-
Bug
-
Resolution: Duplicate
-
 Undefined
Undefined
-
None
-
4.15
-
None
-
Quality / Stability / Reliability
-
False
-
-
None
-
Moderate
-
No
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
Seen in a 4.15 tech-preview serial CI run:
: [sig-arch] events should not repeat pathologically for ns/openshift-cluster-storage-operator 0s
{ 1 events happened too frequently
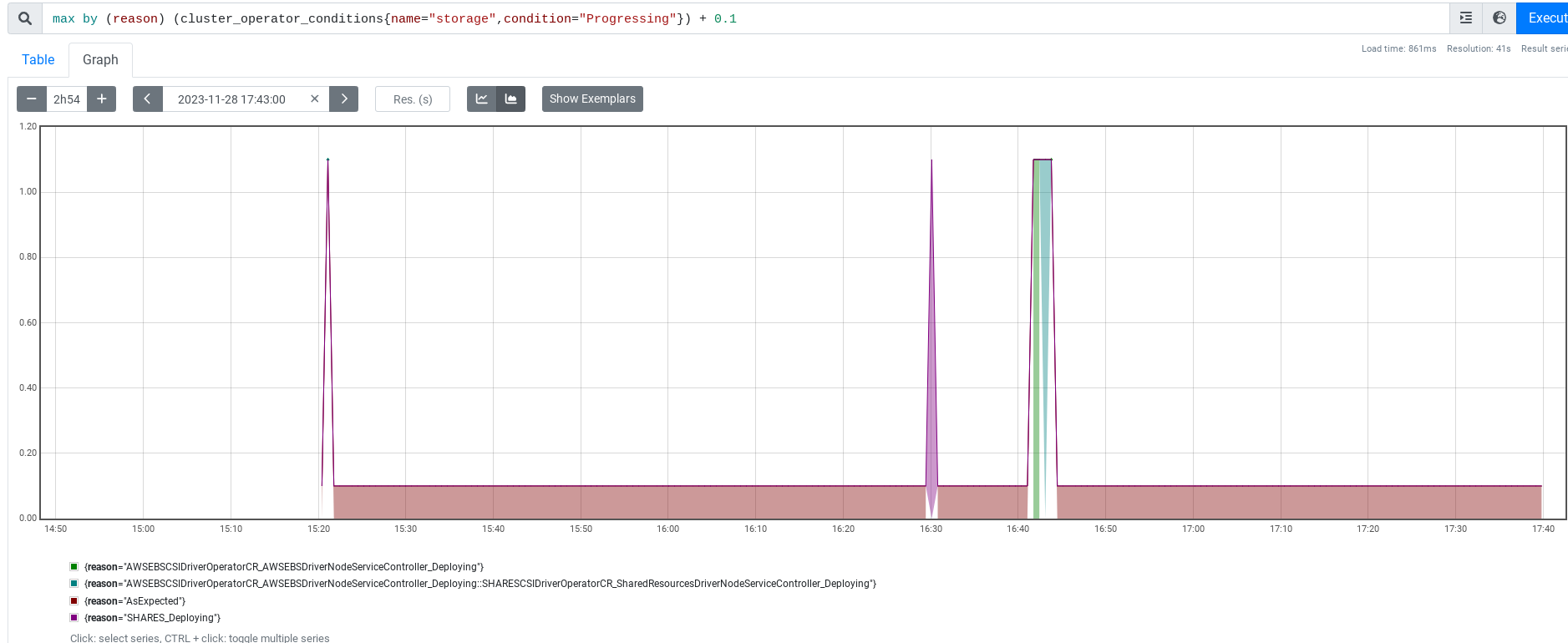
event happened 22 times, something is wrong: namespace/openshift-cluster-storage-operator deployment/cluster-storage-operator hmsg/cfc7e5cdbe - reason/OperatorStatusChanged Status for clusteroperator/storage changed: Progressing changed from True to False ("AWSEBSCSIDriverOperatorCRProgressing: All is well\nSHARESCSIDriverOperatorCRProgressing: All is well") From: 17:20:04Z To: 17:20:05Z result=reject }
Seems pretty common:
$ w3m -dump -cols 200 'https://search.ci.openshift.org/?search=SHARESCSIDriverOperatorCRProgressing&maxAge=24h&type=junit&name=periodic' | grep 'failures match' periodic-ci-openshift-release-master-ci-4.15-e2e-aws-sdn-techpreview-serial (all) - 4 runs, 100% failed, 100% of failures match = 100% impact periodic-ci-openshift-release-master-nightly-4.15-e2e-vsphere-ovn-techpreview-serial (all) - 4 runs, 75% failed, 100% of failures match = 75% impact periodic-ci-openshift-release-master-ci-4.15-e2e-azure-sdn-techpreview-serial (all) - 4 runs, 75% failed, 33% of failures match = 25% impact periodic-ci-openshift-release-master-ci-4.15-e2e-gcp-sdn-techpreview-serial (all) - 4 runs, 50% failed, 50% of failures match = 25% impact
Looking at PromeCIeus for the run I dug into, the reason flipping seems to be between AWSEBSCSIDriverOperatorCR_AWSEBSDriverNodeServiceController_Deploying and AWSEBSCSIDriverOperatorCR_AWSEBSDriverNodeServiceController_Deploying::SHARESCSIDriverOperatorCR_SharedResourcesDriverNodeServiceController_Deploying. Possibly the SHARESCSIDriverOperatorCR_SharedResourcesDriverNodeServiceController_Deploying side needs some inertia to avoid coming in and out?
Alternatively, if the reason churn seems appropriate, maybe the origin test suite can be taught that this churn is expected, and not pathological?
- duplicates
-
-

- Closed
-