-
Bug
-
Resolution: Cannot Reproduce
-
 Normal
Normal
-
None
-
4.14.z
-
None
-
Quality / Stability / Reliability
-
False
-
-
None
-
Moderate
-
No
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
Description of problem:
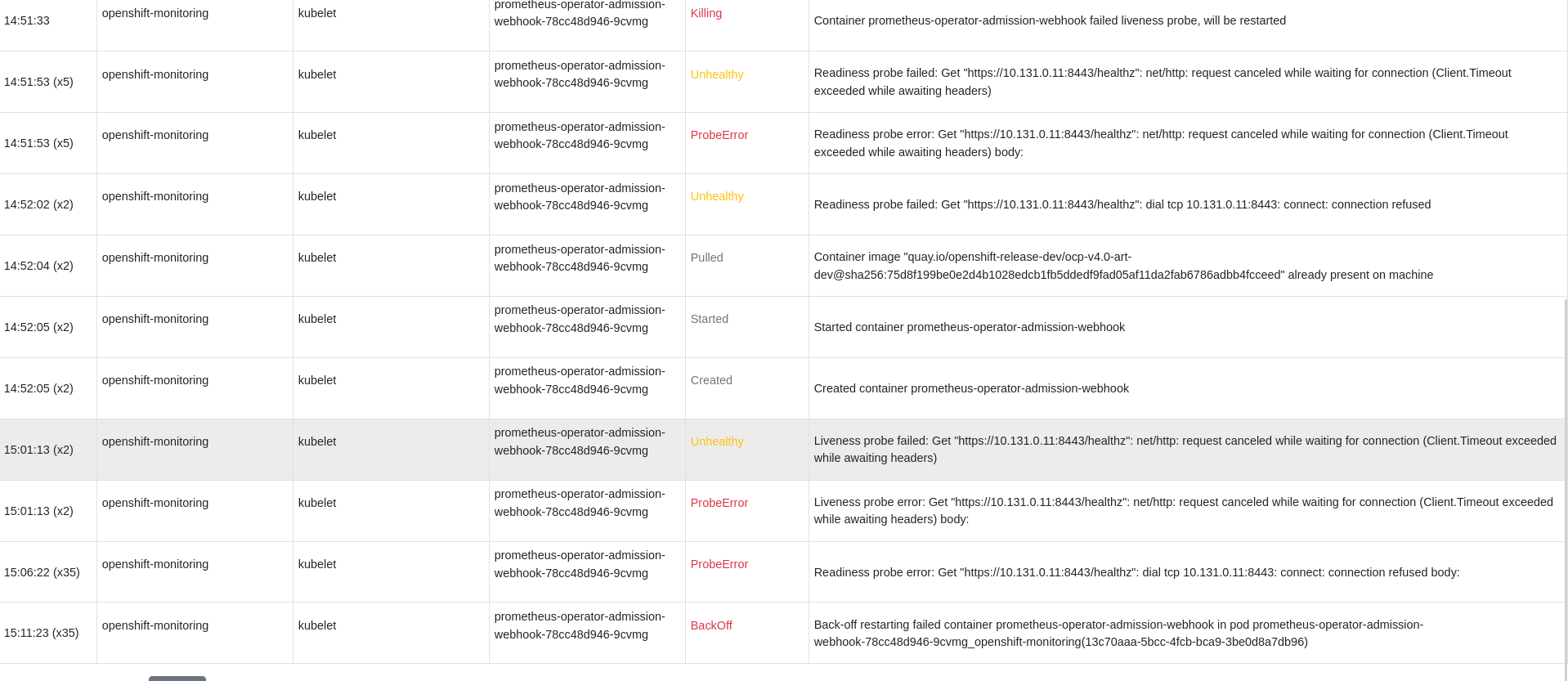
After running tests, one pod openshift-monitoring-admission-webhook is sometimes going to crashloopback state
2024-04-27 15:13:51.343 | openshift-monitoring alertmanager-main-0 6/6 Running 0 4h2m 2024-04-27 15:13:51.349 | openshift-monitoring alertmanager-main-1 6/6 Running 0 4h5m 2024-04-27 15:13:51.358 | openshift-monitoring cluster-monitoring-operator-7845c74bd6-fzlrv 1/1 Running 0 52m 2024-04-27 15:13:51.368 | openshift-monitoring kube-state-metrics-5f7985679d-kb7tm 3/3 Running 0 4h5m 2024-04-27 15:13:51.378 | openshift-monitoring monitoring-plugin-76bdcb5c7c-hcv66 1/1 Running 0 4h5m 2024-04-27 15:13:51.388 | openshift-monitoring monitoring-plugin-76bdcb5c7c-kvdfk 1/1 Running 0 4h2m 2024-04-27 15:13:51.397 | openshift-monitoring node-exporter-4tz5r 2/2 Running 0 47m 2024-04-27 15:13:51.408 | openshift-monitoring node-exporter-f9jjq 2/2 Running 8 8h 2024-04-27 15:13:51.416 | openshift-monitoring node-exporter-fm9kr 2/2 Running 4 8h 2024-04-27 15:13:51.426 | openshift-monitoring node-exporter-l42fw 2/2 Running 0 63m 2024-04-27 15:13:51.435 | openshift-monitoring node-exporter-n6g8d 2/2 Running 0 29m 2024-04-27 15:13:51.445 | openshift-monitoring node-exporter-s8htg 2/2 Running 4 8h 2024-04-27 15:13:51.450 | openshift-monitoring openshift-state-metrics-84fbf57869-8gkkr 3/3 Running 0 4h5m 2024-04-27 15:13:51.460 | openshift-monitoring prometheus-adapter-64946bc45-4fz7k 1/1 Running 5 (2m55s ago) 4h5m 2024-04-27 15:13:51.471 | openshift-monitoring prometheus-adapter-64946bc45-cnd8n 1/1 Running 1 (11m ago) 4h2m 2024-04-27 15:13:51.481 | openshift-monitoring prometheus-k8s-0 6/6 Running 1 (10m ago) 4h2m 2024-04-27 15:13:51.490 | openshift-monitoring prometheus-k8s-1 6/6 Running 2 (2m48s ago) 4h5m 2024-04-27 15:13:51.500 | openshift-monitoring prometheus-operator-576997d49d-vqdgn 2/2 Running 0 15m 2024-04-27 15:13:51.510 | openshift-monitoring prometheus-operator-admission-webhook-78cc48d946-9cvmg 0/1 CrashLoopBackOff 7 (3m51s ago) 4h5m 2024-04-27 15:13:51.520 | openshift-monitoring prometheus-operator-admission-webhook-78cc48d946-chr99 1/1 Running 0 4h2m 2024-04-27 15:13:51.530 | openshift-monitoring telemeter-client-7bcb7d8497-8f958 3/3 Running 0 4h5m 2024-04-27 15:13:51.539 | openshift-monitoring thanos-querier-fbc65cc47-bjdfd 6/6 Running 4 (3m18s ago) 4h5m 2024-04-27 15:13:51.544 | openshift-monitoring thanos-querier-fbc65cc47-jczb8 6/6 Running 0 4h2m
Version-Release number of selected component (if applicable):
osp_puddle: RHOS-17.1-RHEL-9-20240123.n.1 ocp_puddle: 4.14.23
How reproducible:
We observed on openshift on openstack downstream CI from time to time (3/10 runs approx)
Steps to Reproduce:
Run all testing and check the status of the pods.
Additional info: must-gather linked on private comment