-
Bug
-
Resolution: Unresolved
-
 Normal
Normal
-
None
-
2.10.0
Description of problem:
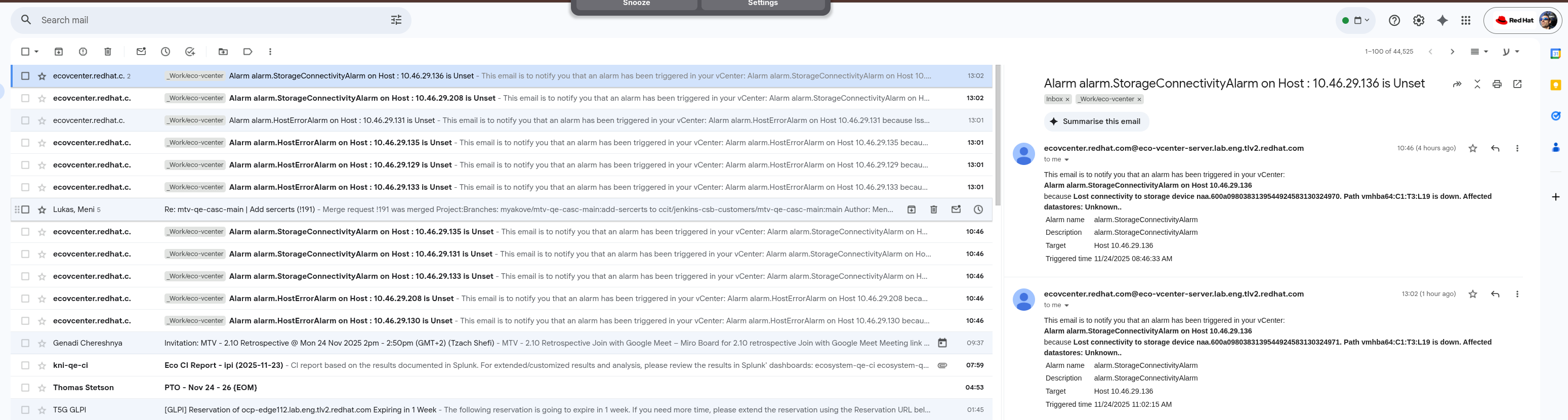
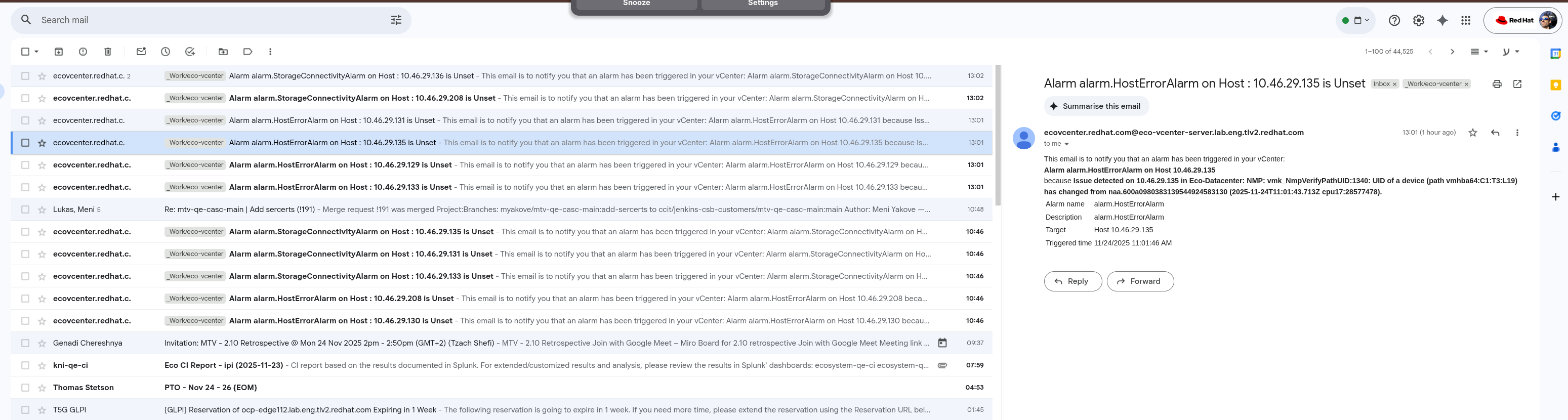
As I manage eco-vcenter, it just so happens that I get about ~10 daily email alerts from the vcenter hosts, granted I still can't say what triggers them but they seem to be related to MTV copy offload migrations. Example email1 ecovcenter.redhat.com@eco-vcenter-server..13:02 (1 hour ago)to me This email is to notify you that an alarm has been triggered in your vCenter: Alarm alarm.StorageConnectivityAlarm on Host 10....136 because Lost connectivity to storage device naa.600a0980383139544924583130324971. Path vmhba64:C1:T3:L19 is down. Affected datastores: Unknown.. Alarm namealarm.StorageConnectivityAlarmDescriptionalarm.StorageConnectivityAlarmTargetHost 10...136 Triggered time11/24/2025 11:02:15 AM Example email2: ecovcenter.... 13:01 (1 hour ago)to meThis email is to notify you that an alarm has been triggered in your vCenter: Alarm alarm.HostErrorAlarm on Host 10....131 because Issue detected on 10...131 in Eco-Datacenter: NMP: vmk_NmpVerifyPathUID:1340: UID of a device (path vmhba64:C1:T3:L19) has changed from naa.600a09803831395449245831303 (2025-11-24T11:01:43.580Z cpu5:46827632). Alarm namealarm.HostErrorAlarmDescriptionalarm.HostErrorAlarmTargetHost 10....131Triggered time11/24/2025 11:01:51 AM
Version-Release number of selected component (if applicable):
MTV 2.10 OCP 4.19
How reproducible:
No idea, usually I notice around ~10 such related email. But again I have no idea (yet) what triggers them.
Steps to Reproduce:
1. Unfortunately I haven't yet managed to pinpoint what triggers these email alert. 2. I assume it's offload MTV migration due to the devices naa names. 3. Very odd I still see this failing during weekend, when I suspect we're not doing any manual offload manual testing, automation isn't yet running.
Actual results:
On a daily basis I get ~10 email related to this.
Expected results:
Well I hope we're not doing something which is causing these kind of alerts.
Additional info:
I'll try to triage this better see if I find anything useful on esxi host logs.