-
Bug
-
Resolution: Done
-
 Major
Major
-
None
-
None
-
Quality / Stability / Reliability
-
False
-
-
None
-
Important
-
None
-
None
-
NetObserv - Sprint 229
-
None
-
None
-
None
Ran Test Bed 3 with node-density-heavy using the the following modifications to the Loki limits
limits:
global:
ingestion:
ingestionBurstSize: 100
ingestionRate: 500
maxGlobalStreamsPerTenant: 50000
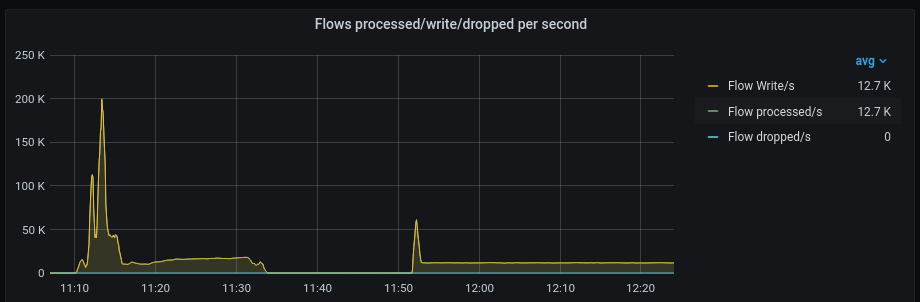
Flows did process initially, but after about 25 minutes the NO Controller and Kafka Zookeeper pods began failing

NO Controller had the following event occur multiple times - my suspicion is this is due to exceeding Pod memory limits as rhn-support-memodi previously observed in a different cluster

Kafka Zookeeper pods began failing shortly after NO Controller, but I am not sure as to why - I did see the following error when inspecting the Zookeeper pods:
Warning Unhealthy 58m kubelet Readiness probe errored: rpc error: code = NotFound desc = container is not created or running: checking if PID of e12b296239a1f3cf92903744ef2ea01b0a94e2b9237def6faccb52fe856ca0e7 is running failed: container process not found
As you can see in the above chart, I canceled the workload and eventually all Zookeeper pods recovered and flows began processing again - however NO Controller remains unstable.

- is caused by
-
NETOBSERV-525 Gather performance data with Kafka
-

- Closed
-
- is related to
-
NETOBSERV-547 (documentation effort) Tweak loki config
-
- Closed
-
-
-
- Closed
-
- links to
- mentioned on