-
Bug
-
Resolution: Done
-
 Normal
Normal
-
None
-
None
-
None
-
False
-
-
False
-
NEW
-
NEW
-
Bug Fix
-
-
Description of problem:
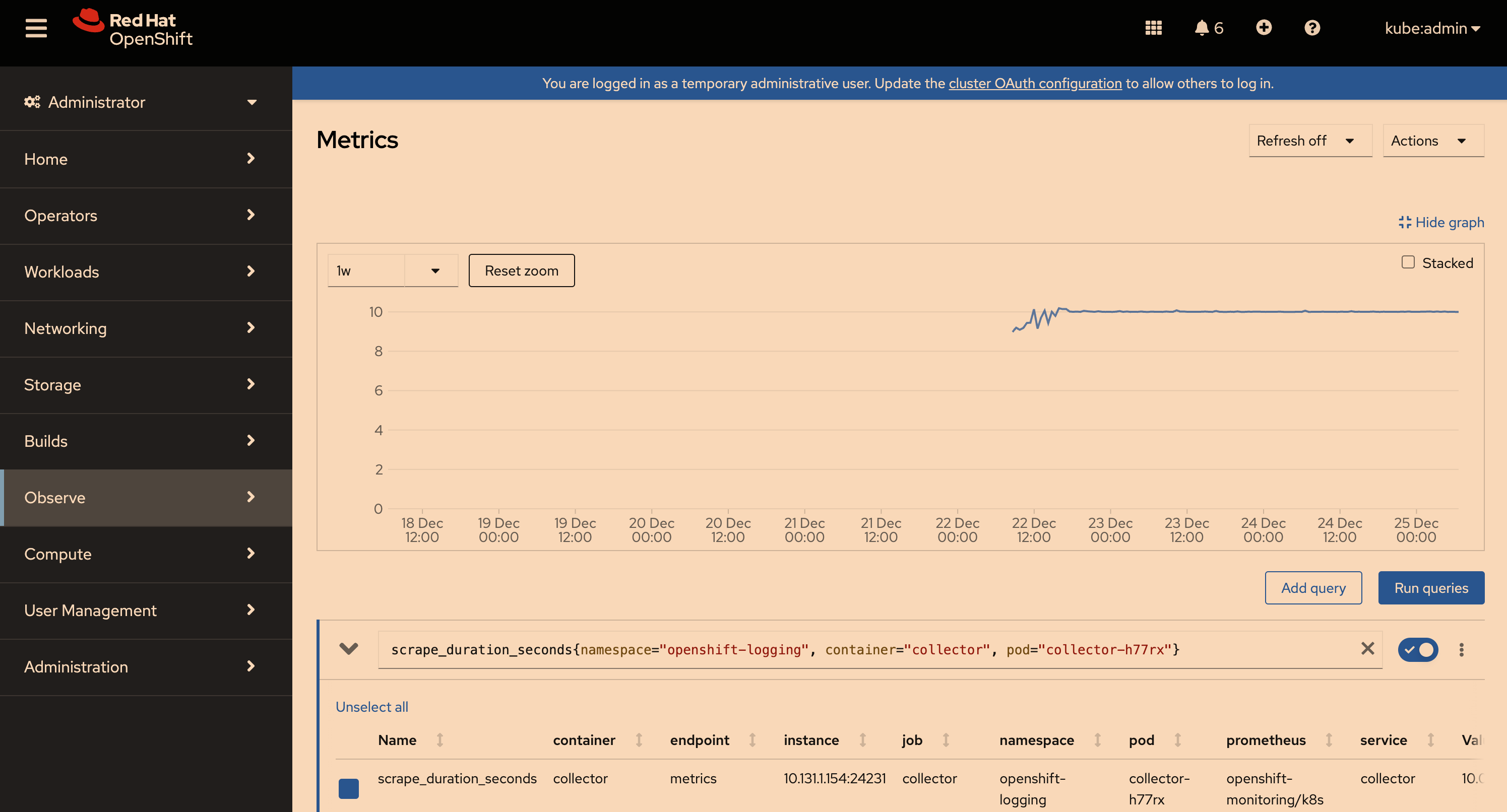
+ The amount of metrics information (mainly "log_collected_bytes_total") published by the collector pods on the nodes gradually increases.
+ scrape_duration_seconds for collector fluentd goes up to 10 sec triggers FluentdNodeDown alert.
Version-Release number of selected component (if applicable):
+ Cluster logging 5.5.16, 5.7, 5.8
How reproducible:
+ At both customers and Red Hat test bench
Steps to Reproduce:
<will share it in the comment below>
====