-
Story
-
Resolution: Unresolved
-
 Major
Major
-
None
-
None
-
None
-
None
-
Associate Wellness & Development
-
False
-
-
False
-
NEW
-
NEW
-
-
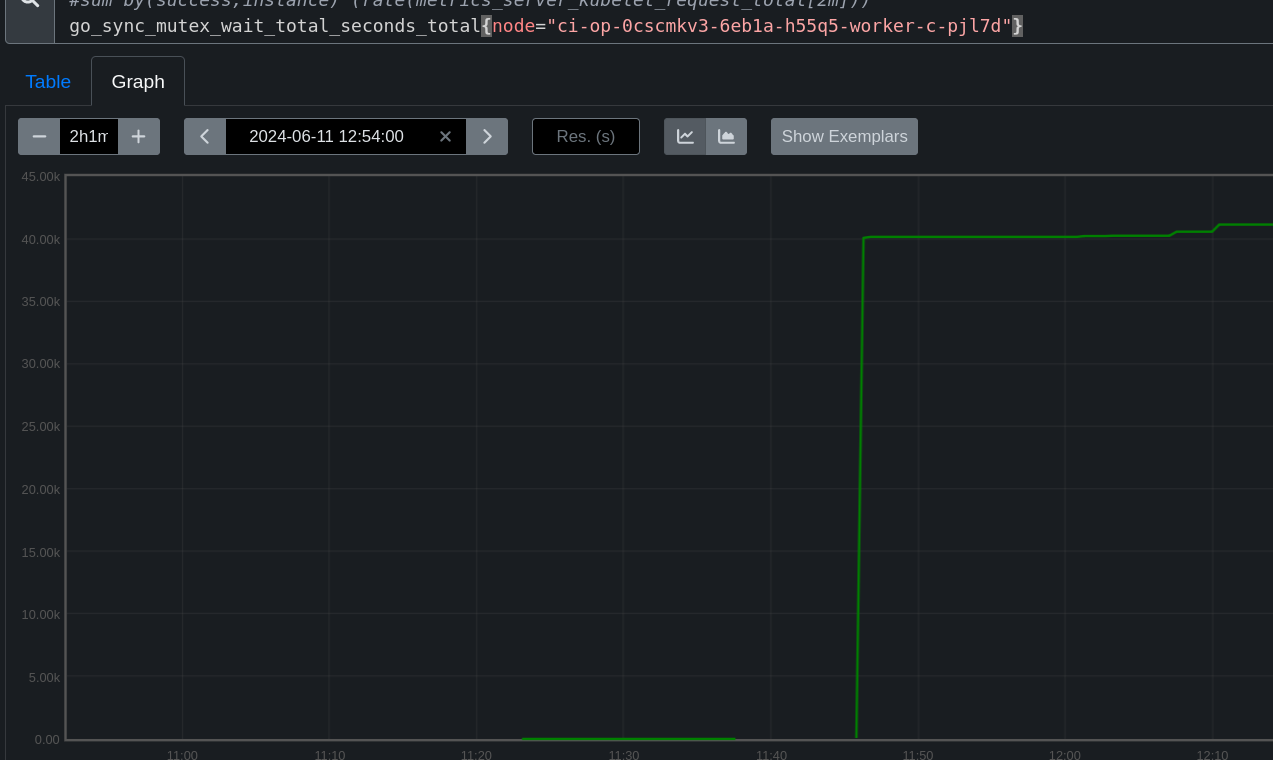
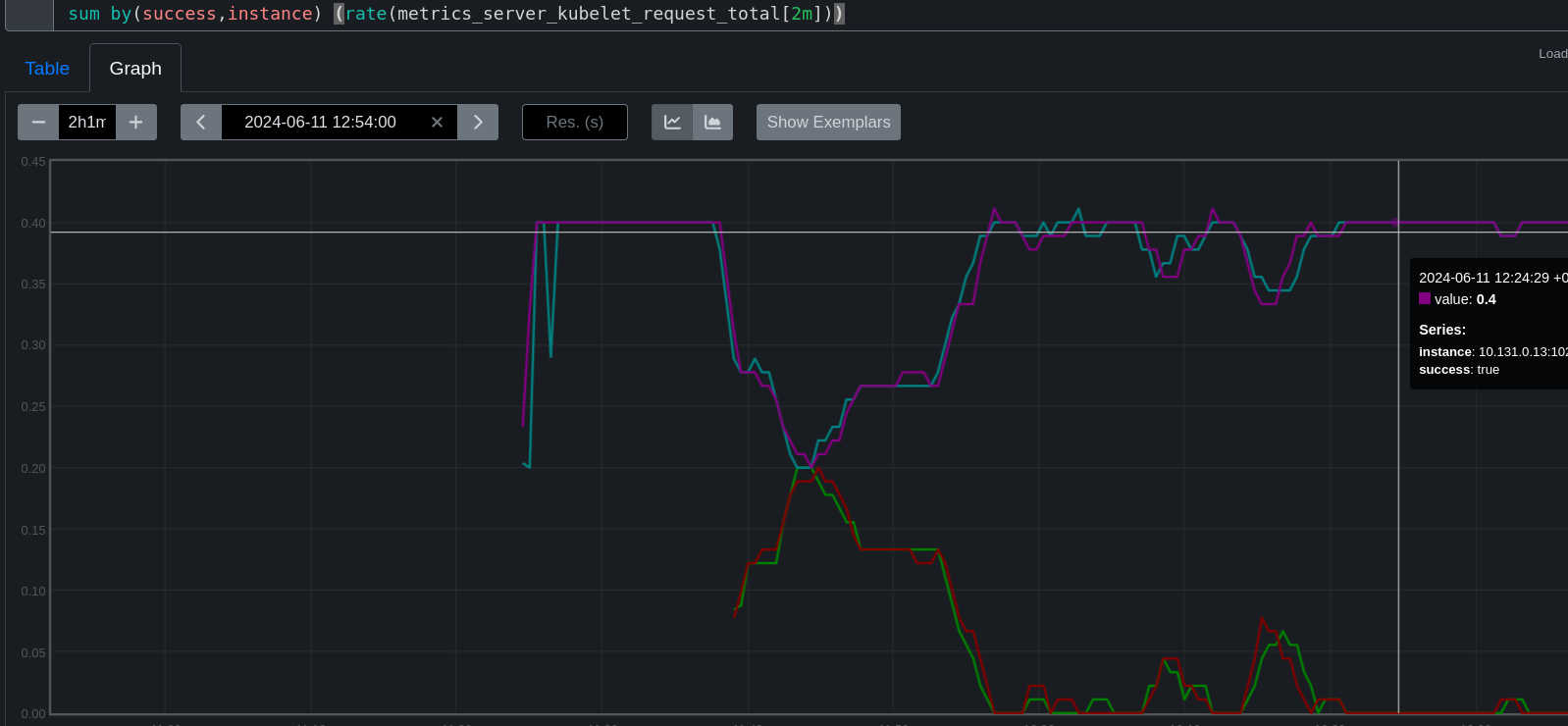
On OCPBUGS-35371 we're having a hard time pinning down exactly why monitoring is flagging TargetDown for the kubelet's /metrics and /metrics/cadvisor endpoints on all nodes, on periodic-ci-openshift-release-master-ci-4.16-e2e-gcp-ovn. The problem doesn't always make it to a firing TargetDown, seems to be around a 5 minute delay before TargetDown kicks in, but using the prom query on a job run such as this one:
max by (node, metrics_path) (up{job="kubelet"}) == 0
For every run I look at here, seems to show all worker nodes having a lengthy outage to these endpoints even if it doesn't last long enough to fire TargetDown, it's still several minutes. (use debug tools > promeceius)
Would it be possible to get visibility into what errors are coming back while scraping? Trevor points out one idea here, logging would be another option.
Complicating factor, we need this in 4.16, we cannot reproduce in 4.17 yet.
- relates to
-
OCPBUGS-35371 Kubelet metrics endpoints experiencing prolonged outages
-
- Closed
-
