-
Bug
-
Resolution: Done
-
 Major
Major
-
netobserv-1.5, netobserv-1.6, netobserv-1.7
-
None
-
Quality / Stability / Reliability
-
False
-
-
None
-
None
-
None
-
None
-
NetObserv - Sprint 261, NetObserv - Sprint 262
-
None
-
None
-
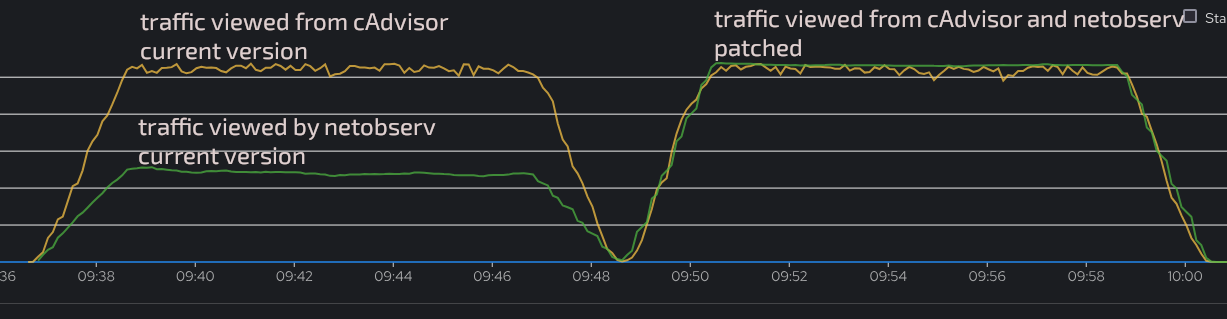
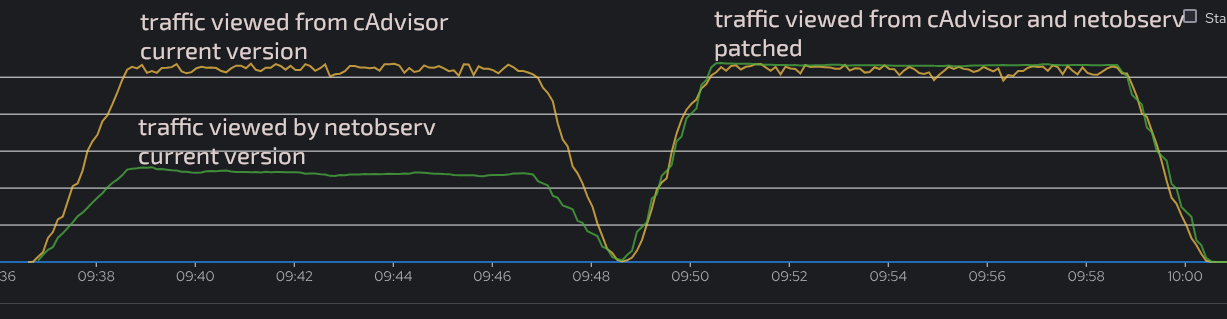
Previously, under high stress, some flows generated by the eBPF agent were mistakenly dismissed, resulting in traffic bandwidth under-estimation. Those generated flows are not dismissed anymore.
Under stress, the agent provides much lower pictures of the workload throughput than what cadvisor metrics provide.
While there can be different reasons for that (dropped flows, deduplication, ...) I found a case that actually looks like a bug in the agent code: https://github.com/netobserv/netobserv-ebpf-agent/blob/main/pkg/flow/tracer_map.go#L149-L154
Flows are ignored on purpose based on a past eviction timestamp. But this logic is flawed because flows lookup from map isn't batched or atomic. Each flow is read+deleted one by one. So they should have each their own last eviction timestamp, whereas using a single timestamp like today ends up eliminating too many flows.
I'm also questioning if the assertion "eBPF hashmap values are not zeroed when the entry is removed" is actually true. Maybe we can just remove those lines.
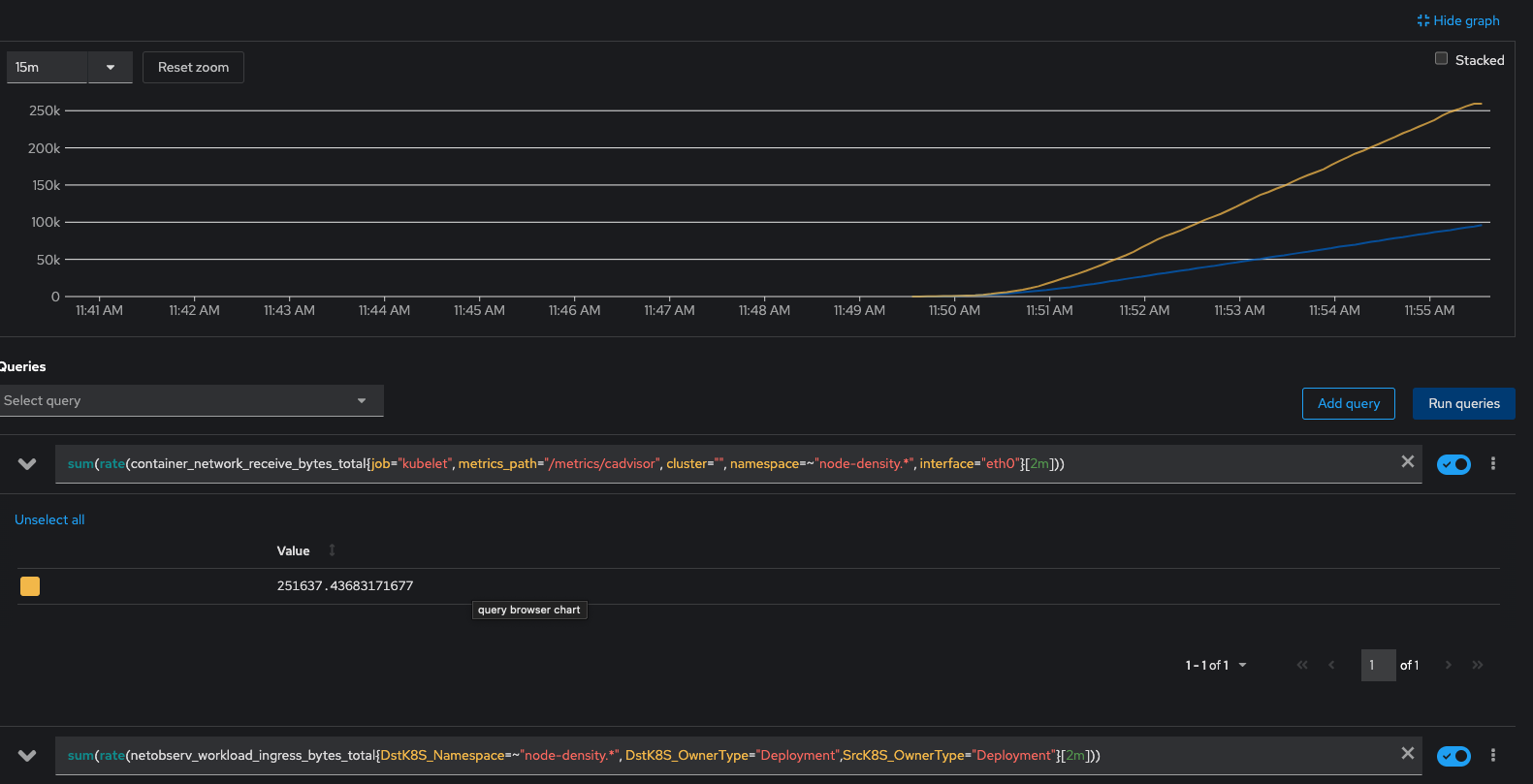
FWIW, testing with hey-ho:
./hey-ho.sh -r 3 -d 3 -z 10m -n 2 -q 50 -p -b -y
and comparing metrics with:
sum(rate(netobserv_workload_ingress_bytes_total{DstK8S_Namespace=~"gallery.*",DstK8S_OwnerType="Deployment",SrcK8S_OwnerType="Deployment"}[2m]))
sum(rate(container_network_receive_bytes_total{job="kubelet", metrics_path="/metrics/cadvisor", cluster="", namespace=~"gallery.+"}[2m]))
when removing these 3 lines, the two metrics finally perfectly align: