-
Bug
-
Resolution: Can't Do
-
 Undefined
Undefined
-
None
-
4.12, 4.11
-
Quality / Stability / Reliability
-
False
-
-
3
-
None
-
No
-
4/12: telco review pending (NC)
-
None
-
None
-
None
-
ETCD Sprint 234, ETCD Sprint 235
-
2
-
None
-
None
-
None
-
None
-
None
-
None
-
None
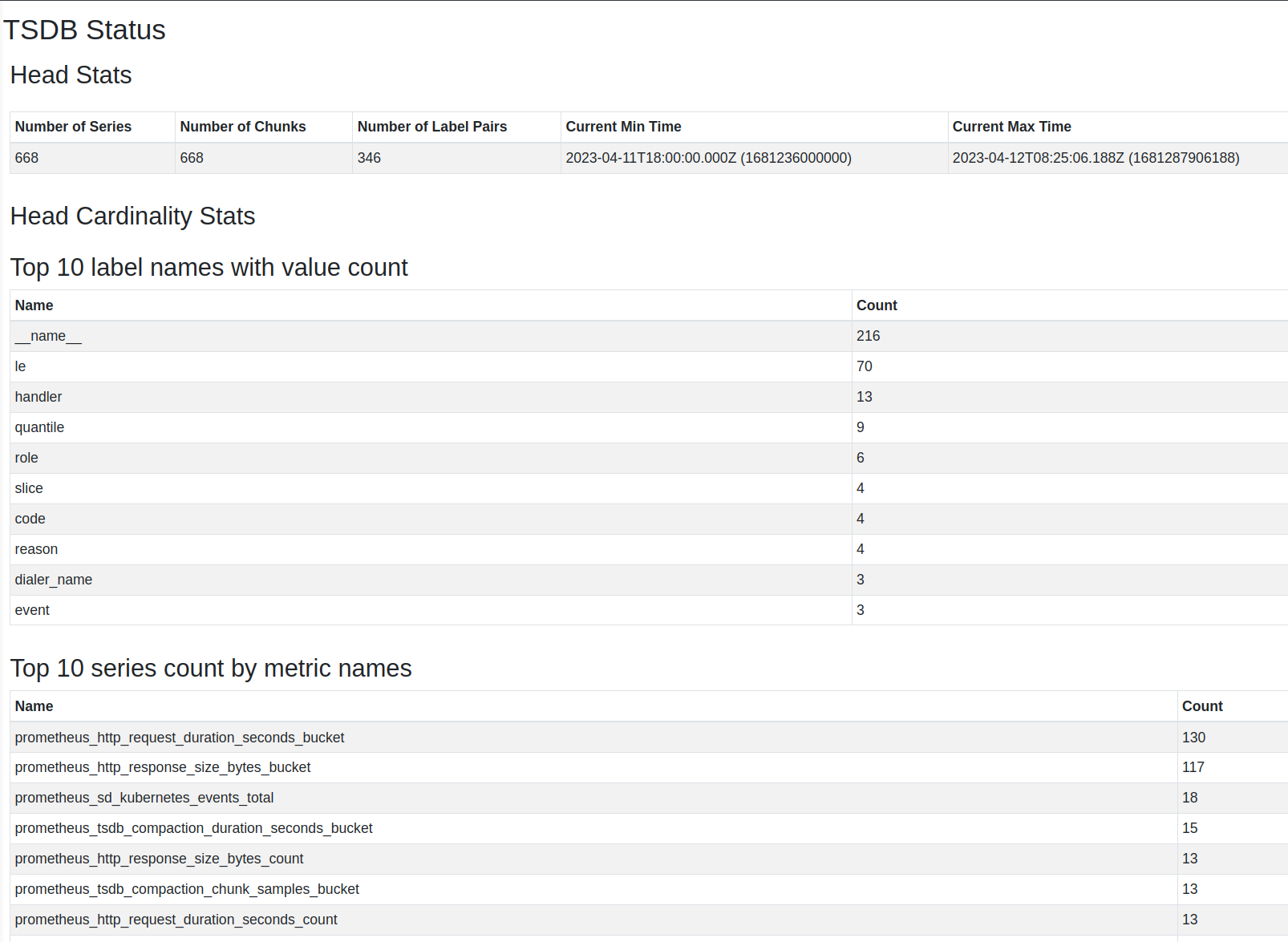
Description of problem:
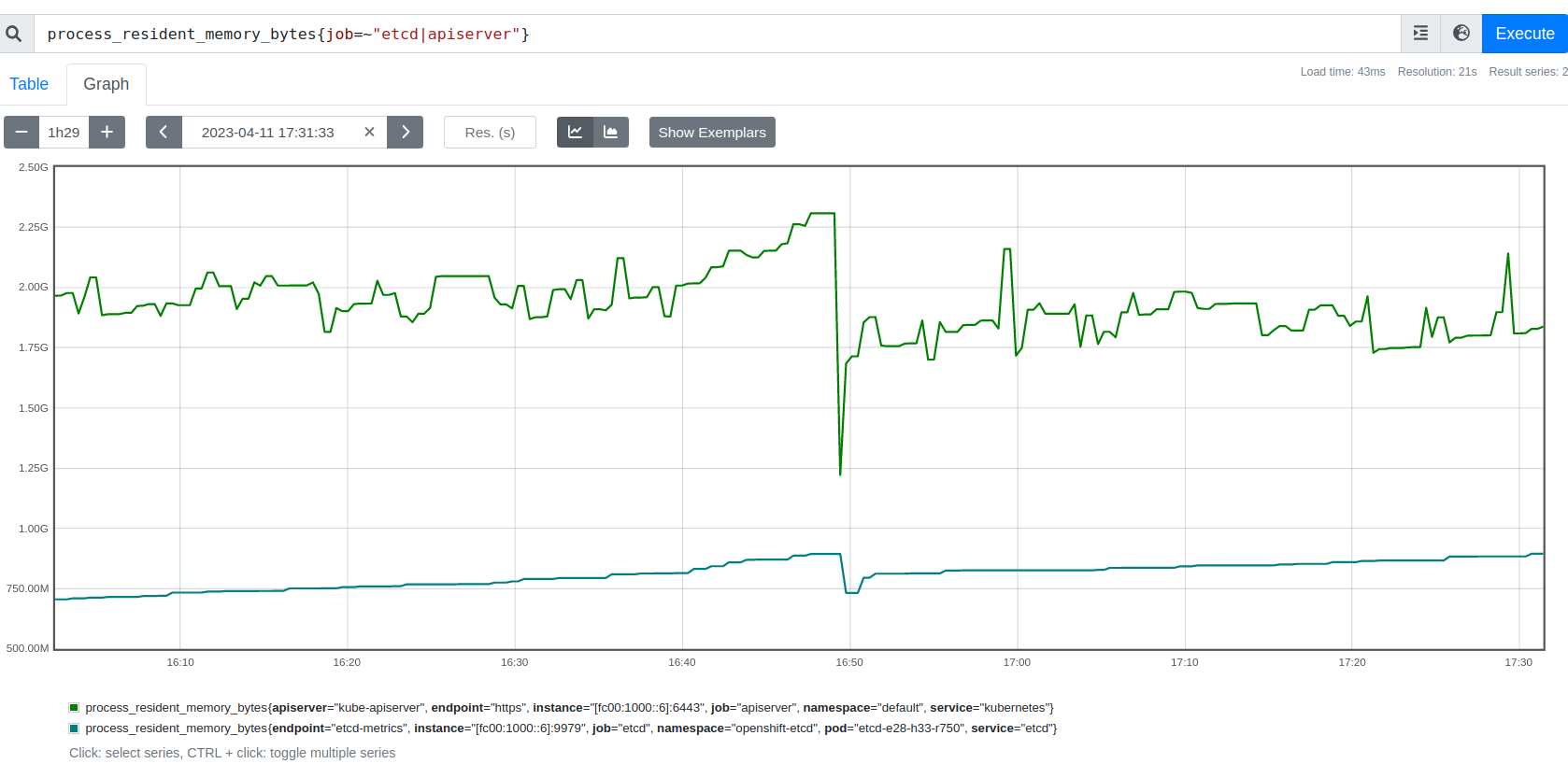
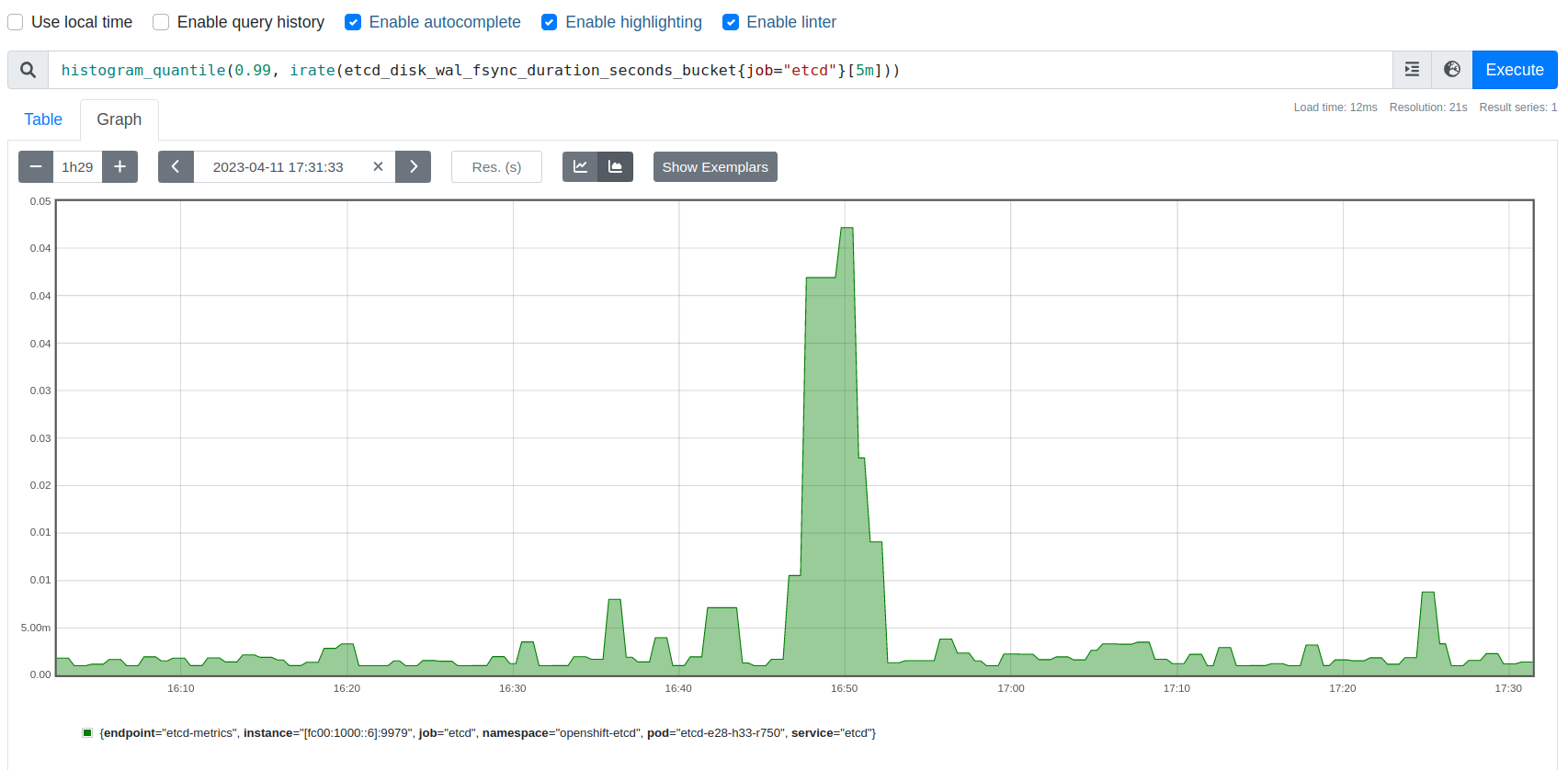
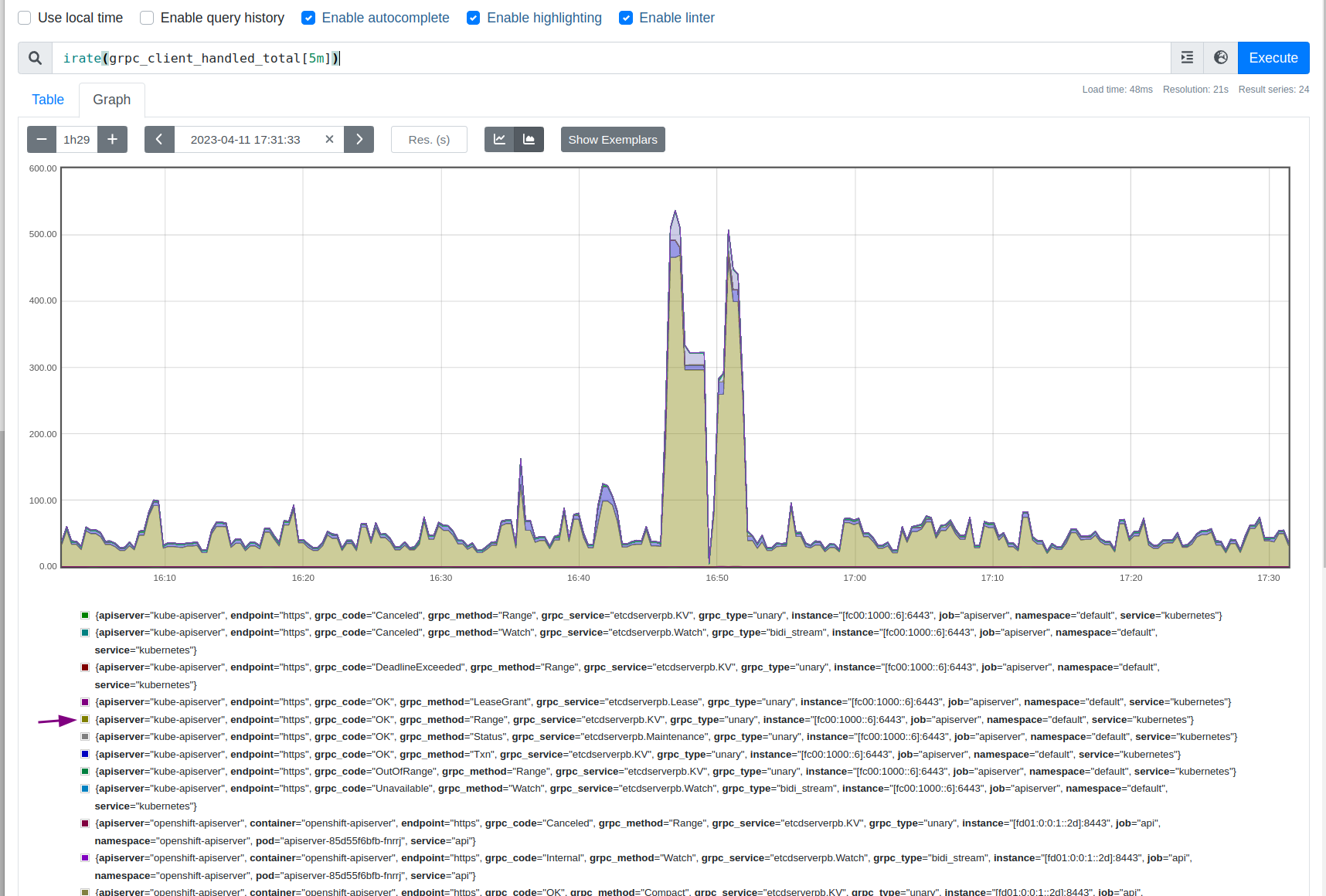
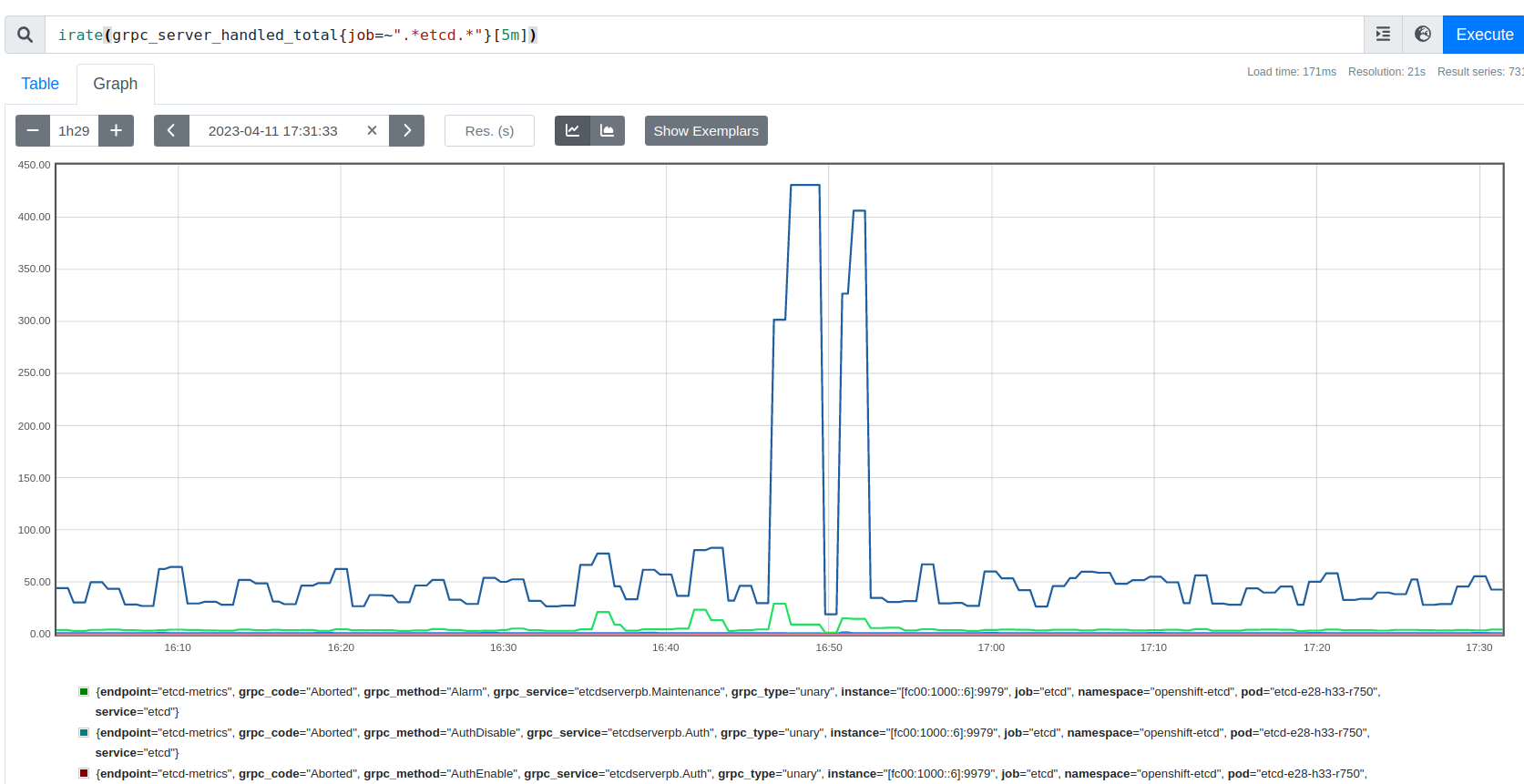
While running scale tests on a SNO with DU profile and 4 reserved cores, etcd server failure is observed during pod cleanup cycle (seen with as low as ~30 pods). Several Cluster operators are observed to be degraded temporarily at the same time.
# oc get co
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE
authentication 4.12.2 True False False 116s
baremetal 4.12.2 True False False 55d
cloud-controller-manager 4.12.2 True False False 55d
cloud-credential 4.12.2 True False False 55d
cluster-autoscaler 4.12.2 True False False 55d
config-operator 4.12.2 True False False 55d
console 4.12.2 True False False 55d
control-plane-machine-set 4.12.2 True False False 55d
csi-snapshot-controller 4.12.2 True False False 43h
dns 4.12.2 True False False 43h
etcd 4.12.2 True False False 43h
image-registry 4.12.2 True False False 43h
ingress 4.12.2 True False False 55d
insights 4.12.2 False False True 9d Unable to report: unable to build request to connect to Insights server: Post "https://console.redhat.com/api/ingress/v1/upload": dial tcp [2600:1407:e800:8::17c6:60e]:443: connect: network is unreachable
kube-apiserver 4.12.2 True False False 55d
kube-controller-manager 4.12.2 True False True 55d GarbageCollectorDegraded: error fetching rules: Get "https://thanos-querier.openshift-monitoring.svc:9091/api/v1/rules": dial tcp [fd02::2a03]:9091: connect: connection refused
kube-scheduler 4.12.2 True False False 55d
kube-storage-version-migrator 4.12.2 True False False 43h
machine-api 4.12.2 True False False 55d
machine-approver 4.12.2 True False False 55d
machine-config 4.12.2 True False False 12d
marketplace 4.12.2 True False False 55d
monitoring 4.12.2 False True True 2m47s reconciling Thanos Querier Deployment failed: updating Deployment object failed: waiting for DeploymentRollout of openshift-monitoring/thanos-querier: got 1 unavailable replicas
network 4.12.2 True False False 55d
node-tuning 4.12.2 True False False 43h
openshift-apiserver 4.12.2 True False False 2m47s
openshift-controller-manager 4.12.2 False True False 40h Available: no openshift controller manager daemon pods available on any node.
openshift-samples 4.12.2 True False False 55d
operator-lifecycle-manager 4.12.2 True False False 55d
operator-lifecycle-manager-catalog 4.12.2 True False False 55d
operator-lifecycle-manager-packageserver 4.12.2 True False False 43h
service-ca 4.12.2 True False False 55d
storage 4.12.2 True False False 55d
From etcd pod logs:
2023-04-04T20:07:51.939581764Z {"level":"warn","ts":"2023-04-04T20:07:51.939Z","caller":"etcdserver/util.go:166","msg":"apply request took too long","took":"260.234149ms","expected-duration":"200ms","prefix":"read-only range ","request":"key:\"/kubernetes.io/services/specs/boatload-bu-15/\" range_end:\"/kubernetes.io/services/specs/boatload-bu-150\" ","response":"range_response_count:0 size:7"}
2023-04-04T20:07:51.939677435Z {"level":"info","ts":"2023-04-04T20:07:51.939Z","caller":"traceutil/trace.go:171","msg":"trace[1607250934] range","detail":"{range_begin:/kubernetes.io/services/specs/boatload-bu-15/; range_end:/kubernetes.io/services/specs/boatload-bu-150; response_count:0; response_revision:19760801; }","duration":"260.351058ms","start":"2023-04-04T20:07:51.679Z","end":"2023-04-04T20:07:51.939Z","steps":["trace[1607250934] 'agreement among raft nodes before linearized reading' (duration: 260.207423ms)"],"step_count":1}
2023-04-04T20:07:58.444285364Z {"level":"info","ts":"2023-04-04T20:07:58.444Z","caller":"osutil/interrupt_unix.go:64","msg":"received signal; shutting down","signal":"terminated"}
2023-04-04T20:07:58.444602126Z {"level":"info","ts":"2023-04-04T20:07:58.444Z","caller":"embed/etcd.go:375","msg":"closing etcd server","name":"e28-h33-r750","data-dir":"/var/lib/etcd","advertise-peer-urls":["https://[fc00:1000::6]:2380"],"advertise-client-urls":["https://[fc00:1000::6]:2379"]}
2023-04-04T20:07:58.505158655Z {"level":"warn","ts":"2023-04-04T20:07:58.497Z","caller":"v3rpc/watch.go:457","msg":"failed to send watch response to gRPC stream","error":"rpc error: code = Unavailable desc = transport is closing"}
2023-04-04T20:07:58.523801307Z {"level":"warn","ts":"2023-04-04T20:07:58.523Z","caller":"v3rpc/watch.go:457","msg":"failed to send watch response to gRPC stream","error":"rpc error: code = Unavailable desc = transport is closing"}
2023-04-04T20:07:58.729935061Z {"level":"info","ts":"2023-04-04T20:07:58.729Z","caller":"etcdserver/server.go:1474","msg":"skipped leadership transfer for single voting member cluster","local-member-id":"712b9fdeba35e541","current-leader-member-id":"712b9fdeba35e541"}
2023-04-04T20:07:58.742936339Z {"level":"info","ts":"2023-04-04T20:07:58.742Z","caller":"embed/etcd.go:570","msg":"stopping serving peer traffic","address":"[::]:2380"}
2023-04-04T20:07:58.745113323Z {"level":"info","ts":"2023-04-04T20:07:58.745Z","caller":"embed/etcd.go:575","msg":"stopped serving peer traffic","address":"[::]:2380"}
2023-04-04T20:07:58.745190767Z {"level":"info","ts":"2023-04-04T20:07:58.745Z","caller":"embed/etcd.go:377","msg":"closed etcd server","name":"e28-h33-r750","data-dir":"/var/lib/etcd","advertise-peer-urls":["https://[fc00:1000::6]:2380"],"advertise-client-urls":["https://[fc00:1000::6]:2379"]}
From kube-apiserver pod logs:
2023-04-04T20:08:48.397657020Z }. Err: connection error: desc = "transport: Error while dialing dial tcp [::1]:2379: connect: connection refused"
2023-04-04T20:08:49.521386018Z I0404 20:08:49.521227 15 available_controller.go:496] "changing APIService availability" name="v1.packages.operators.coreos.com" oldStatus=True newStatus=False message="failing or missing response from
https://[fd01:0:0:1::41]:5443/apis/packages.operators.coreos.com/v1: Get \"https://[fd01:0:0:1::41]:5443/apis/packages.operators.coreos.com/v1\": net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)" reason="FailedDiscoveryCheck"
2023-04-04T20:08:50.166279405Z {"level":"warn","ts":"2023-04-04T20:08:50.165Z","logger":"etcd-client","caller":"v3/retry_interceptor.go:62","msg":"retrying of unary invoker failed","target":"etcd-endpoints://0xc00055aa80/[fc00:1000::6]:2379","attempt":0,"error":"rpc error: code = DeadlineExceeded desc = latest balancer error: last connection error: connection error: desc = \"transport: Error while dialing dial tcp [fc00:1000::6]:2379: connect: connection refused\""}
2023-04-04T20:08:50.166475616Z I0404 20:08:50.166411 15 healthz.go:257] etcd,etcd-readiness,shutdown check failed: readyz
2023-04-04T20:08:50.166475616Z [-]etcd failed: error getting data from etcd: context deadline exceeded
2023-04-04T20:08:50.166475616Z [-]etcd-readiness failed: error getting data from etcd: context deadline exceeded
2023-04-04T20:08:50.166475616Z [-]shutdown failed: process is shutting down
2023-04-04T20:08:50.199255272Z {"level":"warn","ts":"2023-04-04T20:08:50.198Z","logger":"etcd-client","caller":"v3/retry_interceptor.go:62","msg":"retrying of unary invoker failed","target":"etcd-endpoints://0xc002acd500/[fc00:1000::6]:2379","attempt":0,"error":"rpc error: code = Canceled desc = latest balancer error: last connection error: connection error: desc = \"transport: Error while dialing dial tcp [::1]:2379: connect: connection refused\""}
2023-04-04T20:08:50.199255272Z E0404 20:08:50.198947 15 status.go:71] apiserver received an error that is not an metav1.Status: &errors.errorString{s:"context canceled"}: context canceled
2023-04-04T20:08:50.199255272Z E0404 20:08:50.198998 15 writers.go:118] apiserver was unable to write a JSON response: http: Handler timeout
2023-04-04T20:08:50.200436823Z E0404 20:08:50.200345 15 status.go:71] apiserver received an error that is not an metav1.Status: &errors.errorString{s:"http: Handler timeout"}: http: Handler timeout
2023-04-04T20:08:50.206437803Z E0404 20:08:50.205298 15 writers.go:131] apiserver was unable to write a fallback JSON response: http: Handler timeout
2023-04-04T20:08:50.206540849Z I0404 20:08:50.206456 15 trace.go:205] Trace[717751367]: "Get" url:/api/v1/namespaces/boatload-bu-20/pods/boatload-20-1-boatload-bu-865796d85f-4ll6w,user-agent:multus/v0.0.0 (linux/amd64) kubernetes/$Format,audit-id:267a2554-43be-4dde-b55d-5e08e3d4d1a3,client:fc00:1000::6,accept:application/vnd.kubernetes.protobuf,application/json,protocol:HTTP/2.0 (04-Apr-2023 20:08:01.844) (total time: 48362ms):
2023-04-04T20:08:50.206540849Z Trace[717751367]: [48.36239571s] [48.36239571s] END
Version-Release number of selected component (if applicable):
OCP 4.12.2
Kernel version: 4.18.0-372.41.1.rt7.198.el8_6.x86_64
Cri-o - cri-o://1.25.2-4.rhaos4.12.git66af2f6.el8
How reproducible:
1. Setup SNO with DU profile 2. start up scale test which starts 30 test pods (guaranteed and burstable pods) and waits 3 minutes after startup and then pods are cleaned up. This issue is noticed consistently during cleanup phase even if the wait time between pod start and cleanup is increased to 2 hours.
Steps to Reproduce:
1. 2. 3.
Actual results:
Etcd is expected to be stable during workload creation/deletion phase
Expected results:
Etcd pod not expected to restart
Additional info:
ClusterVersion: Stable at "4.12.2" ClusterOperators: clusteroperator/insights is not available (Unable to report: unable to build request to connect to Insights server: Post "https://console.redhat.com/api/ingress/v1/upload": dial tcp [2600:1407:e800:8::17c6:60e]:443: connect: netwo rk is unreachable) because Unable to report: unable to build request to connect to Insights server: Post "https://console.redhat.com/api/ingress/v1/upload": dial tcp [2600:1407:e800:8::17c6:60e]:443: connect: network is unreachable clusteroperator/kube-controller-manager is degraded because GarbageCollectorDegraded: error fetching rules: Get "https://thanos-querier.openshift-monitoring.svc:9091/api/v1/rules": dial tcp [fd02::2a03]:9091: connect: connection r efused clusteroperator/monitoring is not available (reconciling Thanos Querier Deployment failed: updating Deployment object failed: waiting for DeploymentRollout of openshift-monitoring/thanos-querier: got 1 unavailable replicas) becaus e reconciling Thanos Querier Deployment failed: updating Deployment object failed: waiting for DeploymentRollout of openshift-monitoring/thanos-querier: got 1 unavailable replicas clusteroperator/openshift-controller-manager is not available (Available: no openshift controller manager daemon pods available on any node.) because All is well