring condition/Available reason/UpdatingPrometheusFailed status/Unknown UpdatingPrometheus: client rate limiter Wait returned an error: rate: Wait(n=1) would exceed context deadline (exception: https://issues.redhat.com/browse/OCPBUGS-23745) Jun 18 18:41:31.933 W clusteroperator/monitoring condition/Available reason/UpdatingPrometheusFailed status/Unknown UpdatingPrometheus: client rate limiter Wait returned an error: context deadline exceeded (exception: https://issues.redhat.com/browse/OCPBUGS-23745) Jun 20 02:56:45.777 W clusteroperator/monitoring condition/Available reason/UpdatingPrometheusFailed status/Unknown UpdatingPrometheus: client rate limiter Wait returned an error: rate: Wait(n=1) would exceed context deadline (exception: https://issues.redhat.com/browse/OCPBUGS-23745)
Version-Release number of selected component
I'm only looking at dev/4.17, for any forward-looking improvements.
$ w3m -dump -cols 200 'https://search.dptools.openshift.org/?maxAge=96h&type=junit&search=clusteroperator/monitoring+should+not+change+condition/Available' | grep '^periodic-.*4[.]17.*failures match' | sort periodic-ci-openshift-multiarch-master-nightly-4.17-ocp-e2e-upgrade-aws-ovn-arm64 (all) - 25 runs, 20% failed, 20% of failures match = 4% impact periodic-ci-openshift-release-master-ci-4.17-upgrade-from-stable-4.16-e2e-gcp-ovn-rt-upgrade (all) - 120 runs, 28% failed, 18% of failures match = 5% impact
How reproducible
5% impact in periodic-ci-openshift-release-master-ci-4.17-upgrade-from-stable-4.16-e2e-gcp-ovn-rt-upgrade is the current largest impact percentage on the most-frequently-run matching job.
Steps to Reproduce
Run periodic-ci-openshift-release-master-ci-4.17-upgrade-from-stable-4.16-e2e-gcp-ovn-rt-upgrade or another job with a combination of high-ish impact percentage and high run counts, watching the monitoring ClusterOperator's Available condition.
Actual results
Blips of Available=Unknown that resolve more quickly than a responding admin could be expected to show up.
Expected results
Only going Available!=True when it seems reasonable to summon an emergency admin response.
Additional context
The matching results from my CI Search query above are these runs:
$ curl -s 'https://search.dptools.openshift.org/search?maxAge=96h&type=junit&context=0&name=periodic-.*4.17&search=clusteroperator/monitoring+condition/Available.*status/%5BUF%5D' | jq -r 'keys[]' https://prow.ci.openshift.org/view/gs/test-platform-results/logs/periodic-ci-openshift-multiarch-master-nightly-4.17-ocp-e2e-upgrade-aws-ovn-arm64/1803081477055844352 https://prow.ci.openshift.org/view/gs/test-platform-results/logs/periodic-ci-openshift-release-master-ci-4.17-upgrade-from-stable-4.16-e2e-gcp-ovn-rt-upgrade/1802645325958090752 https://prow.ci.openshift.org/view/gs/test-platform-results/logs/periodic-ci-openshift-release-master-ci-4.17-upgrade-from-stable-4.16-e2e-gcp-ovn-rt-upgrade/1802645333503643648 https://prow.ci.openshift.org/view/gs/test-platform-results/logs/periodic-ci-openshift-release-master-ci-4.17-upgrade-from-stable-4.16-e2e-gcp-ovn-rt-upgrade/1802645338536808448 https://prow.ci.openshift.org/view/gs/test-platform-results/logs/periodic-ci-openshift-release-master-ci-4.17-upgrade-from-stable-4.16-e2e-gcp-ovn-rt-upgrade/1802819236817539072 https://prow.ci.openshift.org/view/gs/test-platform-results/logs/periodic-ci-openshift-release-master-ci-4.17-upgrade-from-stable-4.16-e2e-gcp-ovn-rt-upgrade/1803104183897821184 https://prow.ci.openshift.org/view/gs/test-platform-results/logs/periodic-ci-openshift-release-master-ci-4.17-upgrade-from-stable-4.16-e2e-gcp-ovn-rt-upgrade/1803592572216545280
- clones
-
-
- Closed
-
- relates to
-
OTA-362 CI: fail update suite if any ClusterOperator go Available=False
-

- Closed
-
-
-
- Closed
-
