-
Bug
-
Resolution: Done
-
 Major
Major
-
None
-
4.12
-
Quality / Stability / Reliability
-
False
-
-
None
-
None
-
None
-
None
-
Rejected
-
OPECO 236
-
1
-
None
-
None
-
None
-
None
-
None
-
None
-
None
Description of problem:
See additional info below
Version-Release number of selected component (if applicable):
4.12
How reproducible:
intermittent, but consistent through the day during aggregated jobs run during 4.12-ci payloads.
Steps to Reproduce:
1. Watch the periodic jobs 4.12-ci jobs at https://amd64.ocp.releases.ci.openshift.org/#4.12.0-0.ci; look for aggregated-aws-ovn-upgrade-4.12-minor and the jobs that make up that aggregated job: periodic-ci-openshift-release-master-ci-4.12-upgrade-from-stable-4.11-e2e-aws-ovn-upgrade 2. 3.
Actual results:
ExtremelyHighIndividualControlPlaneCPU and/or HighOverallControlPlaneCPU fires
Expected results:
those two alarms can be pending, but firing causes a failure
Additional info:
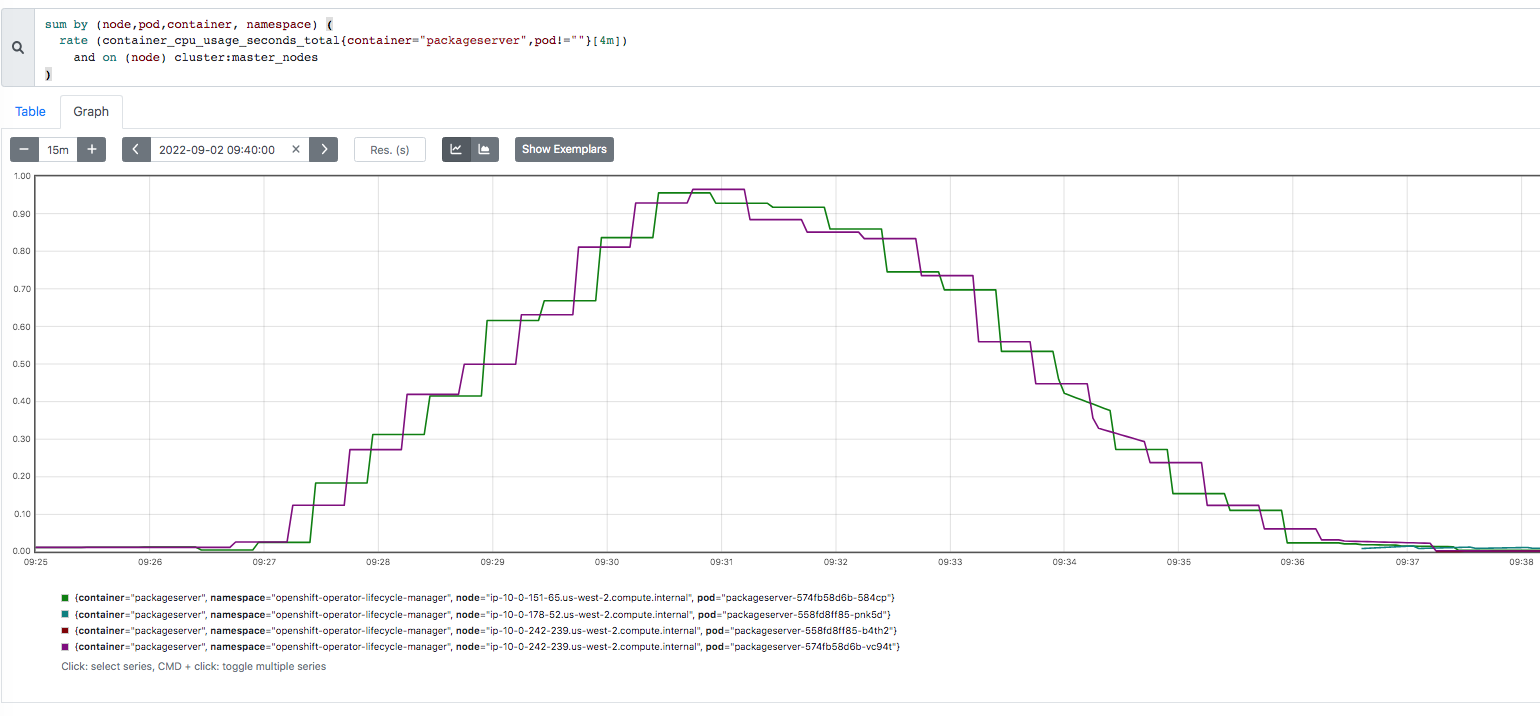
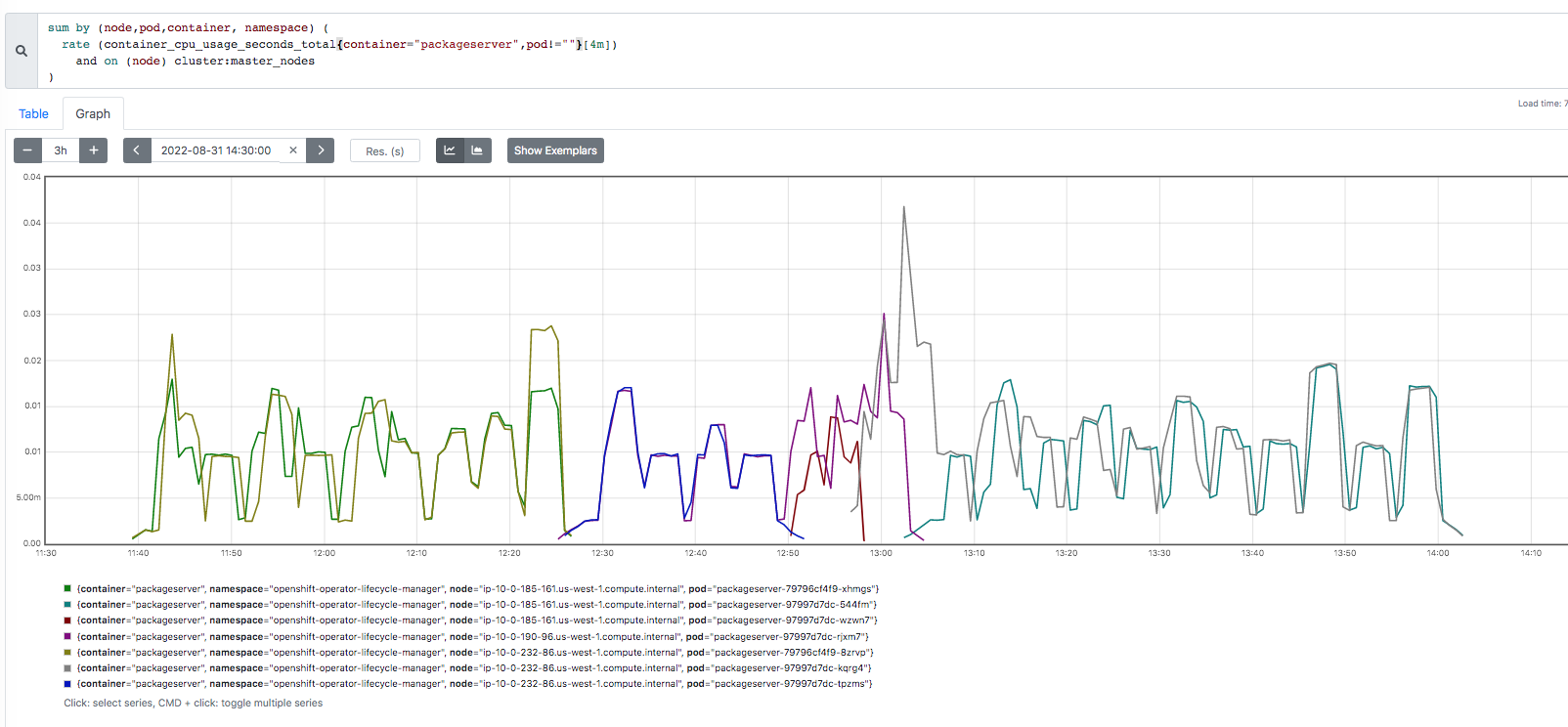
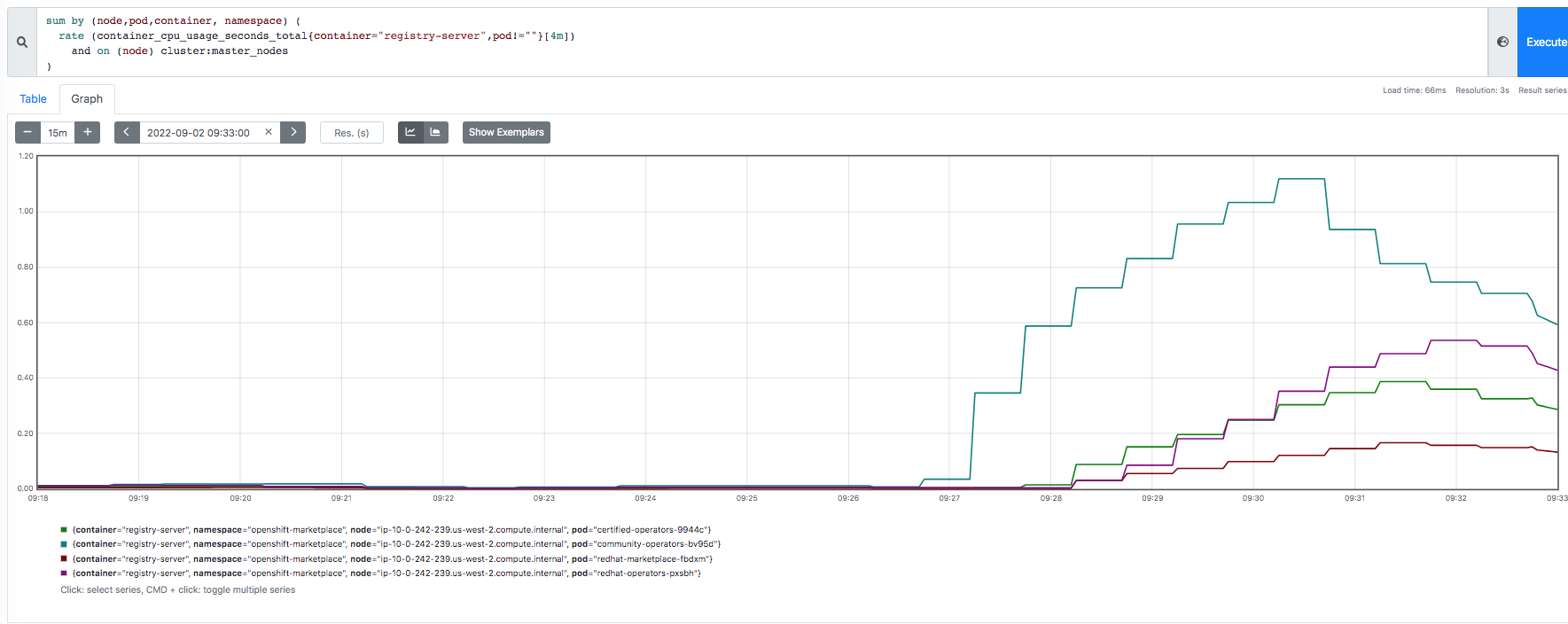
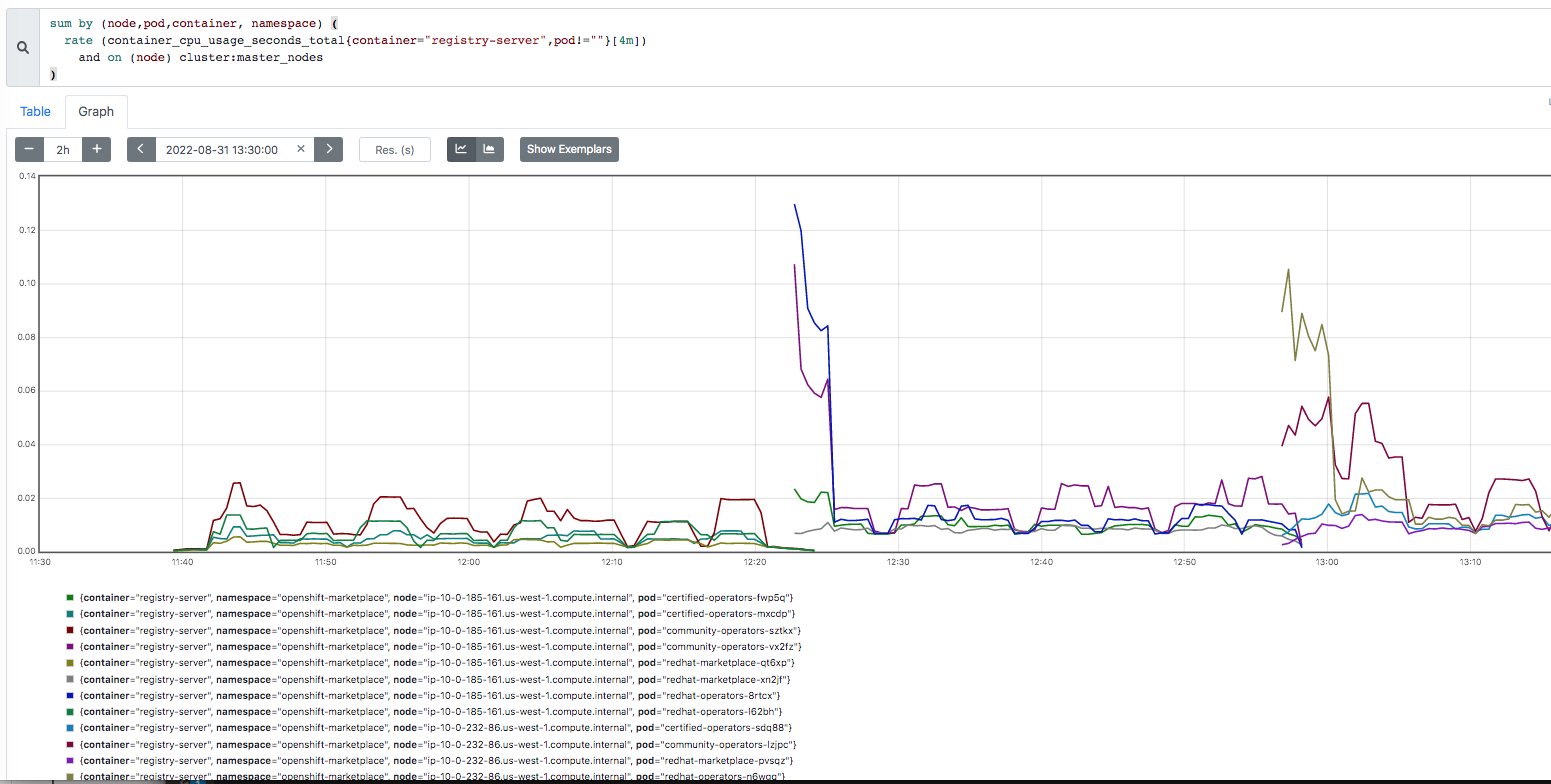
The problem seems to happen a lot on aws and there's even one Azure job that ran about the same time as 3 aws jobs that were part of an aggregated job. https://prow.ci.openshift.org/view/gs/origin-ci-test/logs/aggregated-aws-ovn-upgrade-4.12-minor-release-openshift-release-analysis-aggregator/1569185298498195456 (click on job-run-summary.html to see the jobs that failed) 2022-09-12T04:45:01Z {aws,amd64,sdn,upgrade,upgrade-minor,ha} 630 https://prow.ci.openshift.org/view/gs/origin-ci-test/logs/periodic-ci-openshift-release-master-ci-4.12-upgrade-from-stable-4.11-e2e-aws-sdn-upgrade/1569185286917722112 2022-09-12T04:45:02Z {aws,amd64,ovn,upgrade,upgrade-minor,ha} 570 https://prow.ci.openshift.org/view/gs/origin-ci-test/logs/periodic-ci-openshift-release-master-ci-4.12-upgrade-from-stable-4.11-e2e-aws-ovn-upgrade/1569185295134363648 2022-09-12T04:45:03Z {aws,amd64,ovn,upgrade,upgrade-minor,ha} 360 https://prow.ci.openshift.org/view/gs/origin-ci-test/logs/periodic-ci-openshift-release-master-ci-4.12-upgrade-from-stable-4.11-e2e-aws-ovn-upgrade/1569185297655140352 2022-09-12T04:45:03Z {azure,amd64,sdn,upgrade,upgrade-minor,ha} 150 https://prow.ci.openshift.org/view/gs/origin-ci-test/logs/periodic-ci-openshift-release-master-ci-4.12-upgrade-from-stable-4.11-e2e-azure-sdn-upgrade/1569185300184305664 2022-09-12T10:41:13Z {aws,amd64,ovn,upgrade,upgrade-minor,ha} 150 https://prow.ci.openshift.org/view/gs/origin-ci-test/logs/periodic-ci-openshift-release-master-ci-4.12-upgrade-from-stable-4.11-e2e-aws-ovn-upgrade/1569274931672256512 2022-09-12T10:41:14Z {aws,amd64,ovn,upgrade,upgrade-minor,ha} 810 https://prow.ci.openshift.org/view/gs/origin-ci-test/logs/periodic-ci-openshift-release-master-ci-4.12-upgrade-from-stable-4.11-e2e-aws-ovn-upgrade/1569274933320617984 I focus on https://prow.ci.openshift.org/view/gs/origin-ci-test/logs/periodic-ci-openshift-release-master-ci-4.12-upgrade-from-stable-4.11-e2e-aws-ovn-upgrade/1565615240895270912 (though the azure job above had a similar symptom). Logs for the registry-server container (during time of high cpu): $ cat certified-operators-s2xtt-registry-server-ip-10-0-180-56.us-east-2.log 2022-09-02T08:44:33Z {} time="2022-09-02T08:44:32Z" level=info msg="serving registry" configs=/configs port=50051 2022-09-02T08:44:37Z {} time="2022-09-02T08:44:37Z" level=info msg="serving registry" configs=/configs port=50051 2022-09-02T08:44:46Z {} time="2022-09-02T08:44:45Z" level=info msg="serving registry" configs=/configs port=50051 2022-09-02T08:44:55Z {} time="2022-09-02T08:44:55Z" level=info msg="serving registry" configs=/configs port=50051 2022-09-02T09:46:23Z {} time="2022-09-02T09:46:22Z" level=info msg="shutting down..." configs=/configs port=50051 2022-09-02T09:46:23Z {} time="2022-09-02T09:46:23Z" level=info msg="shutting down..." configs=/configs port=50051 2022-09-02T09:46:23Z {} time="2022-09-02T09:46:23Z" level=info msg="shutting down..." configs=/configs port=50051 2022-09-02T09:46:24Z {} time="2022-09-02T09:46:24Z" level=info msg="shutting down..." configs=/configs port=50051 $ cat community-operators-qggrl-registry-server-ip-10-0-180-56.us-east-2.log 2022-09-02T08:44:33Z {} time="2022-09-02T08:44:32Z" level=info msg="serving registry" configs=/configs port=50051 2022-09-02T08:44:37Z {} time="2022-09-02T08:44:37Z" level=info msg="serving registry" configs=/configs port=50051 2022-09-02T08:44:46Z {} time="2022-09-02T08:44:45Z" level=info msg="serving registry" configs=/configs port=50051 2022-09-02T08:44:55Z {} time="2022-09-02T08:44:55Z" level=info msg="serving registry" configs=/configs port=50051 2022-09-02T09:46:22Z {} time="2022-09-02T09:46:22Z" level=info msg="shutting down..." configs=/configs port=50051 2022-09-02T09:46:23Z {} time="2022-09-02T09:46:23Z" level=info msg="shutting down..." configs=/configs port=50051 2022-09-02T09:46:23Z {} time="2022-09-02T09:46:23Z" level=info msg="shutting down..." configs=/configs port=50051 2022-09-02T09:46:24Z {} time="2022-09-02T09:46:24Z" level=info msg="shutting down..." configs=/configs port=50051 $ cat redhat-marketplace-grjqc-registry-server-ip-10-0-180-56.us-east-2.log 2022-09-02T08:44:33Z {} time="2022-09-02T08:44:32Z" level=info msg="serving registry" configs=/configs port=50051 2022-09-02T08:44:37Z {} time="2022-09-02T08:44:37Z" level=info msg="serving registry" configs=/configs port=50051 2022-09-02T08:44:46Z {} time="2022-09-02T08:44:45Z" level=info msg="serving registry" configs=/configs port=50051 2022-09-02T08:44:55Z {} time="2022-09-02T08:44:55Z" level=info msg="serving registry" configs=/configs port=50051 2022-09-02T09:46:22Z {} time="2022-09-02T09:46:22Z" level=info msg="shutting down..." configs=/configs port=50051 2022-09-02T09:46:23Z {} time="2022-09-02T09:46:23Z" level=info msg="shutting down..." configs=/configs port=50051 2022-09-02T09:46:23Z {} time="2022-09-02T09:46:23Z" level=info msg="shutting down..." configs=/configs port=50051 2022-09-02T09:46:24Z {} time="2022-09-02T09:46:24Z" level=info msg="shutting down..." configs=/configs port=50051 $ cat redhat-operators-xkb6z-registry-server-ip-10-0-180-56.us-east-2.log 2022-09-02T08:44:33Z {} time="2022-09-02T08:44:32Z" level=info msg="serving registry" configs=/configs port=50051 2022-09-02T08:44:37Z {} time="2022-09-02T08:44:37Z" level=info msg="serving registry" configs=/configs port=50051 2022-09-02T08:44:46Z {} time="2022-09-02T08:44:45Z" level=info msg="serving registry" configs=/configs port=50051 2022-09-02T08:44:55Z {} time="2022-09-02T08:44:55Z" level=info msg="serving registry" configs=/configs port=50051 2022-09-02T09:46:22Z {} time="2022-09-02T09:46:22Z" level=info msg="shutting down..." configs=/configs port=50051 2022-09-02T09:46:23Z {} time="2022-09-02T09:46:23Z" level=info msg="shutting down..." configs=/configs port=50051 2022-09-02T09:46:23Z {} time="2022-09-02T09:46:23Z" level=info msg="shutting down..." configs=/configs port=50051 2022-09-02T09:46:24Z {} time="2022-09-02T09:46:24Z" level=info msg="shutting down..." configs=/configs port=50051 The log for packageserver-5b5875b99f-lrx7q is enclosed but here's a snippet (note the "connection refused" happens when the "shutting down..." is happening in the container logs above): 2022-09-02T09:37:47Z {} time="2022-09-02T09:37:47Z" level=info msg="updating PackageManifest based on CatalogSource changes: {community-operators openshift-marketplace}" action="sync catalogsource" address="community-operators.openshift-marketplace.svc:50051" name=community-operators namespace=openshift-marketplace 2022-09-02T09:37:48Z {} time="2022-09-02T09:37:48Z" level=info msg="updating PackageManifest based on CatalogSource changes: {community-operators openshift-marketplace}" action="sync catalogsource" address="community-operators.openshift-marketplace.svc:50051" name=community-operators namespace=openshift-marketplace 2022-09-02T09:37:49Z {} time="2022-09-02T09:37:49Z" level=info msg="updating PackageManifest based on CatalogSource changes: {community-operators openshift-marketplace}" action="sync catalogsource" address="community-operators.openshift-marketplace.svc:50051" name=community-operators namespace=openshift-marketplace ... 2022-09-02T09:46:23Z {} time="2022-09-02T09:46:23Z" level=warning msg="error getting stream" action="refresh cache" err="rpc error: code = Unavailable desc = connection error: desc = \"transport: Error while dialing dial tcp 172.30.72.18:50051: connect: connection refused\"" source="{redhat-marketplace openshift-marketplace}" prow jobs on the 4.12-ci periodics are failing with this (for example: https://prow.ci.openshift.org/view/gs/origin-ci-test/logs/periodic-ci-openshift-release-master-ci-4.12-upgrade-from-stable-4.11-e2e-aws-ovn-upgrade/1565615240895270912): disruption_tests: [sig-arch] Check if alerts are firing during or after upgrade success expand_less 1h14m41s {Sep 2 10:31:23.115: Unexpected alerts fired or pending during the upgrade: alert ExtremelyHighIndividualControlPlaneCPU fired for 210 seconds with labels: {instance="ip-10-0-180-56.us-east-2.compute.internal", namespace="openshift-kube-apiserver", severity="warning"} Failure Sep 2 10:31:23.115: Unexpected alerts fired or pending during the upgrade: alert ExtremelyHighIndividualControlPlaneCPU fired for 210 seconds with labels: {instance="ip-10-0-180-56.us-east-2.compute.internal", namespace="openshift-kube-apiserver", severity="warning"} Goto to the spyglass charts and enter "HighOverallControlPlaneCPU|ExtremelyHighIndividualControlPlaneCPU" in the regex box to see the intervals where the alerts are firing. I focus on the alert firing from 9:43-9:47. The containers taking up cpu are: 1) packageserver (ns=openshift-operator-lifcycle-manager); 2 pods on different master nodes 2) registry-server (ns=openshift-marketplace); 4 pods on same master node. There are 4 pod types: certified-operators community-operators redhat-marketplace redhat-operators packageserver containers are trying to talk to the registry-server containers(on port 50051) and often get "connection refused"; this rules out a connectivity issue because "connection refused" means nothing is answering on that port. During the time where there is high cpu usage, you will see "level=info msg="updating PackageManifest based on CatalogSource changes" in the logs. registry-server pods all have one of two messages: level=info msg="serving registry" configs=/configs port=50051 level=info msg="shutting down" configs=/configs port=50051 These messages occur multiple times where the container's app appears to shutdown/restart often. During the time after the "shutting down" message, you will see the "connection refused" on the packageserver container logs. Use this PromQL query for the ExtremelyHighIndividualControlPlaneCPU alert: 100 - (avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[1m])) * 100) > 90 AND on (instance) label_replace( kube_node_role{role="master"}, "instance", "$1", "node", "(.+)" ) Use this PromQL query for the HighOverallControlPlaneCPU alert: 100 - (avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[1m])) * 100) > 90 AND on (instance) label_replace( kube_node_role{role="master"}, "instance", "$1", "node", "(.+)" ) Use this query to see packageserver containers: sum by (node,pod,container, namespace) ( rate (container_cpu_usage_seconds_total{container="packageserver",pod!=""}[4m]) and on (node) cluster:master_nodes ) Use this query to see registry-server containers: sum by (node,pod,container, namespace) ( rate (container_cpu_usage_seconds_total{container="registry-server",pod!=""}[4m]) and on (node) cluster:master_nodes ) The jobs that get this symptom seem to happen in "chunks" -- the timestamps are roughly the same and are many times part of the same aggregated job. The first aggregated job to see the problem is: https://sippy.dptools.openshift.org/sippy-ng/release/4.12/tags/4.12.0-0.ci-2022-08-31-144550 (2022-08-31 14:51:45 +0000 UTC) The last job to not see the problem is: https://sippy.dptools.openshift.org/sippy-ng/release/4.12/tags/4.12.0-0.ci-2022-08-31-111359 (2022-08-31 11:15:17 +0000 UTC) The jobs that worked before have similar behavior but there are less logs in packagserver containers, the registry-server pods look like they have "serving registry" and the "shutting down" message happens after a good 10 minutes (during which packageserver container pods seem to be ok -- no "connection refused" errors). Both containers use significantly less cpu. Something changed within the window of 11:15:17 and 14:51:45 on Aug 31, 2022 (7:15am to 10:51pm EST).