-
Bug
-
Resolution: Done
-
 Normal
Normal
-
None
-
4.10
-
Quality / Stability / Reliability
-
False
-
-
None
-
Important
-
None
-
None
-
None
-
Rejected
-
CLOUD Sprint 227
-
1
-
None
-
None
-
None
-
None
-
None
-
None
-
None
Description of problem:
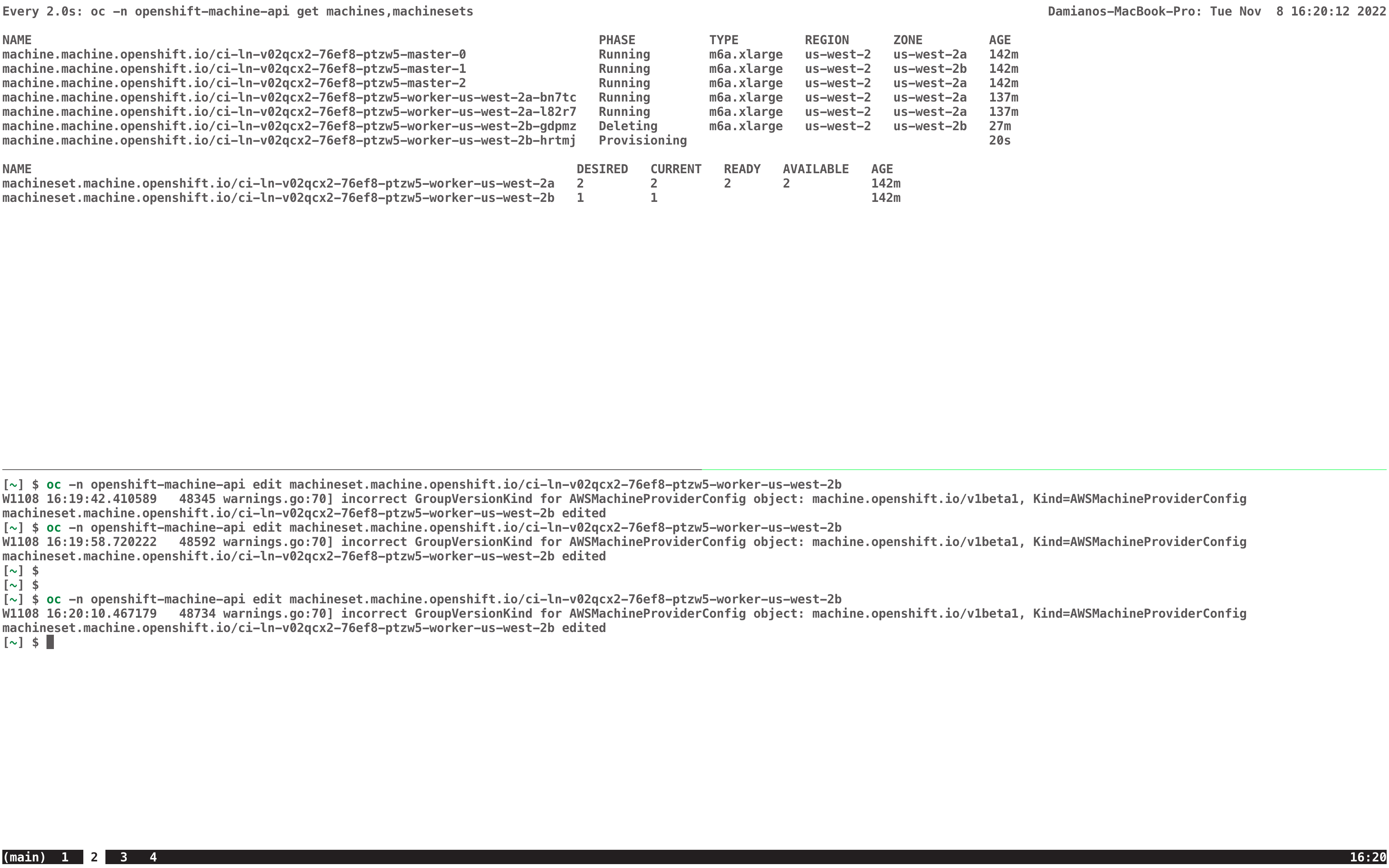
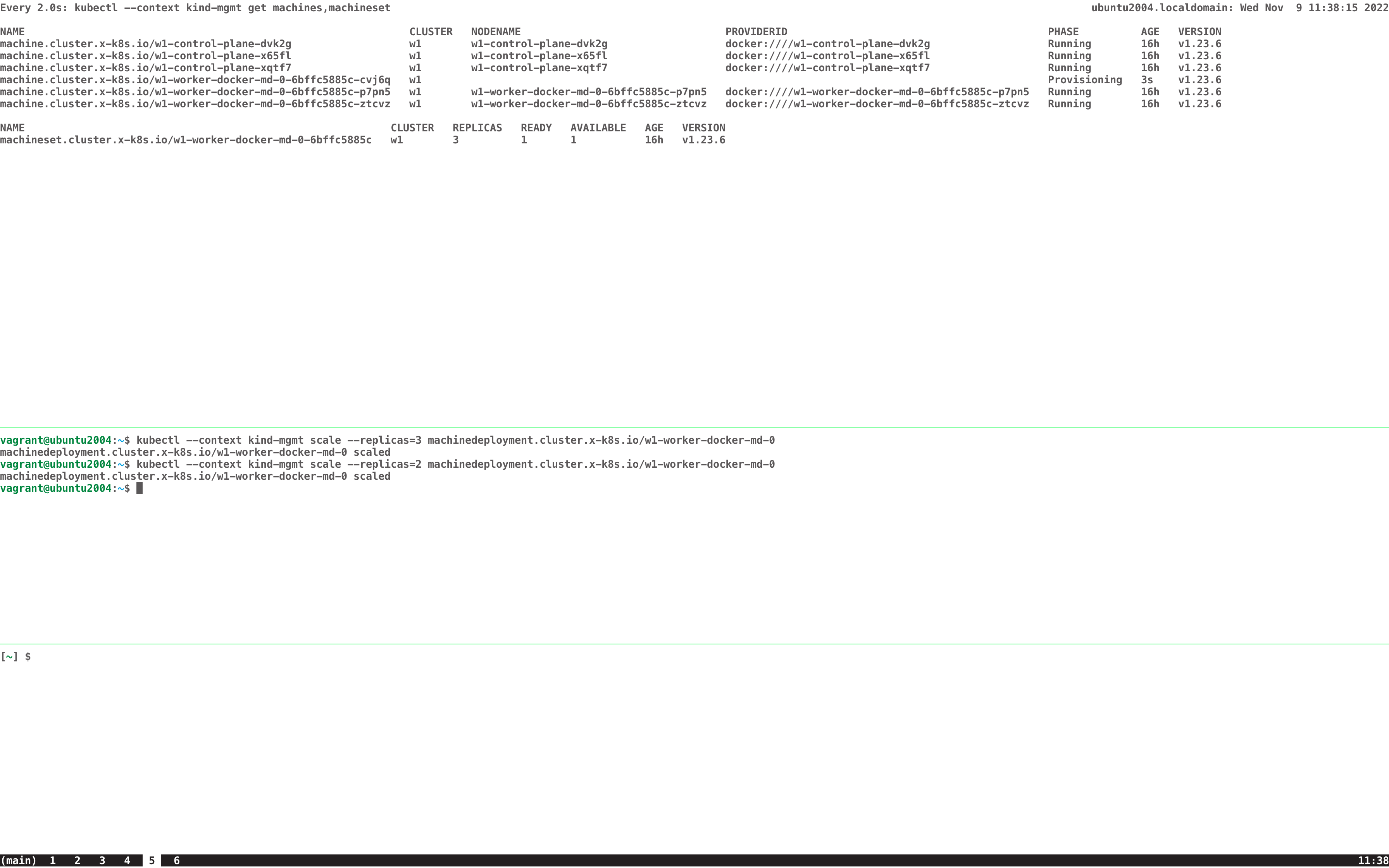
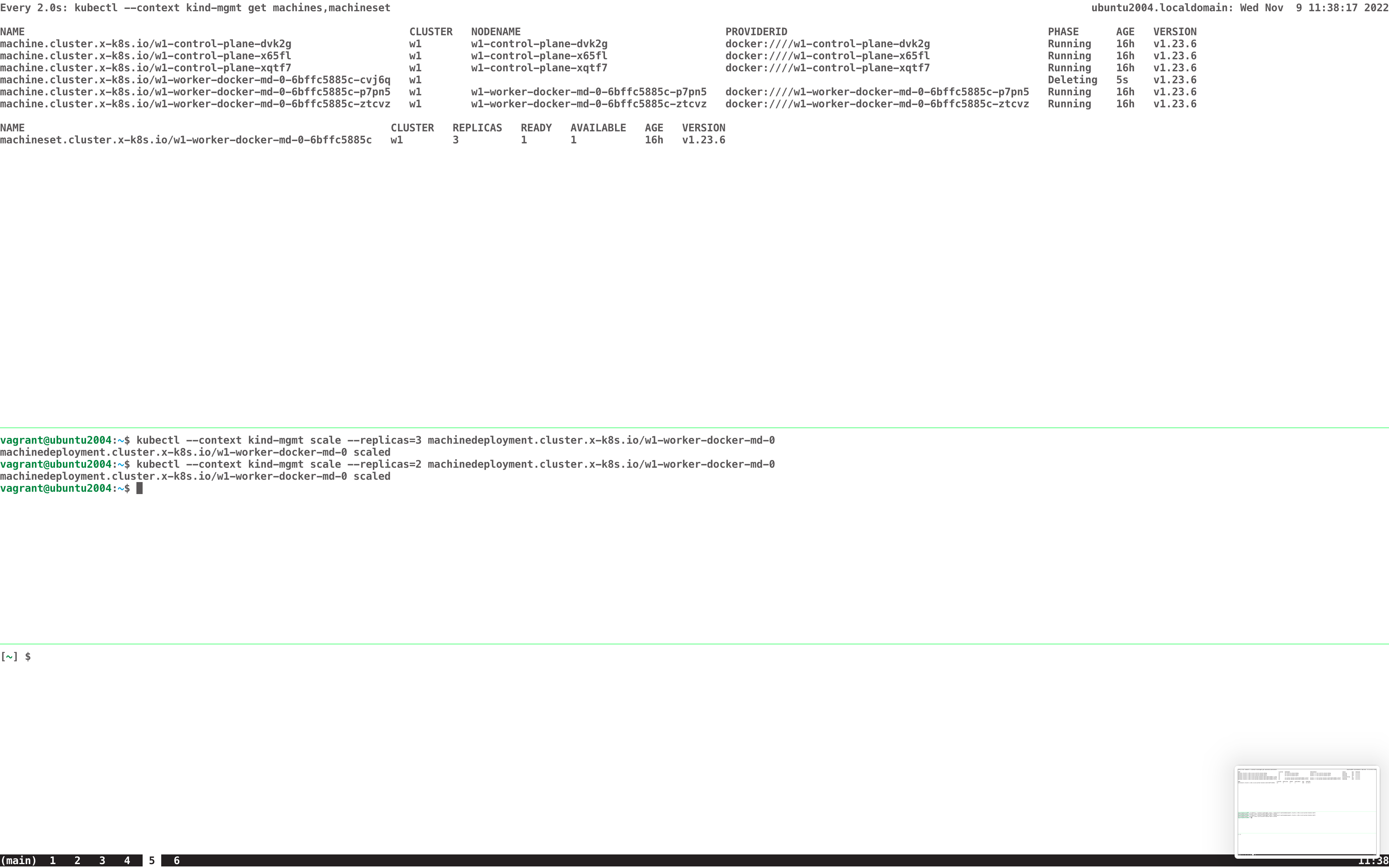
Having OpenShift Container Platform 4 installed on AWS or Azure (does not matter) and MachineSet configured with "deletePolicy: Oldest" can lead to undesired state of MachineSet when parallel scaling (up and down) is happening but provisioning. $ oc get machine NAME PHASE TYPE REGION ZONE AGE fooba03327360-5fzq5-master-0 Running m6i.xlarge us-east-2 us-east-2a 40m fooba03327360-5fzq5-master-1 Running m6i.xlarge us-east-2 us-east-2b 40m fooba03327360-5fzq5-master-2 Running m6i.xlarge us-east-2 us-east-2c 40m fooba03327360-5fzq5-worker-us-east-2a-58k7v Running m6i.large us-east-2 us-east-2a 4m40s fooba03327360-5fzq5-worker-us-east-2a-jgpl2 Provisioning m6i.large us-east-2 us-east-2a 12s fooba03327360-5fzq5-worker-us-east-2a-knhlb Running m6i.large us-east-2 us-east-2a 38m fooba03327360-5fzq5-worker-us-east-2b-tlhnd Running m6i.large us-east-2 us-east-2b 37m fooba03327360-5fzq5-worker-us-east-2c-7hp8x Running m6i.large us-east-2 us-east-2c 4m36s fooba03327360-5fzq5-worker-us-east-2c-g5bps Provisioning m6i.large us-east-2 us-east-2c 12s fooba03327360-5fzq5-worker-us-east-2c-jw66f Deleting m6i.large us-east-2 us-east-2c 38m $ oc get machineset NAME DESIRED CURRENT READY AVAILABLE AGE fooba03327360-5fzq5-worker-us-east-2a 3 3 2 2 40m fooba03327360-5fzq5-worker-us-east-2b 1 1 1 1 40m fooba03327360-5fzq5-worker-us-east-2c 2 2 1 1 40m In the above example, we can see that MachineSet called fooba03327360-5fzq5-worker-us-east-2c is being scaled-up and in parallel a Machine is removed. This already leads to an undesired state as suddenly we have only 1 available OpenShift Container Platform 4 - Node instead of the desired 2. Just consider the provisioning of the new machine would fail because the instance type is currently not available for the MachineSet that is trying to scale or because of another problem. With that we would be stuck with only 1 OpenShift Container Platform 4 - Node instead of the desired 2. So based on the above, the expectation would be that when in parallel up and down scaling is happening and first OpenShift Container Platform 4 - Node(s) in provisioning/provisioned state are going to be removed before any other OpenShift Container Platform 4 - Node is being removed. That way, everything running will continue run and once the OpenShift Container Platform 4 - Node(s) in provisioning/provisioned state are removed, additional action can be taken if further down scaling is required. But it would ensure that capacity does remain available and also that we don't remove OpenShift Container Platform 4 - Node(s) before new OpenShift Container Platform 4 - Node(s) are available and their capacity can be used.
Version-Release number of selected component (if applicable):
OpenShift Container Platform 4.10.28 (but we suspect this applies to all OpenShift Container Platform 4 version currently available)
How reproducible:
Always
Steps to Reproduce:
1. Install OpenShift Container Platform 4 on AWS or Azure for example 2. Set "deletePolicy: Oldest" in the MachineSet 3. Scale the MachineSet up and while the Machine is provisioning Scale down 4 . The MachineSet will only have 1 Node available instead of 2
Actual results:
Only one Machine available in the MachineSet instead of 2 desired because a properly working Machine is removed while provisioning of the new Machine is taking time or eventually will fail at some point in time.
Expected results:
Always try to remove Machines that are in provisioning/provisioned state that are not yet ready before removing perfectly working Machines as otherwise one might experience capacity issues
Additional info: