-
Sub-task
-
Resolution: Done
-
 Normal
Normal
-
None
-
None
-
None
-
None
-
False
-
-
False
-
None
-
None
-
None
-
None
-
NetObserv - Sprint 223, NetObserv - Sprint 224, NetObserv - Sprint 225, NetObserv - Sprint 226, NetObserv - Sprint 227, NetObserv - Sprint 228, NetObserv - Sprint 229
Performance data needs to be gathered with Kafka with below workloads:
- node-density-heavy (base variable on worker nodes)
- cluster-density (base variable on worker nodes)
- router-perf (default settings)
Below environments we should gather data for:
- Test Beds 1 and 2 share the following configuration (see attached doc for Test Bed 3)
- OCP Version: 4.12
- Cloud: AWS
- Machine Type: m5.4xlarge
- Netobserv Installation Source: Source (latest code on main branch)
- Loki Stack: 1x.medium
- Kafka Settings: # replicas = 2 * FLP replicas
- Environments
- Test Bed 1
- 9 worker nodes
- Sampling 1
- FLP CPU Limit 2 cores
- FLP Mem Limit 1 GB
- Kafka partitions 10
- Kafka replica 5
- Test Bed 2
- 50 worker nodes
- Sampling 1
- FLP CPU Limit 4 cores
- FLP Mem Limit 4 GB
- Kafka partitions 24
- Kafka replica 12
- Test Bed 3
- See attached document
- Test Bed 1
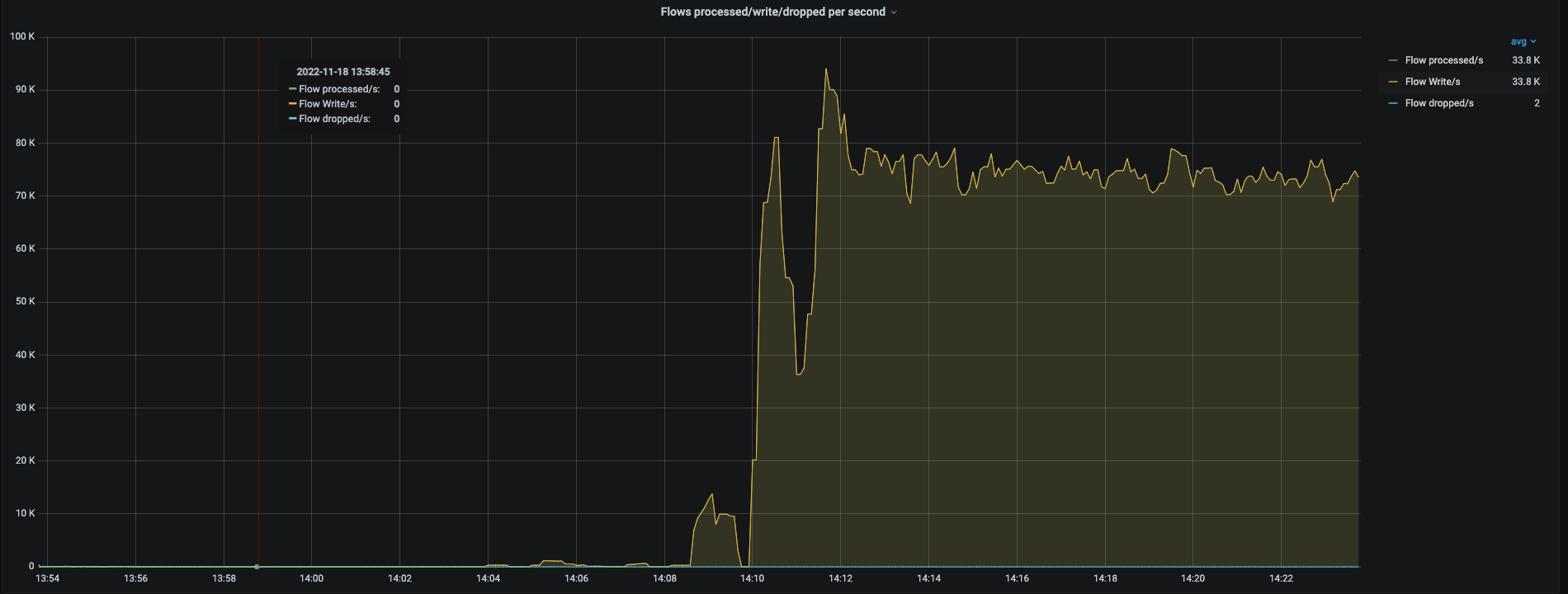{kind=link}
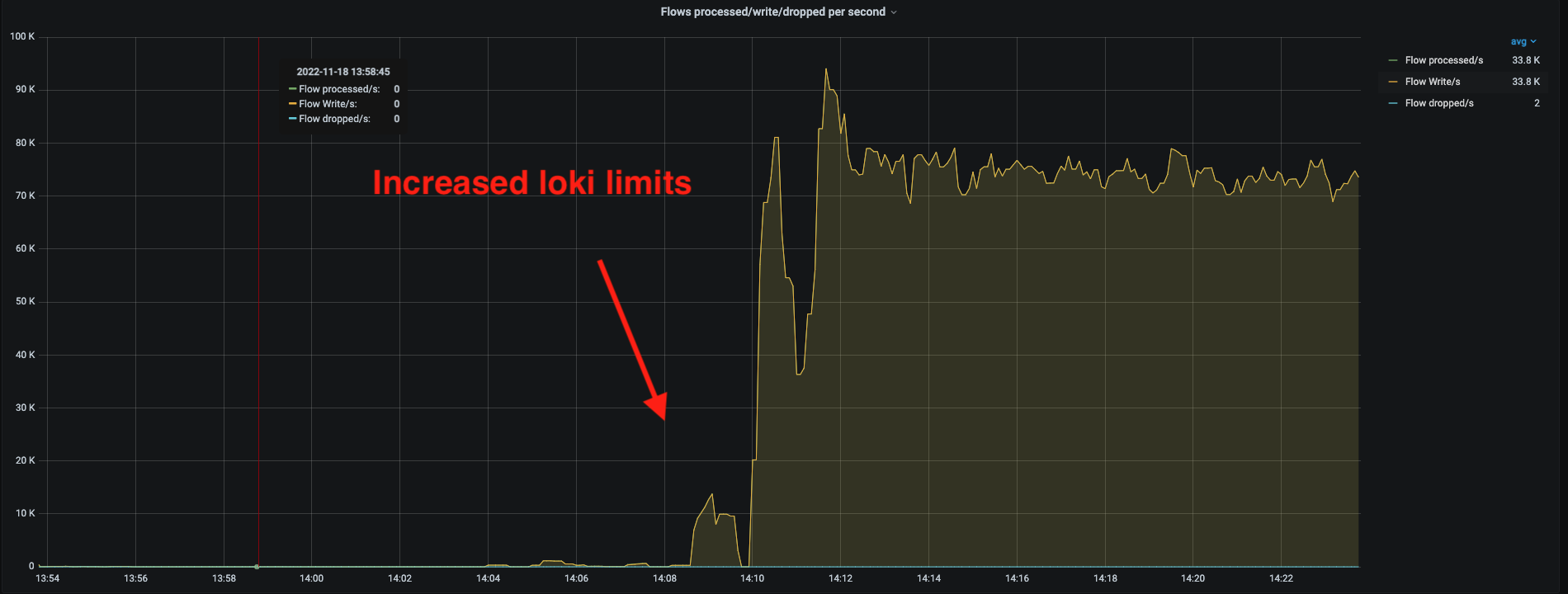{kind=link}
{kind=link}
{kind=link}
- causes
-
NETOBSERV-730 NO Controller and Kafka pods crashing in large-scale deployment
-

- Closed
-
- is related to
-
NETOBSERV-547 (documentation effort) Tweak loki config
-
- Closed
-
-
-
- Closed
-
- links to
(1 links to)