-
Bug
-
Resolution: Done
-
 Major
Major
-
netobserv-1.3, netobserv-1.2
-
Quality / Stability / Reliability
-
False
-
-
None
-
Important
-
None
-
None
-
None
-
None
-
None
-
None
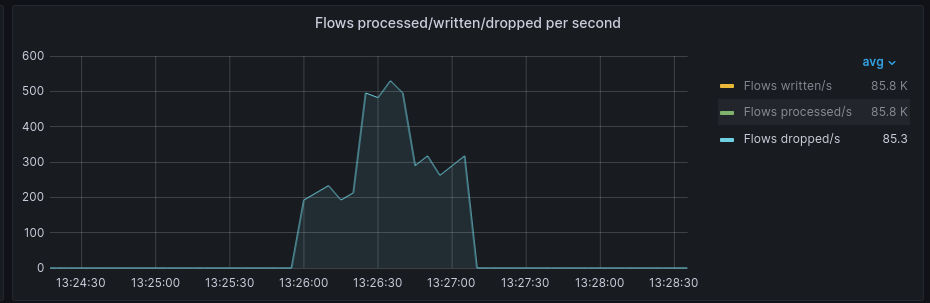
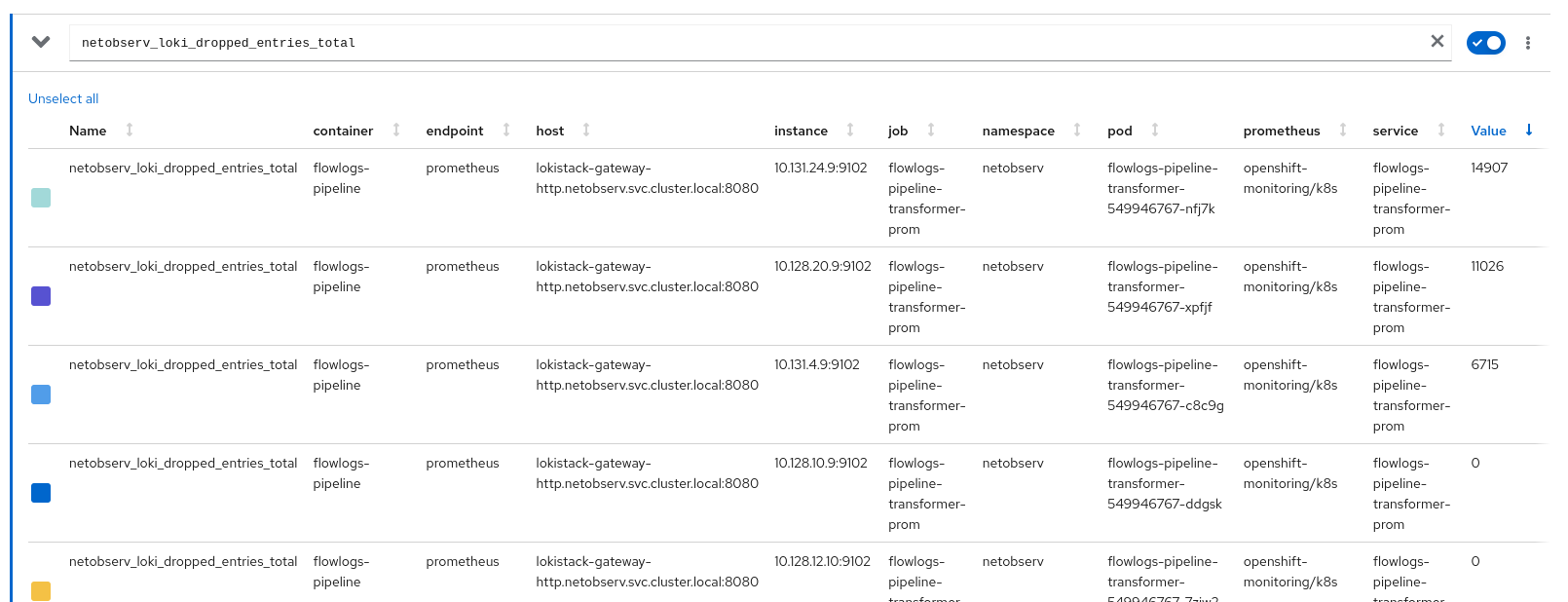
In recent NetObserv 1.2 performance testing, we have witnessed the following behavior:
During spikes of load, certain eBPF pods will be OOMKilled and go into CrashLoopBackOff state. Notably these have been observed to be the same pods co-located on nodes with LokiStack resources, which have high memory usageThis behavior was observed with both small and medium sized LokiStacks as well as the default eBPF memory limit of 800Mi as well as an increased limit of 1000Mi
- Flows continue to be processed but some are dropped during these spike periods.
The operator recovers after the load spikes end with eBPF pods recovering and flows returning to being written.
Opening this bug to track the behavior and gather more data.
Discussions relating to this bug:

- relates to
-
NETOBSERV-717 Loki per_stream_rate_limit
-

- Closed
-
- split from
-
-
- Closed
-
-
-
- Closed
-
- links to
-
 RHSA-2023:116729
Network Observability 1.4.0 for OpenShift
RHSA-2023:116729
Network Observability 1.4.0 for OpenShift
(1 links to)