-
Bug
-
Resolution: Done
-
 Major
Major
-
None
-
4.13, 4.14
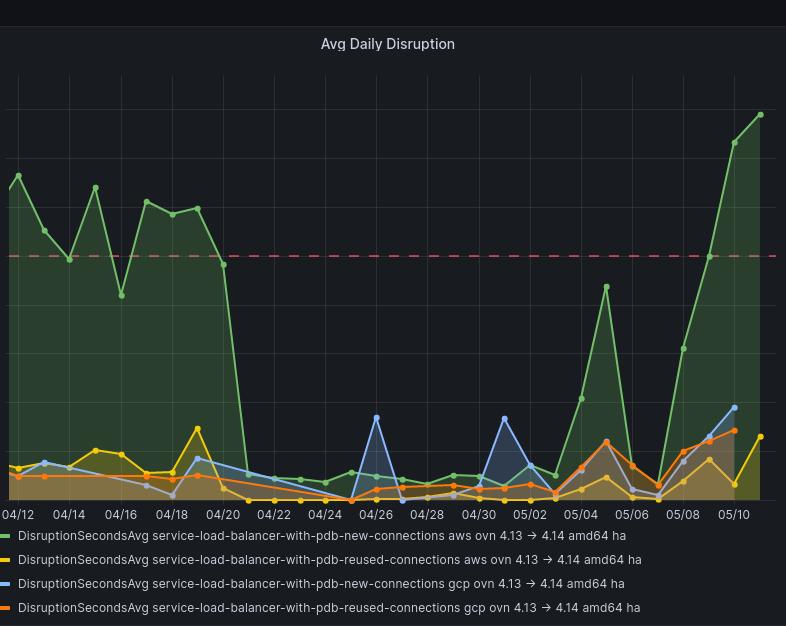
Recently, both 4.14 and 4.13 payloads have been blocked by this disruption variant: "service-load-balancer-with-pdb-new-connections/service-load-balancer-with-pdb-reused-connections xxxxxx should not be worse".
Our analysis indicates that there is a node life cycle behavior change that might be related to this regression. 4.14 data and 4.13 data are very similar. I am going to use 4.13 data for detailed description below since there were fewer changes on 4.13 branch.
Take 4.13 CI as an example
Good payload: https://sippy.dptools.openshift.org/sippy-ng/release/4.13/tags/4.13.0-0.ci-2023-05-06-033438
Problem payload: https://sippy.dptools.openshift.org/sippy-ng/release/4.13/tags/4.13.0-0.ci-2023-05-08-161719
But we do not see any PRs in the problem payload!
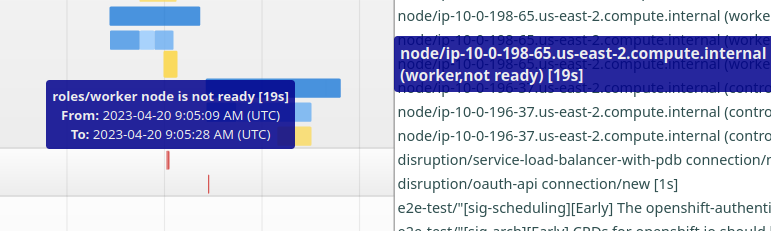
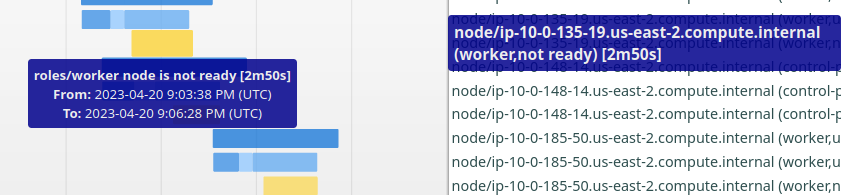
Analysis of the problem indicates reporting of NodeNotReady status seems to be related to the issue. From the following example job runs, if you expand on the first interval chart and go to the node-state section, you will see that, for the worker nodes, the yellow bar that indicates node not ready is narrow and lasted about 20s for the problem job. In comparison, for the good payload, this bar is typically 2 minutes!
This is a job from the good payload: https://prow.ci.openshift.org/view/gs/origin-ci-test/logs/periodic-ci-openshift-release-master-ci-4.13-upgrade-from-stable-4.12-e2e-aws-ovn-upgrade/1654691394544996352
For comparison, here is a job from the problem payload: https://prow.ci.openshift.org/view/gs/origin-ci-test/logs/periodic-ci-openshift-release-master-ci-4.13-upgrade-from-stable-4.12-e2e-aws-ovn-upgrade/1655609894633476096
The CCM (4.14) or in tree kube-controller-manager (4.13) removes the instance from the load balancer based on this status:
I0508 18:31:52.138738 1 aws_loadbalancer.go:1483] Instances removed from load-balancer a24bcbae1386d4d6ca8c710cc358322d
Also in the bad payload run, based on journal log, the short 20s "node not ready" seems to start after a node is rebooted. But in the good payload run, the event started before reboot start (typically over 1 minute).
We are suspecting that, since the node readiness is not changed sooner, and therefore instance is not removed from the load balancer, it causes the disruption we are seeing.
What is odd is that this problem seemed to exist before and somehow it was fixed on 4/20/2023. But then it is broken again between the above example payloads.
Please ping TRT if any more information is needed.

{kind=link}
{kind=link}
{kind=link}
{kind=link}