-
Bug
-
Resolution: Done
-
 Critical
Critical
-
4.12.0
-
Quality / Stability / Reliability
-
False
-
-
None
-
Critical
-
None
-
None
-
Approved
-
CLOUD Sprint 226, CLOUD Sprint 227
-
2
-
None
-
None
-
N/A - This was introduced by the K/K rebase, and fixed before release
-
None
-
None
-
None
-
None
Description of problem:
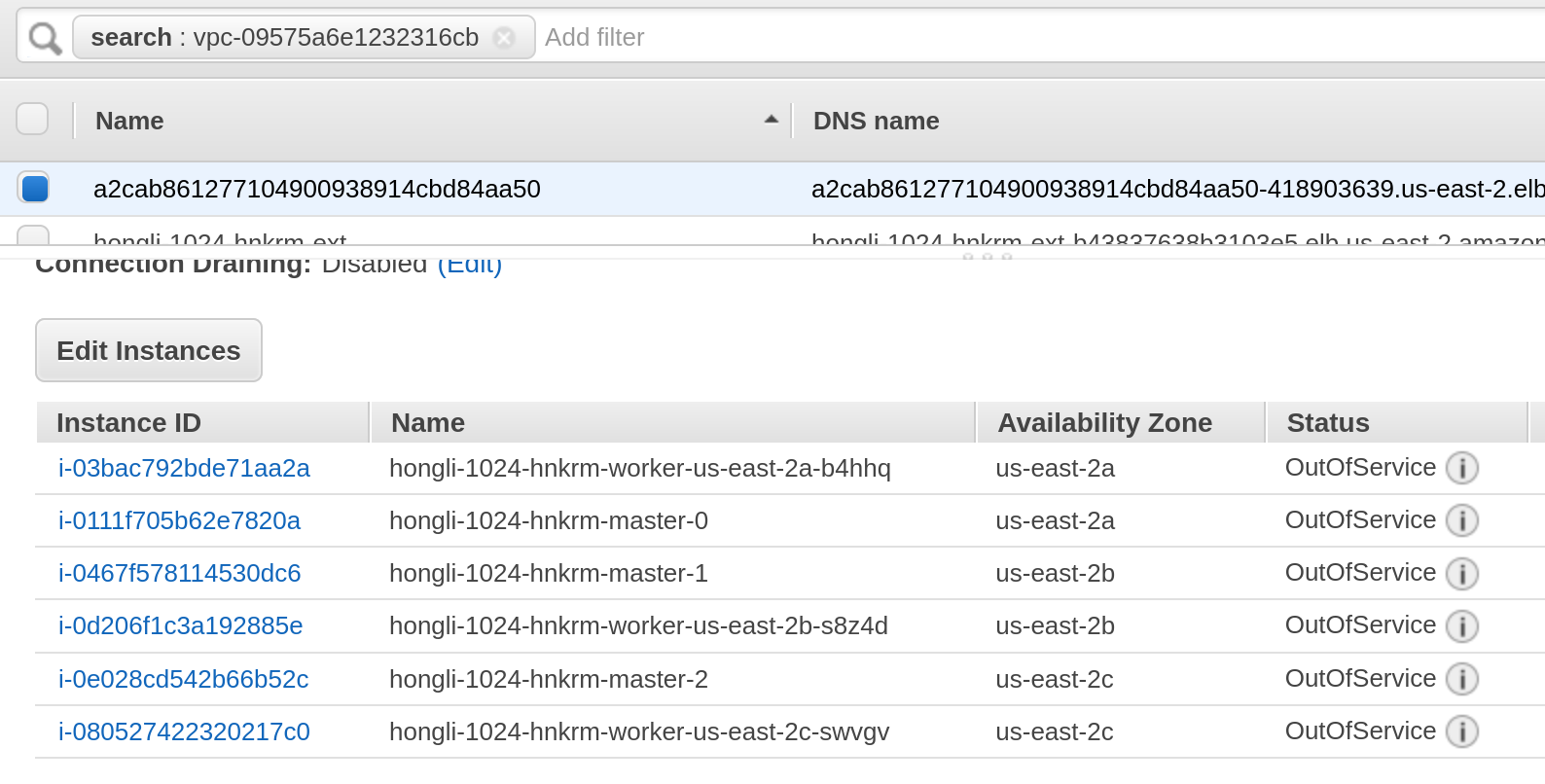
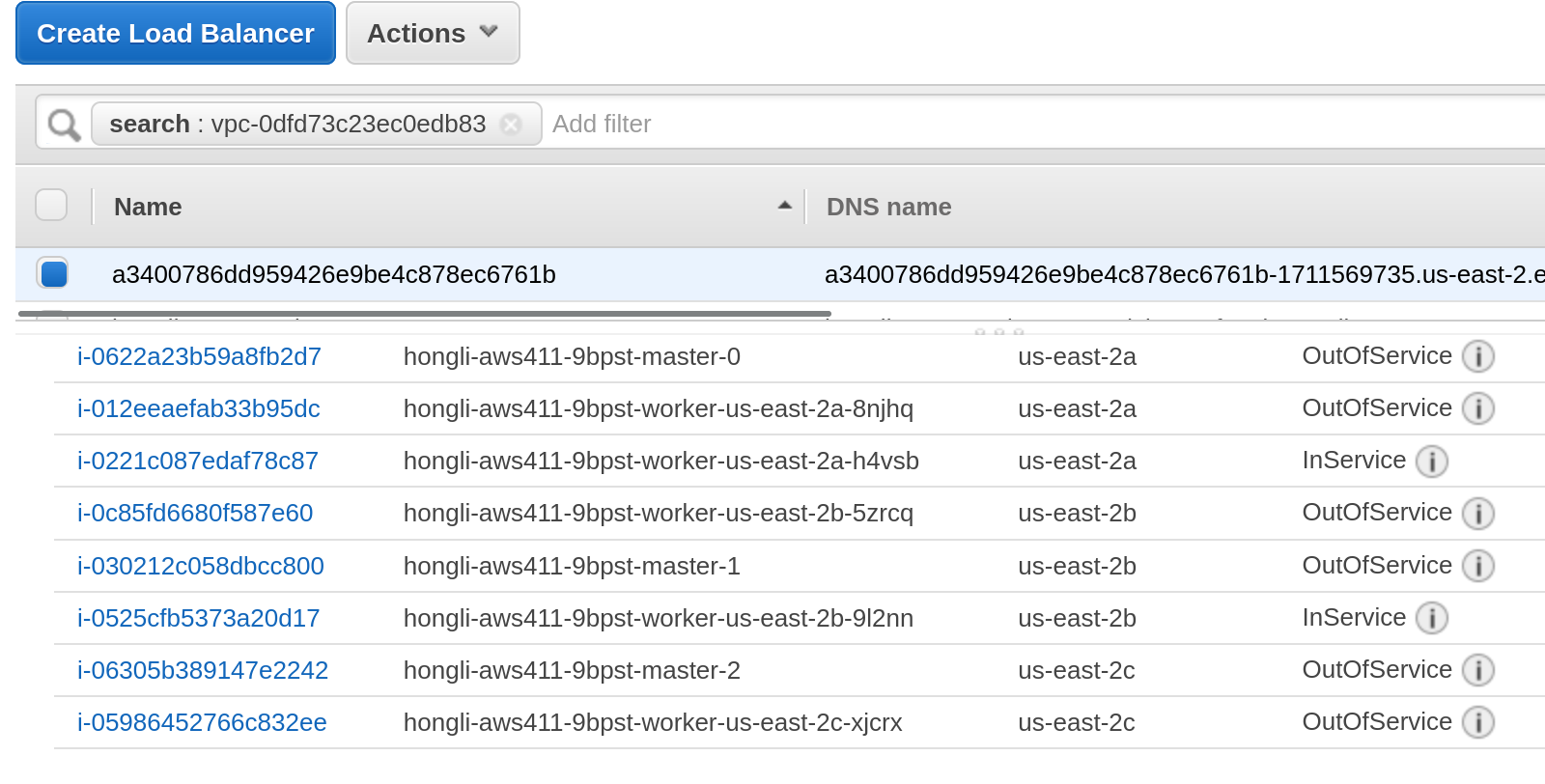
scale up more worker nodes but they are not added to the Load Balancer instances (backend pool), if moving the router pod to the new worker nodes then co/ingress becomes degraded
Version-Release number of selected component (if applicable):
4.12.0-0.nightly-2022-10-23-204408
How reproducible:
100%
Steps to Reproduce:
1. ensure the fresh install cluster works well. 2. scale up worker nodes. $ oc -n openshift-machine-api get machineset NAME DESIRED CURRENT READY AVAILABLE AGE hongli-1024-hnkrm-worker-us-east-2a 1 1 1 1 5h21m hongli-1024-hnkrm-worker-us-east-2b 1 1 1 1 5h21m hongli-1024-hnkrm-worker-us-east-2c 1 1 1 1 5h21m $ oc -n openshift-machine-api scale machineset hongli-1024-hnkrm-worker-us-east-2a --replicas=2 machineset.machine.openshift.io/hongli-1024-hnkrm-worker-us-east-2a scaled $ oc -n openshift-machine-api scale machineset hongli-1024-hnkrm-worker-us-east-2b --replicas=2 machineset.machine.openshift.io/hongli-1024-hnkrm-worker-us-east-2b scaled (about 5 minutes later) $ oc -n openshift-machine-api get machineset NAME DESIRED CURRENT READY AVAILABLE AGE hongli-1024-hnkrm-worker-us-east-2a 2 2 2 2 5h29m hongli-1024-hnkrm-worker-us-east-2b 2 2 2 2 5h29m hongli-1024-hnkrm-worker-us-east-2c 1 1 1 1 5h29m 3. delete router pods and to make new ones running on new workers $ oc get node NAME STATUS ROLES AGE VERSION ip-10-0-128-45.us-east-2.compute.internal Ready worker 71m v1.25.2+4bd0702 ip-10-0-131-192.us-east-2.compute.internal Ready control-plane,master 6h35m v1.25.2+4bd0702 ip-10-0-139-51.us-east-2.compute.internal Ready worker 6h29m v1.25.2+4bd0702 ip-10-0-162-228.us-east-2.compute.internal Ready worker 71m v1.25.2+4bd0702 ip-10-0-172-216.us-east-2.compute.internal Ready control-plane,master 6h35m v1.25.2+4bd0702 ip-10-0-190-82.us-east-2.compute.internal Ready worker 6h25m v1.25.2+4bd0702 ip-10-0-196-26.us-east-2.compute.internal Ready control-plane,master 6h35m v1.25.2+4bd0702 ip-10-0-199-158.us-east-2.compute.internal Ready worker 6h28m v1.25.2+4bd0702 $ oc -n openshift-ingress get pod -owide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES router-default-86444dcd84-cm96l 1/1 Running 0 65m 10.130.2.7 ip-10-0-128-45.us-east-2.compute.internal <none> <none> router-default-86444dcd84-vpnjz 1/1 Running 0 65m 10.131.2.7 ip-10-0-162-228.us-east-2.compute.internal <none> <none>
Actual results:
$ oc get co ingress console authentication NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE ingress 4.12.0-0.nightly-2022-10-23-204408 True False True 66m The "default" ingress controller reports Degraded=True: DegradedConditions: One or more other status conditions indicate a degraded state: CanaryChecksSucceeding=False (CanaryChecksRepetitiveFailures: Canary route checks for the default ingress controller are failing) console 4.12.0-0.nightly-2022-10-23-204408 False False False 66m RouteHealthAvailable: failed to GET route (https://console-openshift-console.apps.hongli-1024.qe.devcluster.openshift.com): Get "https://console-openshift-console.apps.hongli-1024.qe.devcluster.openshift.com": EOF authentication 4.12.0-0.nightly-2022-10-23-204408 False False True 66m OAuthServerRouteEndpointAccessibleControllerAvailable: Get "https://oauth-openshift.apps.hongli-1024.qe.devcluster.openshift.com/healthz": EOF checked the Load Balancer on AWS console and found that new created nodes are not added to load balancer. see the snapshot attached.
Expected results:
the LB should added new created instances automatically and ingress should work with new workers.
Additional info:
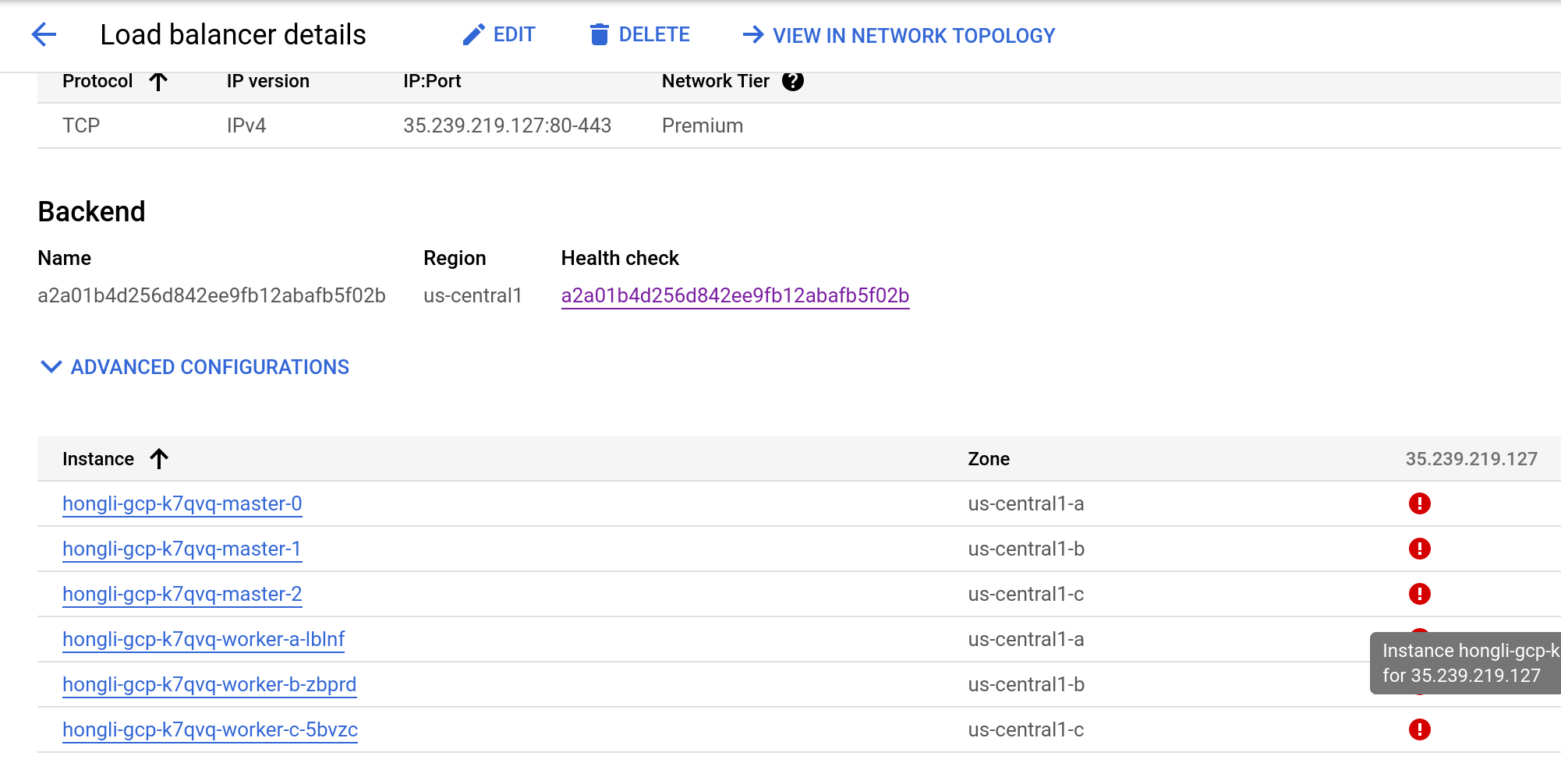
1. this is also reproducible with common user created LoadBalancer service. 2. if the LB service is created after adding the new nodes then it works well, we can see that all nodes are added to LB on AWS console.
- relates to
-
-

- Closed
-
- links to
