-
Bug
-
Resolution: Not a Bug
-
 Normal
Normal
-
None
-
None
-
Quality / Stability / Reliability
-
False
-
-
None
-
None
-
None
-
None
-
NetObserv - Sprint 228, NetObserv - Sprint 229, NetObserv - Sprint 230
-
QE Confirmed
-
None
-
None
-
None
Currently we don't have any kafka log retention/clean up values and we hit an issue where PV sizes are reached to crash Kafka cluster pod. Based on reading strimzi docs: https://strimzi.io/docs/operators/latest/full/configuring.html#managing_logs_with_data_retention_policies , I came up with below values but need to test e2e with it:
log.cleaner.backoff.ms: 15000 log.cleaner.dedupe.buffer.size: 134217728 log.cleaner.enable: true log.cleaner.io.buffer.load.factor: 0.9 log.cleaner.threads: 8 log.cleanup.policy: compact,delete log.retention.check.interval.ms: 300000 log.retention.ms: 1680000 log.roll.ms: 259200000 log.segment.bytes: 1073741824
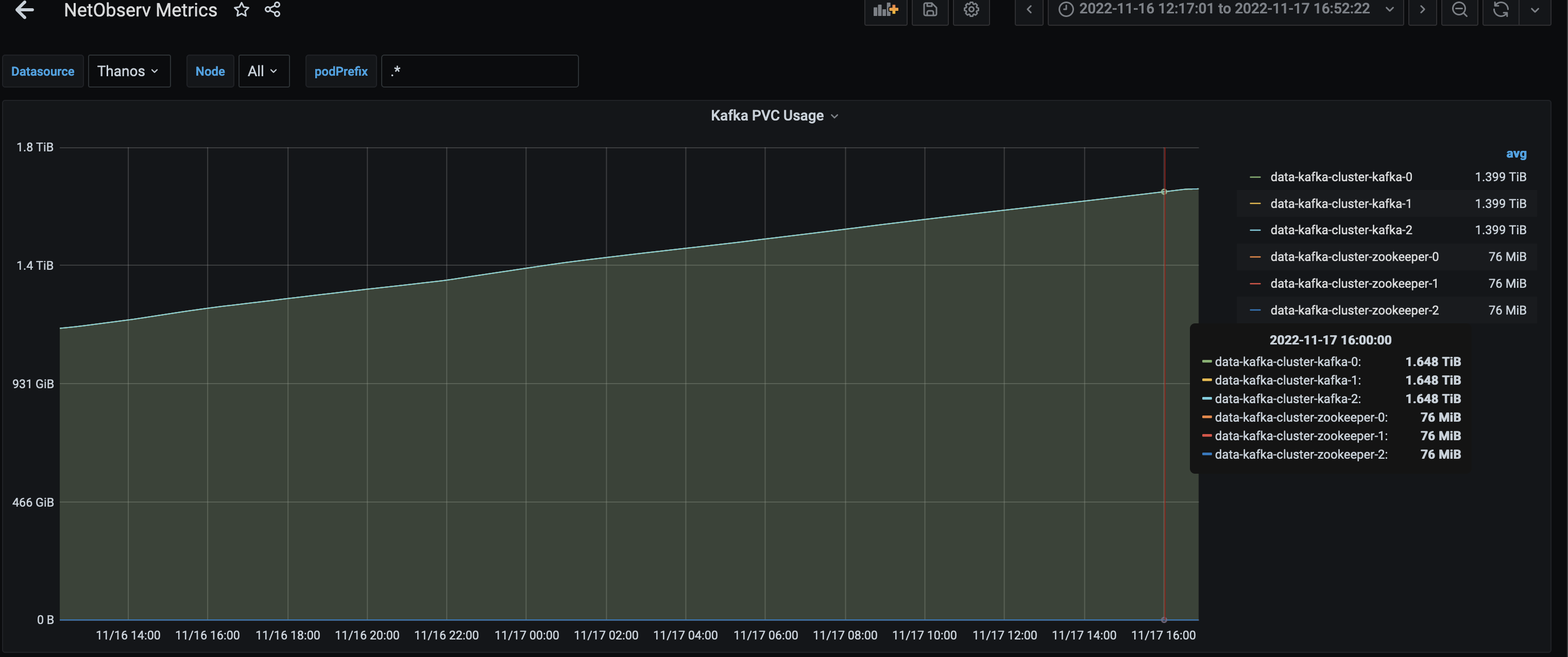
- is caused by
-
NETOBSERV-483 Do performance testing for large cluster
-
- Closed
-
- links to