-
Bug
-
Resolution: Unresolved
-
 Normal
Normal
-
OADP 1.3.0
-
Quality / Stability / Reliability
-
None
-
4
-
False
-
-
False
-
ToDo
-
Important
-
2
-
Very Likely
-
0
-
8
-
Unset
-
Unknown
-
No
Description of problem:
Version-Release number of selected component (if applicable): OADP 1.3
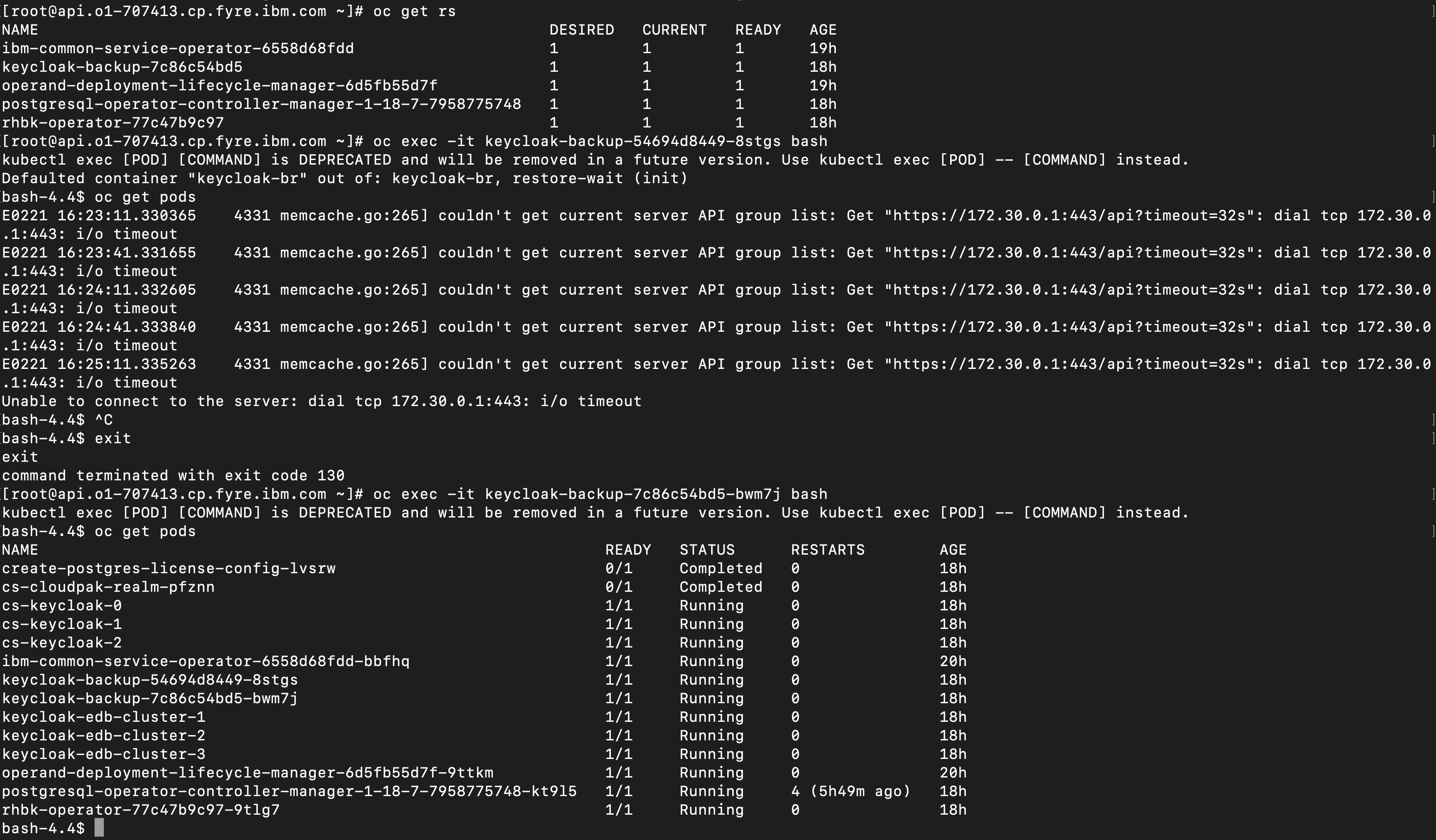
How reproducible: Intermittently, but if it happens once on a cluster I can't workaround it.
Steps to Reproduce:
1. Backup pod with PVC and restore post hooks
2. Run restore
3. Restore "Completes" but the post hook fails with error code 1 and the pasted error below
Actual results:
time="2024-02-02T17:43:26Z" level=info msg="stdout: [INFO] Mode is set to restore, beginning restore process.\n" hookCommand="[sh -c /keycloak/br_keycloak.sh restore int-oadp int-oadp]" hookContainer=keycloak-br hookName="<from-annotation>" hookOnError=Fail hookPhase=post hookSource=annotation hookTimeout="{5m0s}" hookType=exec logSource="/remote-source/velero/app/pkg/podexec/pod_command_executor.go:173" pod=int-oadp/keycloak-backup-7cd87fb7f4-gwzkz restore=openshift-adp/ben-investigation-1time="2024-02-02T17:43:26Z" level=info msg="stderr: E0202 17:40:26.823349 13 memcache.go:238] couldn't get current server API group list: Get \"https://172.30.0.1:443/api?timeout=32s\": dial tcp 172.30.0.1:443: i/o timeout\nE0202 17:40:56.824932 13 memcache.go:238] couldn't get current server API group list: Get \"https://172.30.0.1:443/api?timeout=32s\": dial tcp 172.30.0.1:443: i/o timeout\nE0202 17:41:26.826748 13 memcache.go:238] couldn't get current server API group list: Get \"https://172.30.0.1:443/api?timeout=32s\": dial tcp 172.30.0.1:443: i/o timeout\nE0202 17:41:56.827363 13 memcache.go:238] couldn't get current server API group list: Get \"https://172.30.0.1:443/api?timeout=32s\": dial tcp 172.30.0.1:443: i/o timeout\nE0202 17:42:26.828493 13 memcache.go:238] couldn't get current server API group list: Get \"https://172.30.0.1:443/api?timeout=32s\": dial tcp 172.30.0.1:443: i/o timeout\nE0202 17:42:56.829524 13 memcache.go:238] couldn't get current server API group list: Get \"https://172.30.0.1:443/api?timeout=32s\": dial tcp 172.30.0.1:443: i/o timeout\nE0202 17:43:26.831342 13 memcache.go:238] couldn't get current server API group list: Get \"https://172.30.0.1:443/api?timeout=32s\": dial tcp 172.30.0.1:443: i/o timeout\nUnable to connect to the server: dial tcp 172.30.0.1:443: i/o timeout\n" hookCommand="[sh -c /keycloak/br_keycloak.sh restore int-oadp int-oadp]" hookContainer=keycloak-br hookName="<from-annotation>" hookOnError=Fail hookPhase=post hookSource=annotation hookTimeout="{5m0s}" hookType=exec logSource="/remote-source/velero/app/pkg/podexec/pod_command_executor.go:174" pod=int-oadp/keycloak-backup-7cd87fb7f4-gwzkz restore=openshift-adp/ben-investigation-1time="2024-02-02T17:43:26Z" level=error msg="Error executing hook" error="command terminated with exit code 1" hookPhase=post hookSource=annotation hookType=exec logSource="/remote-source/velero/app/internal/hook/wait_exec_hook_handler.go:173" pod=int-oadp/keycloak-backup-7cd87fb7f4-gwzkz restore=openshift-adp/ben-investigation-1
On top of the above message, the PVC is not restored for the pod where this post hook is trying to run.
Expected results: Successfully executed restore post hook or at least a failed restore instead of a "completed"
Additional info:
This example is running a script that runs a simple pg_restore command on an existing keycloak edb pod, but the keycloak-backup pod is completely cut off from the kube api. Restarting the keycloak-backup pod lets me connect to the kube api but the pvc is not restored so the pg_restore command does not work. I have noticed that the only difference in pod definition when restarting the pod is the removal of the restic init container which I suspect to be involved somehow. I have also found that once this issue is hit on a cluster, no amount of deleting and recreating the restored resources and the restore objects will change the outcome. Once I hit this issue, I always hit this issue and it prevents restore of this resource on this cluster.
We implement a similar restore strategy for a couple components (like our mongo database using mongorestore instead) and I have seen this intermittently when restoring those components as well. I have seen this error using both OADP 1.1 and OADP 1.3. It is difficult to intentionally recreate.