-
Bug
-
Resolution: Obsolete
-
 Critical
Critical
-
None
-
None
-
None
-
Quality / Stability / Reliability
-
False
-
-
None
-
None
-
None
-
None
-
NetObserv - Sprint 220, NetObserv - Sprint 222, NetObserv - Sprint 223, NetObserv - Sprint 224, NetObserv - Sprint 225
-
None
-
None
-
None
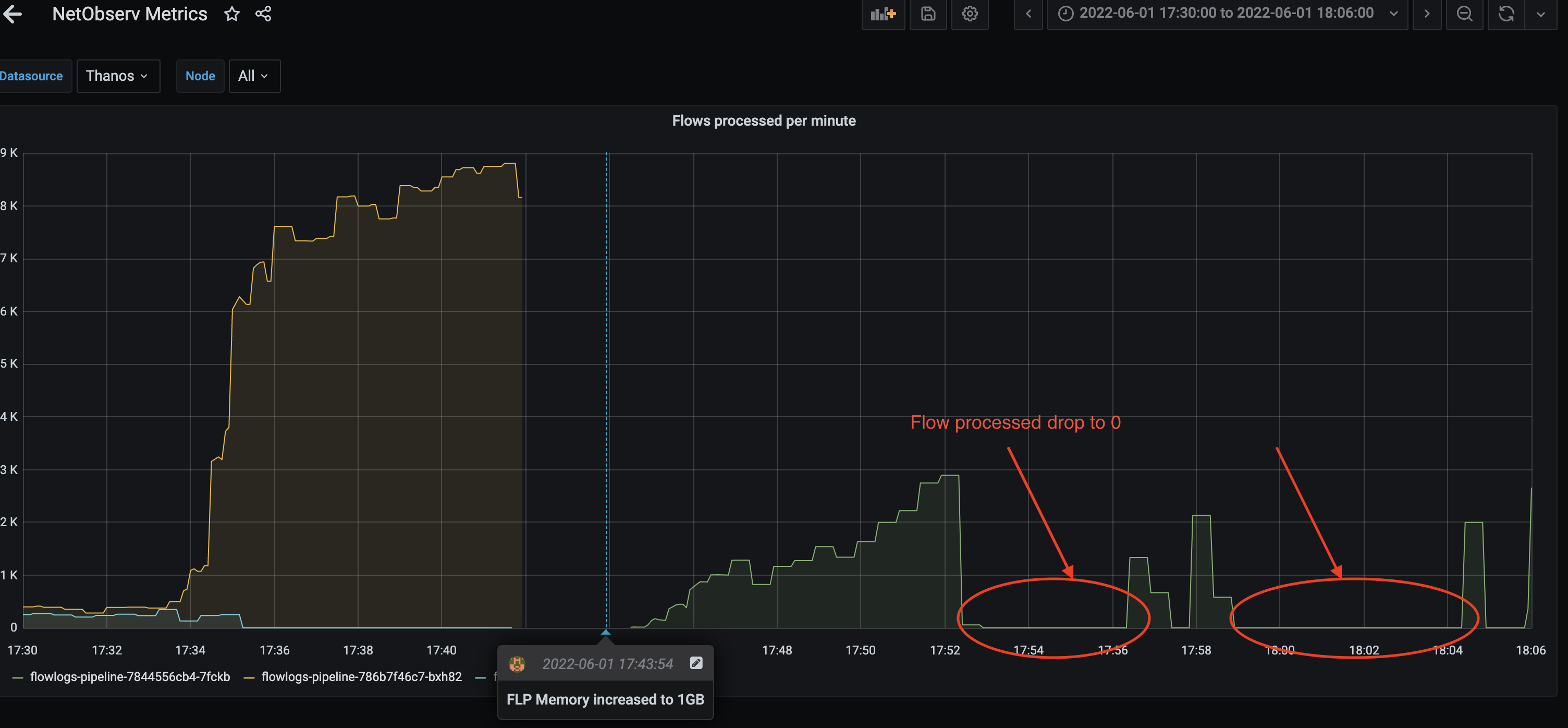
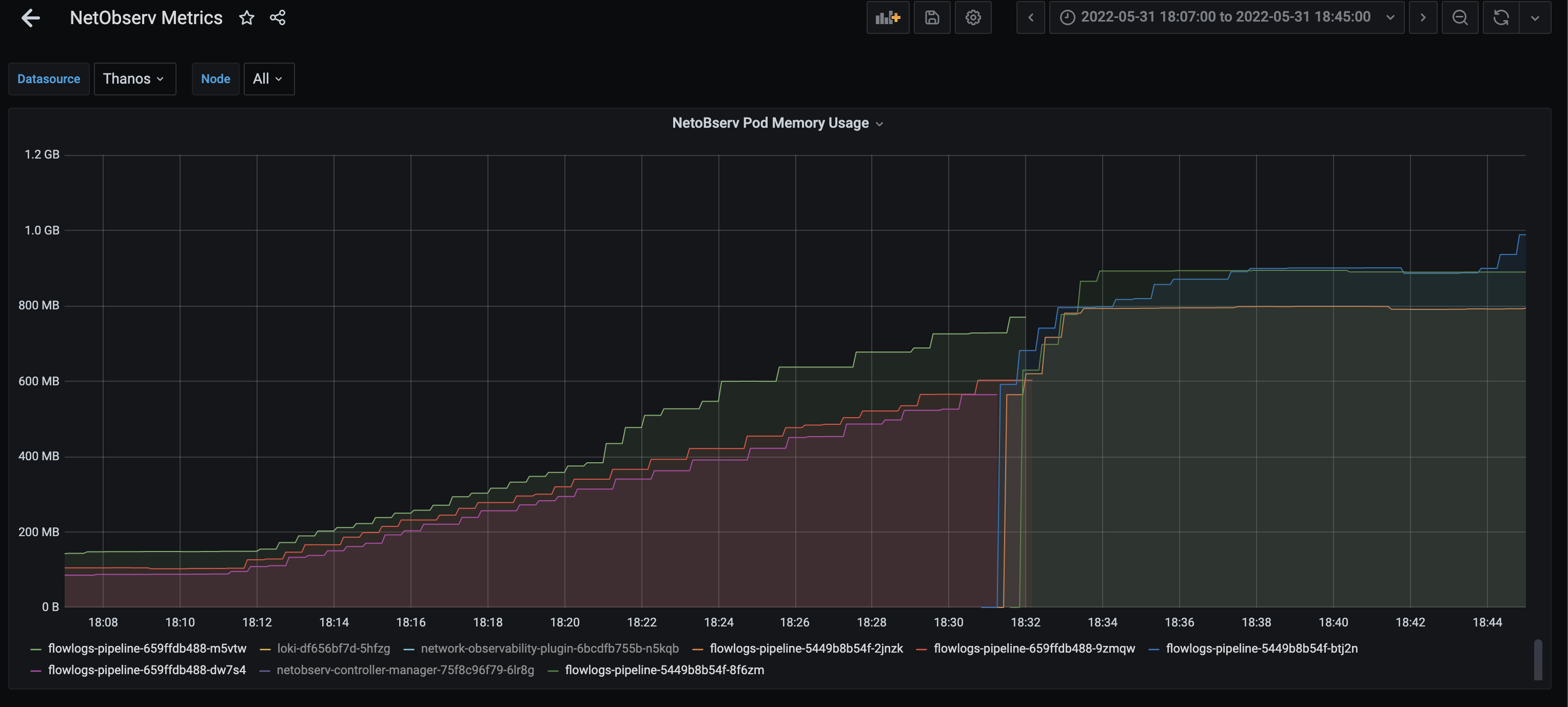
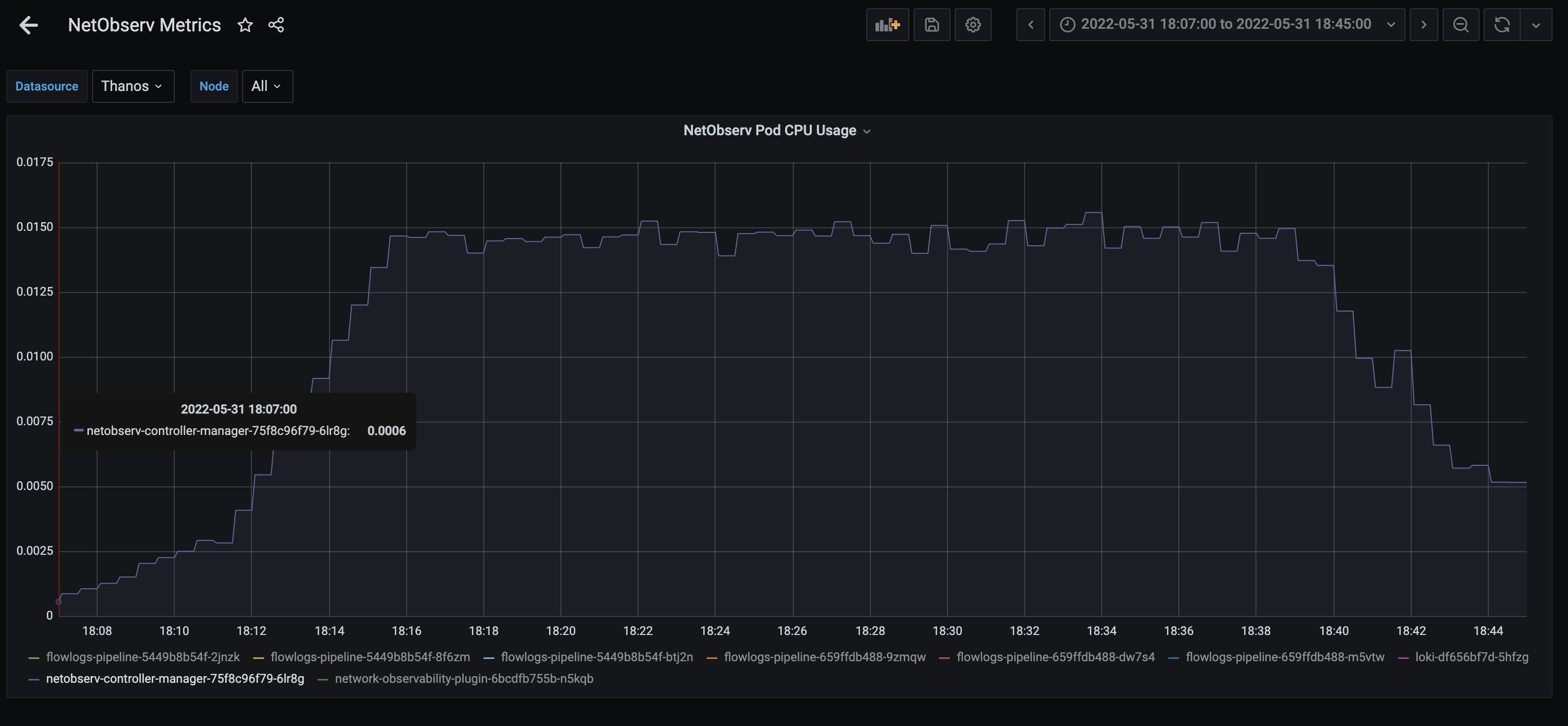
NOO and FLP deployments has default limits associated limits for CPU (NOO only) and memory. For performance test with 45 nodes and 1000 Job Iterations of cluster-density workload, we ran into issue NOO and FLP pods went into CrashLoopBackOff due to OOMKilled.
$ oc get pods
NAME READY STATUS RESTARTS AGE
flowlogs-pipeline-64cf677d6f-59b7n 0/1 CrashLoopBackOff 9 (3m44s ago) 3d18h
flowlogs-pipeline-64cf677d6f-ltw99 0/1 CrashLoopBackOff 9 (3m46s ago) 3d18h
flowlogs-pipeline-64cf677d6f-sb69x 0/1 CrashLoopBackOff 9 (5m ago) 3d18h
loki-df656bf7d-jcfvv 1/1 Running 0 3d18h
netobserv-controller-manager-7b6f785c48-qk9r2 1/2 CrashLoopBackOff 8 (105s ago) 3d18h
network-observability-plugin-6bcdfb755b-n5kqb 1/1 Running 0 3d18h
$ oc describe pod/flowlogs-pipeline-64cf677d6f-59b7n | grep -i reason
Reason: CrashLoopBackOff
Reason: OOMKilled
Type Reason Age From Message
For production state, it makes sense to remove the limits because without knowing customer use case, these limits are probably a guess and doesn't fit all cases.

- is related to
-
NETOBSERV-435 Set default req/limits resources for eBPF agent
-
- Closed
-