-
Bug
-
Resolution: Done-Errata
-
 Undefined
Undefined
-
4.14.0
-
Quality / Stability / Reliability
-
False
-
-
None
-
None
-
No
-
None
-
Rejected
-
None
-
None
-
Release Note Not Required
-
N/A
-
None
-
None
-
None
-
None
This is a clone of issue OCPBUGS-14010. The following is the description of the original issue:
—
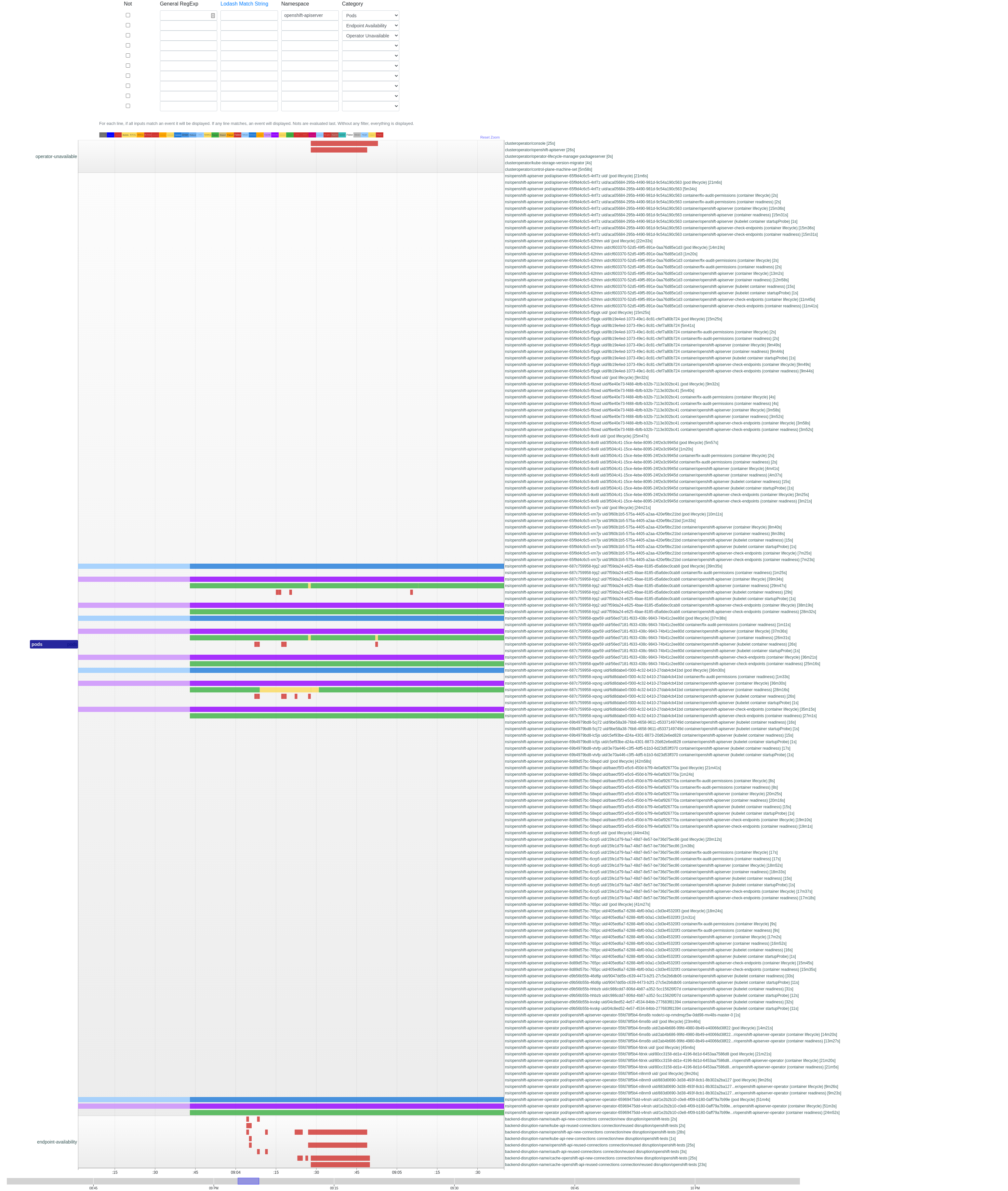
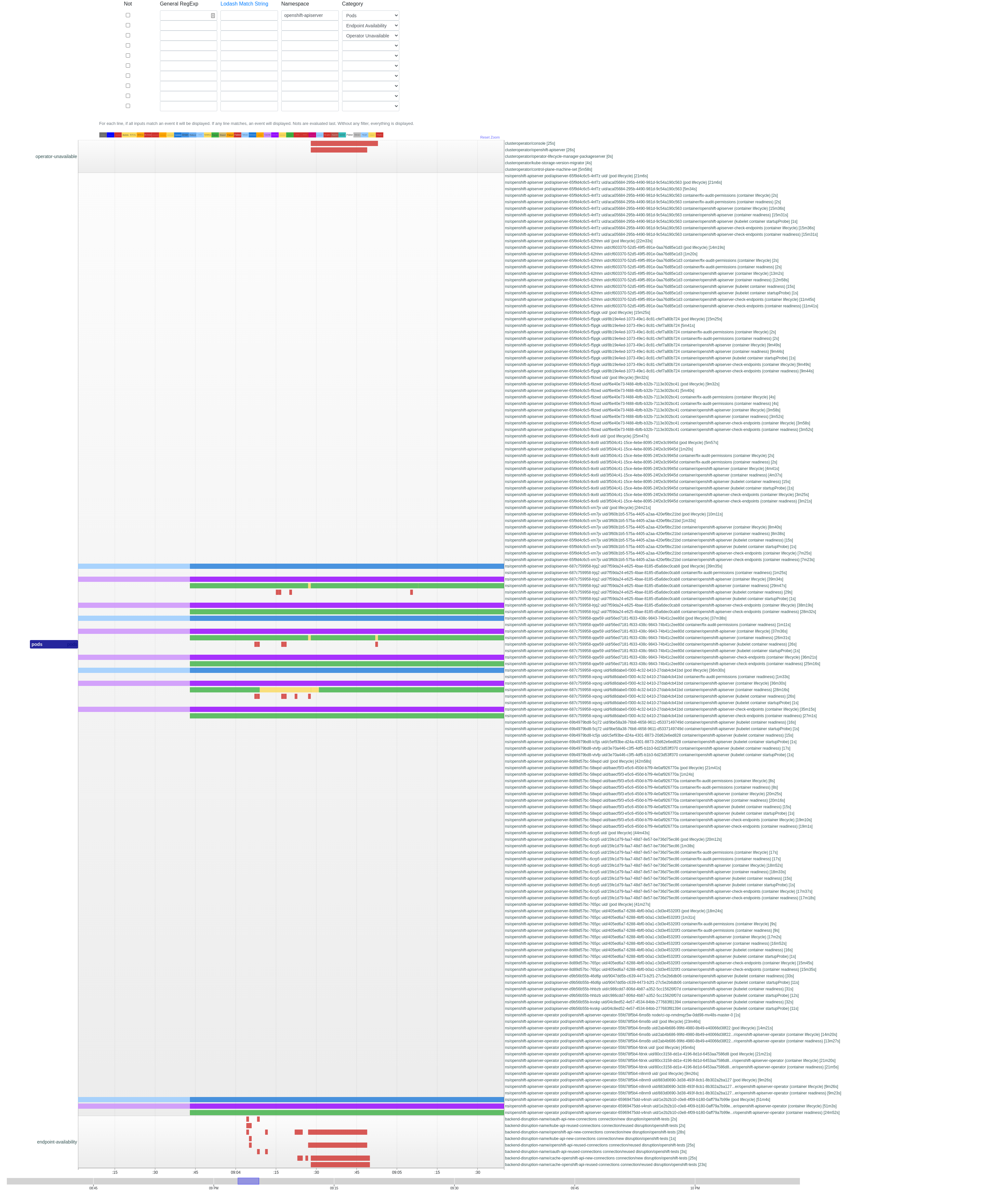
Extended api-server disruption periods during upgrades on Azure, detected by TRT analysis, led to the finding that non-fatal etcd delays were causing an api-server 503s.
https://github.com/openshift/cluster-openshift-apiserver-operator/blob/00f7e4cc95063ba5aba1992568088d924cfbf516/bindata/v3.11.0/openshift-apiserver/deploy.yaml#L137 shows the current readiness check permits only one failure after 1 second. Suggesting we backport OCPBUGS-14010 to make this 10 seconds and more forgiving of temporary etcd issues.
This prowjob shows the behavior:
- blocks
-
-
- Closed
-
- clones
-
-
- Closed
-
- is blocked by
-
-
- Closed
-
- is cloned by
-
-
- Closed
-
- links to
-
 RHBA-2023:6846
OpenShift Container Platform 4.13.z bug fix update
RHBA-2023:6846
OpenShift Container Platform 4.13.z bug fix update