-
Bug
-
Resolution: Cannot Reproduce
-
 Major
Major
-
None
-
4.15, 4.16
-
Quality / Stability / Reliability
-
False
-
-
None
-
None
-
No
-
None
-
None
-
Approved
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
We are observing high API request latency in 4.15 compared to 4.14 in our Perf & Scale CI runs on 120 node self-managed AWS OCP environments while testing our standard workload.
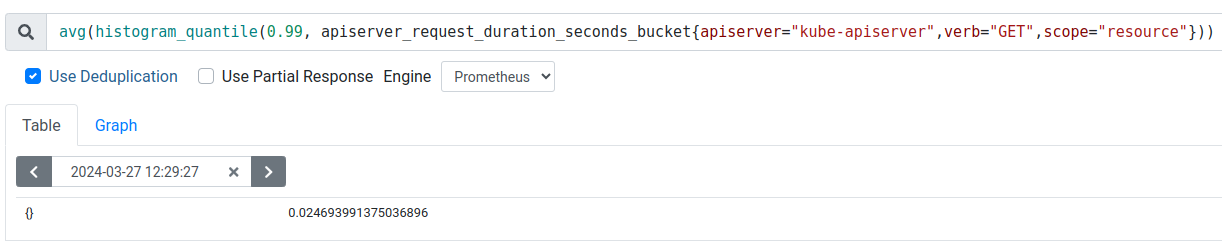
Avg Resource scoped GET API P99 latency is around 21 ms in 4.14 vs 33 ms in 4.15 (50% increase in latency).
Avg Namespace scoped LIST API P99 latency is around 21 ms in 4.14 vs 29 ms in 4.15 (40% increase in latency).
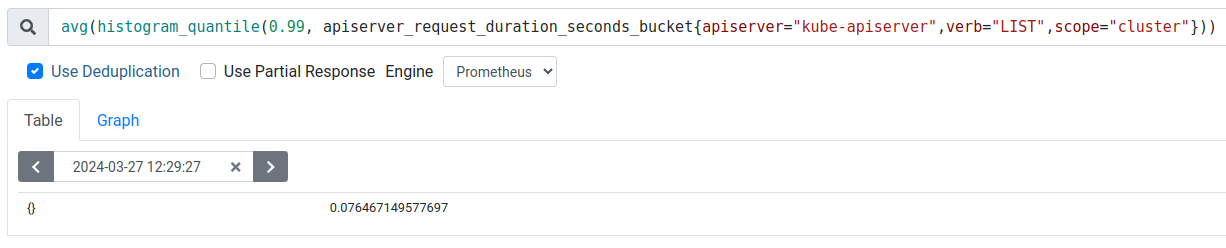
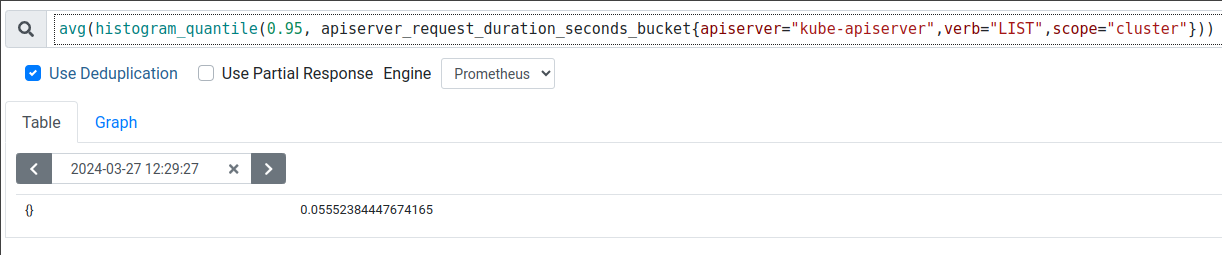
Avg Cluster scoped LIST API P99 latency is between 70-80 ms in 4.14 vs 97-110 ms in 4.15 (37% increase in latency).
| OCP Version | Avg Resource scoped GET API P99 Latency (ms) | Avg Namespace scoped LIST API P99 Latency (ms) | Avg Cluster scoped LIST API P99 Latency (ms) |
|---|---|---|---|
| 4.14.0-0.nightly-2023-12-22-053212 | 21.1 | 19.9 | 77.9 |
| 4.14.0-0.nightly-2023-12-15-100018 | 21.3 | 20.8 | 71.6 |
| 4.14.0-0.nightly-2024-01-05-015957 | 23.7 | 22.7 | 82.5 |
| 4.14.0-0.nightly-2023-12-08-072853 | 22.4 | 22.9 | 68.6 |
| 4.14.0-0.nightly-2023-12-01-050301 | 21.4 | 20.3 | 85.4 |
| 4.15.0-0.nightly-2024-01-10-043410 | 33.2 | 32.6 | 104 |
| 4.15.0-0.nightly-2024-01-03-015912 | 37.3 | 33.4 | 97.7 |
| 4.15.0-0.nightly-2024-01-03-140457 | 31.5 | 27.8 | 126 |
| 4.15.0-0.nightly-2023-12-25-100326 | 34.1 | 29.7 | 97.8 |
| 4.15.0-0.nightly-2023-12-04-223539 | 34.6 | 28.2 | 106 |
How reproducible: consistently
Steps to Reproduce:
- Deploy 4.14 and 4.15 self-managed 120 (or 249) nodes cluster
- Run Perf&Scale workload cluster-density-v2
git clone https://github.com/cloud-bulldozer/e2e-benchmarking pushd e2e-benchmarking/workloads/kube-burner-ocp-wrapper ./kube-burner-ocp cluster-density-v2 --log-level=info --qps=20 --burst=20 --gc=true --uuid <uuid> --churn-duration=20m --timeout=6h --gc-metrics=true --iterations=1080 --churn=true
We specify 1080 iterations in 120 node environment.
Each iteration creates the following objects:
- 1 imagestream
- 1 build
- 5 deployments with pod 2 replicas (sleep) mounting 4 secrets, 4 configmaps and 1 downwardAPI volume each
- 5 services, each one pointing to the TCP/8080 and TCP/8443 ports of one of the previous deployments
- 1 route pointing to the to first service
- 10 secrets containing 2048 character random string
- 10 configMaps containing a 2048 character random string
Actual results:
We see 30% to 50% increase in kube-apiserver API request latency in 4.15 120 node env compared to 4.14 in our Perf & Scale CI runs.