-
Bug
-
Resolution: Done
-
 Major
Major
-
None
-
openshift-4.12
-
None
-
Quality / Stability / Reliability
-
False
-
-
3
-
Critical
-
None
-
NetObserv - Sprint 225, NetObserv - Sprint 226, NetObserv - Sprint 227
-
Customer Facing
-
None
-
None
-
None
With latest (quay.io/netobserv/netobserv-ebpf-agent:main as of 30-Sept) ebpf agent , observing that memory growth is unbounded under periodic load with idle periods.
- flowcollector sampling parameter is 100 (problem happens even faster with lower values)
- workload is a k6 (k6.io) pod simulating 100 users sending 25K http requests/second to 5 services running in OpenShift. The ebpf pod where memory is being monitored is on the node where the requests originate, not the service nodes
- Workload is run for 10 minute intervals with 5 minute rest periods
The graph of pod rss memory usage is attached. If the test is left to run the pod will be OOMKilled when the pod memory limit is reached, or when system memory is exhausted if the memory limit is removed. On a 16G system, the pod is OOMKilled when it uses ~14GB.
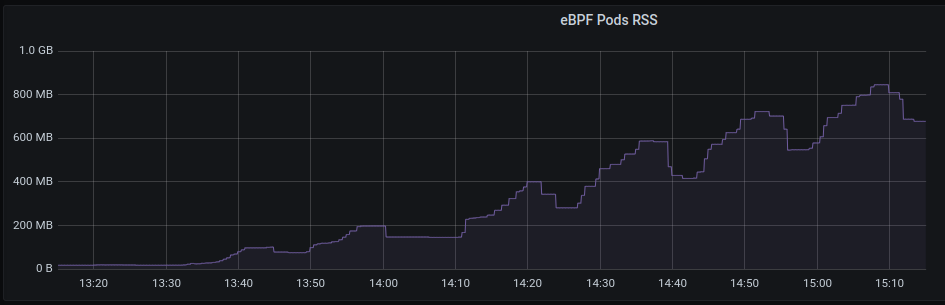


{kind=link}
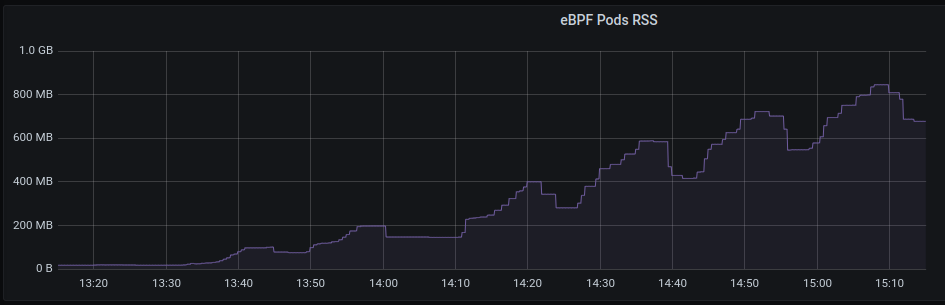{kind=link}