-
Bug
-
Resolution: Won't Do
-
 Normal
Normal
-
None
-
4.11.z
-
None
-
Quality / Stability / Reliability
-
False
-
-
None
-
Moderate
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
-
None
Description of problem:
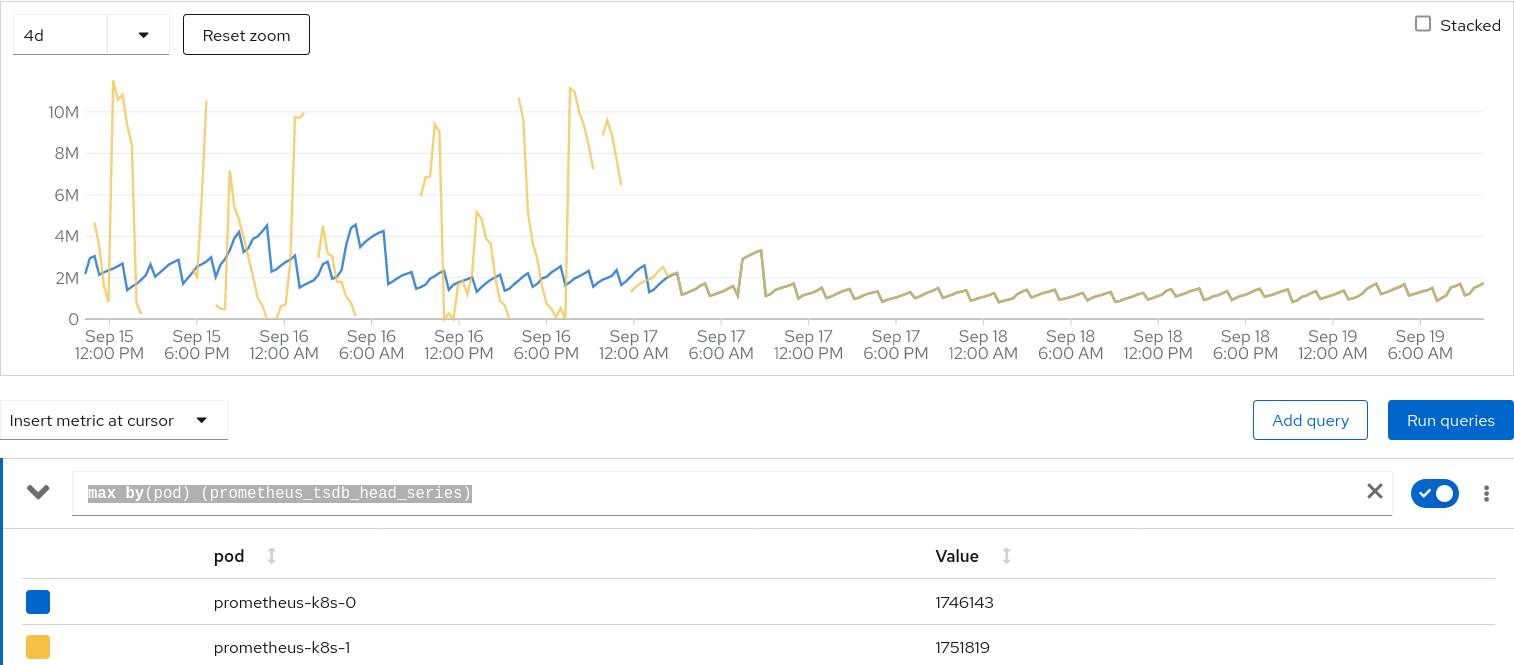
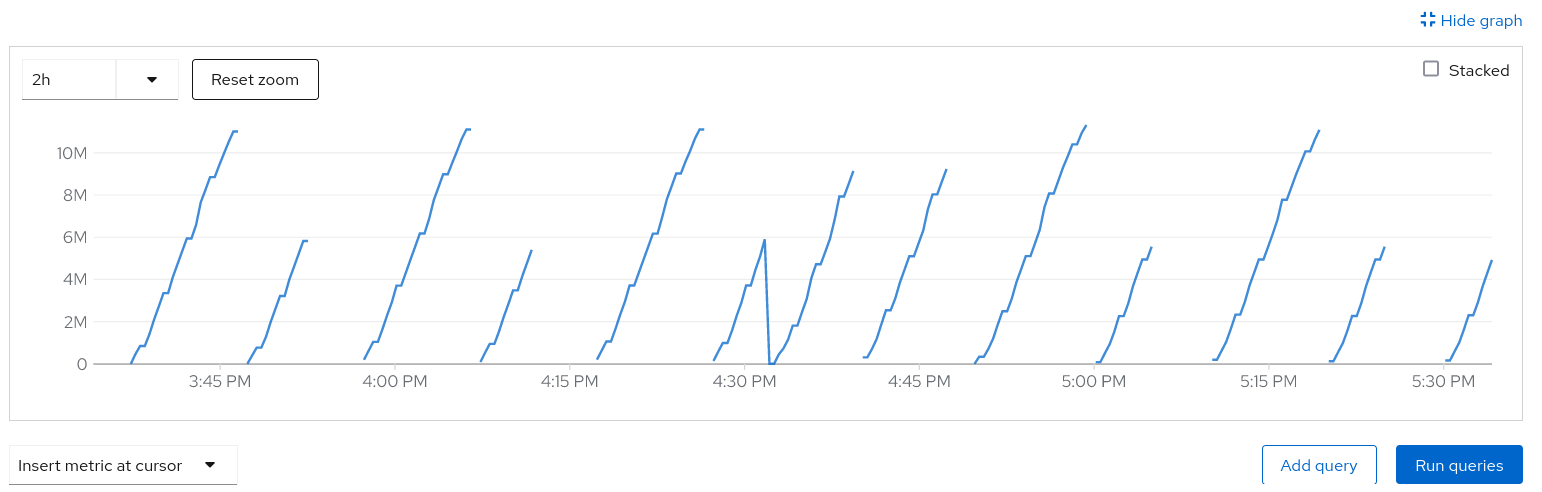
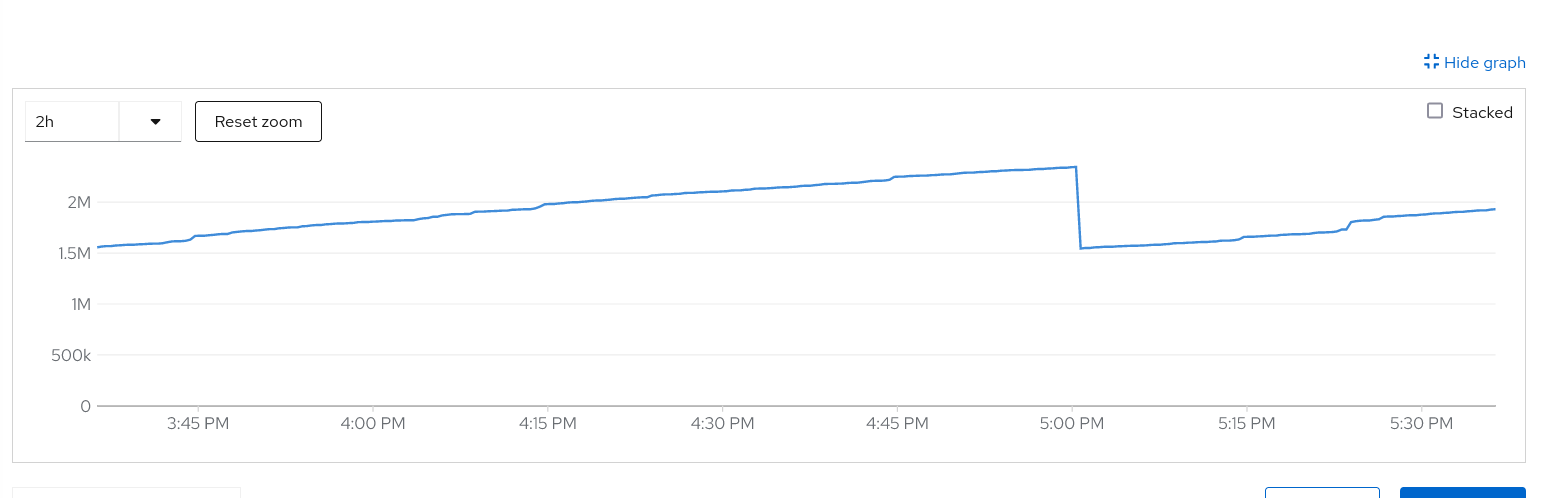
We consistently see pod `prometheus-k8s-1` is being killed and restarted. 1. Restarting is stuck due to WAL reply 2. Pod consumes >17G memory before being killed, which is well beyond the request memory setting (https://github.com/openshift/release/blob/4ad2f102f3b6ff11b1a77331b9f788558c56b548/clusters/build-clusters/01_cluster/openshift-monitoring/cluster-monitoring-config_configmap.yaml#L26)
Version-Release number of selected component (if applicable):
4.11.4
How reproducible:
It just happens to build01, no specific step to trigger the issue.
Steps to Reproduce:
N/A
Actual results:
Name Status Ready Restarts Owner Memory CPU Created prometheus-k8s-1 Running 5/6 41 prometheus-k8s 1,521.2 MiB 0.400 cores Sep 16, 2022, 5:24 AM
Expected results:
1. prometheus-k8s works fine 2. No alarms PrometheusNotConnectedToAlertmanagers is fired
Additional info:
N/A